
L’architecture Serverless, une approche disruptive aux problématiques Big Data : l’exemple d’Adways

Aujourd’hui basée à Paris, Lyon, New York… la start-up Adways a très rapidement franchi les limites de l’hexagone. Partant du constat que tous les supports (mobile, tablette, desktop) sont interactifs et que les vidéos ne le sont pas, Adways propose un outil SaaS permettant à l’utilisateur d’éditer ses vidéos en y ajoutant des hotspots associés à une fonction : une fiche produit, une vidéo dans la vidéo…les possibilités sont nombreuses, et avec un impact très fort sur l’engagement et la monétisation, le succès est au rendez-vous.
(Image ci-dessus : Vidéo interactive « Refaites l’histoire de l’US Open« )
Avec le déploiement de la solution en France et à l’étranger, le volume de trafic explose : dans le cas des projets publicitaires, il peut y avoir jusqu’à 650 millions de requêtes. Et derrière, autant de statistiques à collecter sur chacune des interactions de l’internaute. En publicité, la statistique est un élément de facturation, d’où son importance pour Adways. De fait, afin de mieux mesurer et analyser les interactions vidéos, Adways souhaitait évoluer d’une plateforme analytics basique basée sur des compteurs vers une véritable plateforme Big Data. L’objectif était notamment de répondre à la montée en charge du trafic (enjeux de scalabilité), et de doter la plateforme de nouvelles fonctionnalités, comme par exemple pouvoir requêter tous les événements passés et non seulement des compteurs.
Une plateforme Analytics avec une facturation à l’usage
La nouvelle plateforme devait répondre à de multiples objectifs. D’un point de vue fonctionnel, il s’agissait de collecter plus d’informations, sur un plus grand volume de données, et de fournir un reporting proche du temps réel, au plus tard quelques minutes après chaque événement. Cette plateforme devait également s’adapter aux contraintes d’une start-up : il fallait une solution simple à développer et à maintenir, peu onéreuse et surtout scalable, et utilisant autant de services managés que possible. Ceci afin de laisser l’équipe se concentrer sur son métier plutôt que de gérer des clusters de machines et des patchs d’OS, mais également optimiser les coûts :

Audric Guigon, Adways
“Nous voulions être le plus proche possible d’une facturation à la requête, et les solutions existantes sur le marché pour faire de la collecte de données étaient hors de prix (Adobe Catalyst, Analytics Premium…). Nous avions l’idée d’évoluer vers une solution Cloud, et notamment Redshift, mais nous avions besoin d’être guidés et confirmés dans nos choix. Sur Redshift par exemple, nous avions vraiment besoin d’être formés”, nous explique Audric Guigon, Ingénieur R&D chez Adways.
Dans un premier temps la réflexion a porté sur l’architecture du pipeline de données. Comment transporter ces données ? Comment les traiter ? Comment les requêter ? Le volume de données d’Adways étant en forte croissance, la solution devait répondre à un multiplication du volume par 10 ou 20.
Pour le transport de données, le choix s’est porté sur AWS Kinesis Firehose, le Kafka managé d’AWS qui joue le rôle de buffer. Kinesis évite d’avoir un cluster à configurer et à opérer, laissant juste la configuration à gérer.
AWS Lambda, une approche disruptive aux problématiques Big Data
Pour le traitement des données nous avons fait appel aux fonctions managées AWS avec un enchaînement de fonctions Lambda qui nettoient, enrichissent et formatent les événements. Cette solution contraste avec les approches classique du traitement Big Data en streaming, qui consistent à utiliser un framework sur un cluster de machines tel que Storm, Flink ou Spark Streaming. Bien sûr l’utilisation de Lambda impose des limitations et ne permet pas simplement de faire du traitement de stream stateful complexes. Mais nous avons choisi Lambda en toute connaissance de cause, étant donné que les traitements métiers attendus par Adways étaient simples et que AWS Lambda répondait parfaitement à ce besoin.
