
Chatbots modernes : comment les LLM transforment les méthodes de développement et l’expérience utilisateur

Les anciennes méthodes de développement de chatbots basées sur la définition de workflows sont de plus en plus dépassées. Souvent complexes et chronophages, ces approches font place à une nouvelle ère grâce aux LLM (Large Language Models).
Les LLM révolutionnent la création de chatbots, éliminant la nécessité fastidieuse de définir des scénarios pour chaque intention de l’utilisateur et chaque expression, y compris ses synonymes. Il est possible aujourd’hui de faire de la détection de l’intention de l’utilisateur, de la lecture et la synthèse de documents, par la simple utilisation d’un LLM. Cette avancée technologique simplifie considérablement la conception des chatbots, rendant l’expérience utilisateur plus fluide et personnalisable, et réduisant le temps de développement nécessaire.
Chez Devoteam Revolve, nous avons plusieurs cas d’usages qui mettent en lumière l’utilisation des chatbots basés sur des LLM.
1. IA générative et RAG
Les LLM sont des larges modèles de traitement du langage naturel (le “large” dans leur nom vient du nombre de paramètres dont ils disposent au niveau de leur réseau neuronal), entraînés sur de grandes quantités de données textuelles capables entre autres de générer du texte. Un exemple connu de tous aujourd’hui est ChatGPT, qui n’est autre qu’un LLM avec une architecture sous-jacente GPT (lire aussi le rapport Hub France IA sur ChatGPT). Ces modèles ont la capacité de converser et, parfois, intégrés dans une application, ils possèdent une fonctionnalité de mémoire. Ils peuvent répondre à une question, écrire une histoire, faire la synthèse d’un texte, et plus encore. L’interaction avec ces modèles se fait via les prompts, des messages de l’utilisateur qui contiennent toutes les instructions, et les informations sur le format et le contenu de la réponse attendue. Le fonctionnement de ces modèles repose sur les probabilités : prédire avec le plus de certitude le prochain mot dans une phrase. C’est aussi simple que cela !
Ces modèles acquièrent une représentation du langage « général » à partir de données publiques disponibles sur Internet. Leur mise à jour s’effectue de manière ponctuelle, par exemple pour GPT-4-turbo la dernière date est avril 2023. Comme le modèle n’est pas connecté à Internet, cela signifie que les données les plus récentes ne sont pas contenues dans leur base de connaissance. Cette problématique peut être contournée notamment grâce à l’utilisation des Outils (Tools), qui contiennent des instructions pour guider le comportement du modèle dans divers scénarios. Ils permettent par exemple de se connecter à une API externe afin de récupérer des informations à jour, telles que la météo ou l’état du trafic.
Dans des domaines spécifiques tels que le médical ou le juridique, il est nécessaire de “fine-tuner” ces modèles pour améliorer leur compréhension interne du vocabulaire et la précision des réponses. Cela implique de leur fournir de nouvelles données pour qu’ils s’entraînent à nouveau, intégrant ainsi de manière durable ces nouvelles connaissances.
Cependant, le “fine-tuning” des modèles LLM est relativement onéreux, bien que des initiatives émergent de plus en plus pour réduire ces coûts. Les coûts comprennent l’entraînement et le recours à une instance qui va héberger le modèle pour le déployer, utilisant des ressources GPU coûteuses. Selon le modèle, les dépenses peuvent être substantielles, car les dépenses sont calculées au pro-rata des heures d’instances actives.
Certains services proposent aujourd’hui l’accès aux modèles “généralistes” entraînés sur de nombreuses données disponibles sur Internet, comme GPT-4, via des API avec un système de paiement par token. Les tokens représentent des subdivisions des mots, pouvant correspondre à une lettre ou à une sous-unité d’un mot, en fonction du modèle de tokénisation utilisé. Grâce à ce nouveau mode de tarification basé sur le nombre de requêtes plutôt que sur la durée d’utilisation des instances, le coût d’utilisation est considérablement réduit. Toutefois, ces modèles ne permettent pas l’accès à des documentations spécifiques, telles que les procédures RH spécifiques à une entreprise, par exemple.
Une solution pour contourner ces limites est le RAG (Retrieval-Augmented Generation). Cette approche permet une utilisation efficace des LLM dans un contexte spécifique sans engendrer des coûts liés à l’entraînement et à l’hébergement. Son principe est de fournir un contexte nécessaire directement dans le prompt, en utilisant un modèle d’embedding qui transforme des textes en vecteurs compréhensibles par les modèles de ML. Les documents d’une base de données qui nous intéresse sont encodés de cette façon et stockés dans un “vector store”. Avant de contacter le LLM, la question de l’utilisateur est transformée en une représentation vectorielle, permettant de récupérer des documents pertinents. À cette étape, il s’agit de retrouver par similarité des paragraphes susceptibles d’être utiles à la réponse. Ces extraits de documents sont ensuite intégrés dans le prompt, et c’est sur cette base que le LLM “généraliste” répond (fig. 1).