D’une manière générale c’est une tendance qui se généralise dans le paysage du Big Data : profiter de la parallélisation de calcul des fonctions as a service plutôt que de passer par une framework de streaming. En effet ces frameworks sont difficiles à appréhender et demande un véritable investissement de temps et de ressources.
Redshift pour le stockage des données
Comment stocker la donnée ? Adways souhaitait pouvoir faire des requêtes ad hoc, sur la grande quantité de données traitée, cela excluait donc de pré-calculer les résultats. Pour que le backend puisse obtenir des réponses rapides aux requêtes, le choix s’est porté sur Amazon Redshift. Non seulement cette base est extrêmement adaptée aux requêtes OLAP (Online Analytical Processing) mais elle est capable de scaler horizontalement (on ajoute des nœuds en fonction des besoins) au contraire de MySQL. Redshift stocke les données par colonnes ce qui diminue la quantité de données lues par requête. Ce choix est particulièrement pertinent pour l’analytics de grandes quantités de données et Redshift permet de requêter sans problème plusieurs centaines de millions d’événements.
Avant de mettre en place la solution nous avons travaillé avec Adways sur les schémas de données. Nous nous sommes alors posé les questions suivantes : Quelles données veut-on logger et exploiter ? Comment les organiser ? De quelles tables a-t-on besoin ? Un schéma en étoile est-il adapté ? Est-ce que le backend requête directement les tables brutes ou bien des tables agrégées plus petites ? Pour ces tables agrégées, quel serait un bon choix de dimensions et de métriques ? Comment connaître le nombre de tables agrégées dont nous avons besoin ?
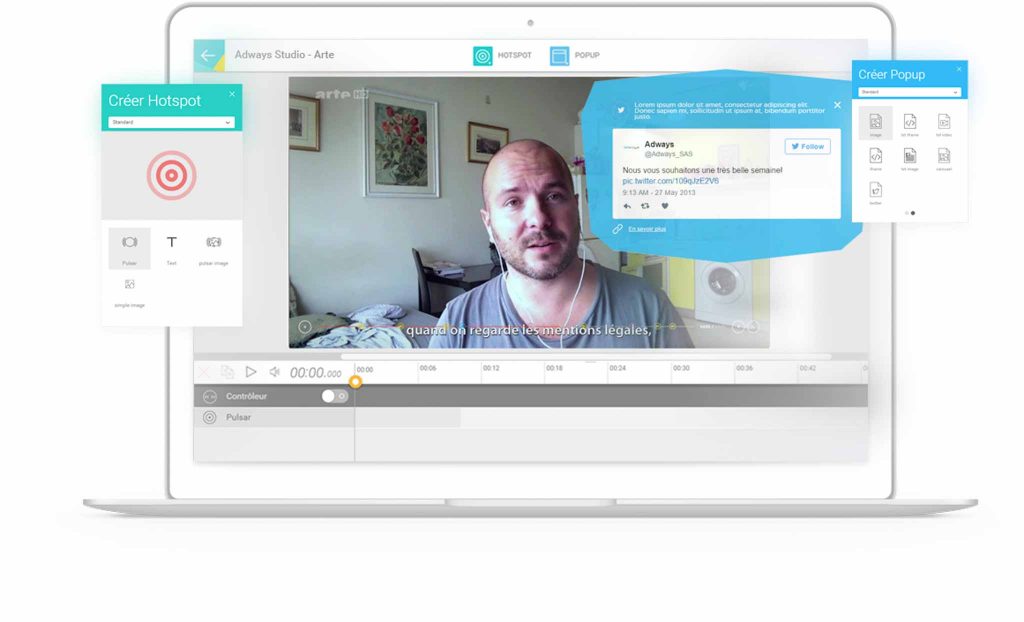
Exemple d’interface d’édition de vidéos Adways
Infrastructure as Code, une étape indispensable
Une fois ces points éclaircis, Adways a pu commencer la réalisation de ce projet. Avant de débuter, nous avons préconisé la mise en place d’une Infra as Code. Nous avons donc accompagné Adways dans l’utilisation de Terraform, afin d’automatiser complètement le déploiement de l’infrastructure plutôt que de la créer manuellement via la console AWS. L’avantage de cette approche étant de disposer d’une infrastructure documentée via le code Terraform, et de pouvoir recréer un environnement ISO à la demande. Audric revient sur cette collaboration : “Nous avons travaillé en peer programming, en étudiant la théorie et la syntaxe avant de monter les différentes briques d’infrastructure nécessaires. Nous avions besoin de conseils sur comment structurer le projet sur Terraform et Nicolas m’a donné une très bonne architecture pour gérer ces différents environnements. N’étant pas administrateur système, j’ai apprécié d’être bien accompagné sur ce sujet. Cependant il n’est pas exclu que dans un avenir proche, nous utilisions CloudFormation pour la partie Infrastructure as Code.”