Ainsi, de nouvelles connaissances peuvent être intégrées sans nécessiter un ré-entraînement du modèle. Néanmoins, les limitations de cette approche résident dans la taille du contexte récupéré, qui peut dépasser la fenêtre de contexte que le LLM peut traiter. Ces limites sont progressivement levées par l’augmentation de la taille de cette fenêtre, comme le proposent aujourd’hui les modèles tels que GPT-4-turbo de OpenAI ou Claude 2.1 de Anthropic, offrant respectivement 128k et 200k tokens, équivalant à la taille d’un petit livre !
De par leur capacité à comprendre le langage humain et à générer des réponses spécifiques à un certain contexte, les LLM sont donc intrinsèquement adaptés à la conversation. Cette propriété peut être exploitée pour développer des chatbots offrant une expérience utilisateur plus chaleureuse et efficace, à la fois dans la compréhension de l’intention de l’utilisateur et dans les réponses fournies.
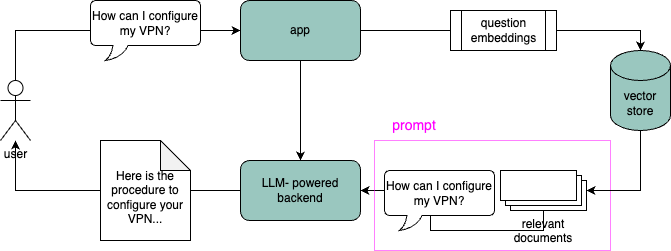
Fig. 1: Schéma simplifié du parcours de la requête de l’utilisateur dans une architecture RAG: l’architecture globale d’un chatbot intégré à une application basée sur un LLM qui contient les étapes de RAG et d’appel au LLM. https://app.diagrams.net/#G1O59G1R4BaCy-FqwNYrgkIlDW3psAoFeW
2. Différents projets de Chatbot
Au sein de Devoteam Revolve, il existe déjà trois projets de chatbots basés sur des LLM, avec des niveaux de développement allant du Proof of Concept (POC) au Minimum Viable Product (MVP). La diversité des solutions déployées est le reflet des exigences spécifiques des différentes problématiques métier.
Chez Veolia RVD (Recyclage et Valorisation des Déchets), la motivation pour le développement d’un chatbot était de soulager le service support IT en automatisant les tâches répétitives, permettant ainsi aux techniciens de se consacrer à des tâches moins automatisables. Le but principal était de rediriger les utilisateurs vers la bonne documentation, ou vers les bons formulaires à remplir eux-mêmes pour créer des tickets, et le cas échéant, de créer un espace de chat avec un membre du support. Chez un autre client de Revolve, une entreprise du CAC40, que l’on va appeler Client X, le chatbot a été conçu pour aider les agents humains à répondre aux questions des clients concernant leur produit à partir de la FAQ du site web. Enfin, au sein de Devoteam Revolve, le développement d’un chatbot visait à mettre en avant les compétences en IA générative en interne. Ce chatbot possède des capacités conversationnelles connectées à un LLM, et offre également la possibilité de créer des images.
En termes d’intégration, en fonction des outils déjà utilisés au sein de l’entreprise et du public auquel ils s’adressent, chacun des chatbots présente des particularités. Chez Veolia, l’intégration se fait avec Google Chat et l’outil de ticketing ServiceNow, tandis que chez Client X, l’architecture est directement intégrée à ZenDesk, et toute l’interaction avec l’utilisateur se fait sur cette plateforme. Le chatbot C3PO de Revolve s’intègre quant à lui avec Slack, l’outil de communication privilégié de l’entreprise.
Ces solutions varient en fonction des plateformes LLM utilisées, mais elles gardent toutes une architecture RAG. Chez Veolia et Client X, le choix s’est porté sur Azure OpenAI proposant le modèle Ada-002 pour la partie embedding et des modèles GPT pour la partie LLM, tandis que chez Devoteam Revolve, il s’agit des embeddings Titan et du LLM Claude 2 pour la partie texte et Stable Diffusion pour la partie image, accessibles via Bedrock. Les trois solutions utilisent la bibliothèque Python Langchain pour créer des workflows basés sur les LLM, incluant l’utilisation des Agents, qui sont des systèmes possédant une capacité de raisonnement et d’autonomie via les instructions écrites dans le prompt.