Une bonne utilisation de Redshift demande une bonne compréhension de son fonctionnement. Même si Redshift abstrait la complexité de la distribution, l’optimisation des performances pour les gros volumes de données demande une bonne connaissance du format des tables, de la compression et de la manière dont Redshift stocke les données sur ses noeuds. Nous avons donc accompagné Adways sur la partie théorique de cet outil et sur les bonnes pratiques d’optimisations. “L’accompagnement de D2SI à la prise en main de nouveaux services a été précieuse. J’avais consulté des pages et des pages de documentation et je n’étais pas plus avancé. J’avais proposé une architecture mais j’avais besoin d’être challengé et conseillé. Sans l’aide D2SI, nous aurions pu faire de grosses erreurs et perdre beaucoup de temps.” nous explique Audric.
De AWS Redshift à AWS Athena
En termes de performances, les résultats étaient très bons. Cependant cette solution échouait sur un point : c’était le seul maillon de la chaîne dont la facturation n’était pas “pay as you go”. En effet, même si Redshift est plus économique qu’une base classique d’analytics, il ne propose pas une facturation proportionnelle au volume de requêtes. Nous avons alors discuté des alternatives possibles à Redshift. BigQuery répondait à l’exigence de paiement à la requête, mais cela impliquait de quitter l’écosystème AWS ou bien d’avoir une solution hybride avec les coûts de transferts de données associés.
Fin novembre 2016, Audric et Clément ont participé à Re:Invent AWS à Las Vegas, où AWS a annoncé l’offre Athena : Athena effectue des requêtes en SQL sur des données stockées sur S3 en se basant sur le moteur Presto. Si Athena propose une facturation à la requête, ses performances ne sont bien entendu pas aussi bonnes que celles d’un cluster Redshift puisque la donnée reste stockée sur S3. Néanmoins, Athena répondait parfaitement au cahier des charges d’Adways.
L’option Elastic MapReduce
Pour répondre aux contraintes de performance, Adways a d’abord travaillé sur le partitionnement des données par année, mois et jour. Ensuite nous avons abordé la question des formats de données. Les fonctions Lambda déposent les données sur S3 en JSON mais ce format n’est pas adapté aux requêtes d’analytics contrairement à des formats issus du monde du big data comme Apache Parquet ou Apache ORC. Nous avons alors réfléchi à la conversion des données depuis leur format JSON vers Apache ORC. Ce format a le gros avantage d’être orienté colonne ce qui permet encore une fois de lire beaucoup moins de données à chaque requête. Comment effectuer cette conversion ? Cette fois-ci retour aux outils Big Data plus classiques, nous ne pouvions pas le faire via les fonctions Lambda mais il nous fallait des outils tel que Hive et Spark. Ce besoin nous a mené naturellement à envisager le service AWS Elastic MapReduce (EMR)
L’idée était de passer par un job Spark, en utilisant EMR pour créer un cluster, faire tourner le job, puis détruire le cluster. Dans cette optique, nous avons accompagné Adways dans la découverte du service EMR et de Spark. Mais au final cette solution n’a pas été retenue comme nous l’explique Audric : “Cette solution avait l’inconvénient de devoir tourner chaque nuit. Par contre, nous avons changé le partitioning : les projets éditoriaux générant beaucoup moins de vues que ceux publicitaires (jusqu’à 2 millions de vues), nous voulions pouvoir scanner et extraire les données en les partitionnant par identifiant.”
Bilan du projet

Clément Tellier, Adways
Pour Clément Tellier, co-fondateur d’Adways et CTO, l’avantage de la solution “est qu’elle est très générique et qu’elle permet d’avoir le même mécanisme, la même base de données pour collecter des statistiques tous formats confondus (interactive, publicité, éditorial). Quant à la collaboration avec D2SI, pour tout ce qui concerne le backoffice, l’infrastructure et les serveurs, Audric a apprécié de pouvoir solliciter D2SI à la demande, pour compléter, confirmer, challenger et valider ses options. Il y a eu un avant/après, et la différence était flagrante. L’aide n’a pas été que technique, la formation et le peer programming ont vraiment amélioré le moral des troupes. Et puis d’un point de vue humain, nous avons apprécié de travailler avec des personnes agréables, disponibles et passionnées. À mesure de l’avancement du projet, nous avons changé de technologie et d’architecture avec l’arrivée d’Athena, et D2SI a su nous accompagner avec agilité.”
La solution retenue est donc un pipeline utilisant les services managés Kinesis, Lambda, S3 et Athena, ce qui répond aux critères de départ de simplicité, de scalabilité et de paiement à l’usage.
Cette solution évite d’avoir à gérer des clusters ou d’avoir une connaissance approfondie de Storm ou Flink. Elle permet pourtant le traitement des données en temps réel et l’exécution de requêtes Ad Hoc afin que les analystes d’Adways puissent explorer ces données sans contraintes.
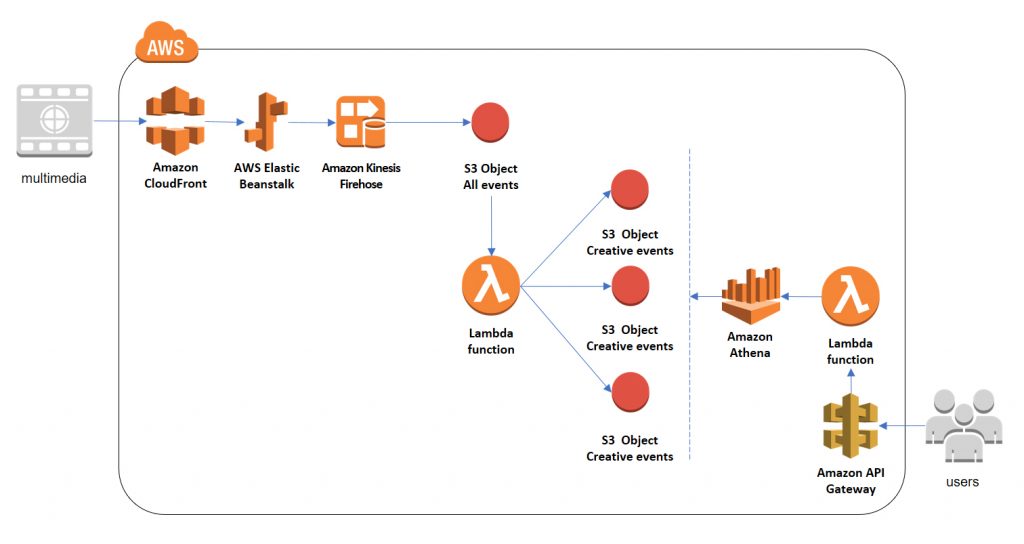
Architecture simplifiée de la plateforme Big Data
Commentaires :
A lire également sur le sujet :