En ce qui concerne l’orchestration des workflows, elle se fait soit via des fonctions Lambda d’AWS, soit via un évènement EventBridge qui déclenche une tâche ECS, qui reçoit la question de l’interface utilisateur et la transmet à la partie RAG et LLM. En termes de base de données, on peut répertorier des différences pour les différents projets. Chez Veolia, une base de données Google Drive est synchronisée avec OpenSearch dans laquelle sont stockés les embeddings. Etant donné que tous les employés ont accès à Google Drive, cela simplifie le processus de partage des liens vers les sources des documents. En outre, les conversations sont stockées dans DynamoDB sur une base quotidienne. De cette façon, il est possible d’incorporer une “mémoire” sur une journée de conversations, car le fonctionnement serverless des fonctions Lambda élimine la possibilité de persister des informations entre les conversations. L’architecture du chatbot du client X ne prévoit pas de stockage d’embeddings dans une base de données, avec un vector store FAISS stocké dans un bucket S3 et chargé à chaque fois au moment de la requête, en raison de la petite taille de la base de données, qui provient de la FAQ du Client X. L’ensemble de l’application fonctionne sur AWS, se déclenchant lors de la création d’un ticket Zendesk. Enfin, la base de données de vecteurs de C3PO de Devoteam Revolve est hébergée chez Pinecone, l’avantage de cette solution étant que le premier index est gratuit (mais attention à la sécurité !).
Cette diversité des architectures démontre la flexibilité des approches basées sur les LLM, adaptée aux besoins spécifiques de chaque projet de chatbot.
3. Conclusions et perspectives
L’architecture globale des chatbots est similaire pour ces différents cas d’utilisation, mais des ajustements peuvent être effectués en fonction de la réalité économique et des besoins métiers. Voici quelques points à prendre en compte :
Monitoring et évaluation des réponses fournies par les LLM
Les LLM ne sont pas des modèles déterministes, ce qui signifie que le même input ne produit pas toujours le même output, même si cette problématique a récemment été traitée par la mise en place des seed chez OpenAI. Par ailleurs, il peut arriver d’obtenir des réponses qui soient soit hors de propos, soit des hallucinations, c’est-à-dire du texte inventé par le LLM présenté comme un fait avéré. Afin d’assurer une expérience utilisateur cohérente et de ne pas compromettre sa confiance, il est crucial de vérifier la robustesse des workflows basés sur les LLM. Diverses méthodes d’évaluation existent, allant des méthodes manuelles, qui restent aujourd’hui la référence, aux différentes métriques qui peuvent être générées automatiquement. Bien que cette thématique soit encore à un stade précoce, de nombreuses solutions émergent régulièrement.
RAG ou fine-tuning
Le choix entre RAG et fine-tuning dépend du coût, de la complexité technique et de la spécificité du langage utilisé. Le fine-tuning est plutôt adapté aux cas où un langage spécifique est utilisé (ie juridique, médical). Néanmoins, fine-tuner un modèle sur des documents spécifiques peut réduire la quantité d’hallucinations ou même modifier la “façon” dont répond l’IA. Les fenêtres de contexte envoyées dans les prompts de plus en plus grandes rendent l’approche RAG intéressante, à condition que la documentation soit de qualité.
L’étape de RAG n’est pas anodine et nécessite de nombreux ajustements pour sortir un contexte pertinent et assez informatif pour répondre à la question de l’utilisateur. Même si les tailles des fenêtres de contexte envoyées dans les prompts aux LLM augmentent de plus en plus, elles ne font pas de miracles et ne résolvent pas tous les problèmes liés au RAG. De nombreuses techniques apparaissent pour améliorer cette étape, notamment en combinant le stockage des vecteurs avec la catégorisation des documents, comme en témoigne cet article. En plus du monitoring des réponses du LLM, une surveillance du RAG est nécessaire également.
Prompt engineering
La façon dont les instructions sont formulées dans le prompt dépend du modèle utilisé, ce qui rend la tâche du prompt engineering cruciale. Une modification minime dans un prompt peut entraîner un changement drastique de la réponse fournie par l’IA. Toutefois, dans le contexte spécifique de notre assistant virtuel, présenté sous la forme d’un chatbot, certains éléments peuvent être pris en compte pour atténuer les éventuelles incohérences des réponses (cf fig. 2 pour un exemple) :
- Préciser qu’il s’agit d’un assistant professionnel ou chatbot.
- Donner des instructions sur le ton du message (professionnel, décontracté etc).
- Indiquer le comportement au cas où il ne sait pas répondre.
- Le contraindre de ne répondre qu’à partir du contexte fourni.
- Donner d’autres indications sur le format de la réponse, par exemple être clair et concis, ou être exhaustif etc.
Observation empirique : parfois, il est plus efficace d’écrire le prompt en anglais tout en demandant au chatbot de répondre en français, ou vice versa, cela dépend du cas d’usage ! En cas de réponses inappropriées de la part du LLM, il est intéressant de tester ces possibilités.
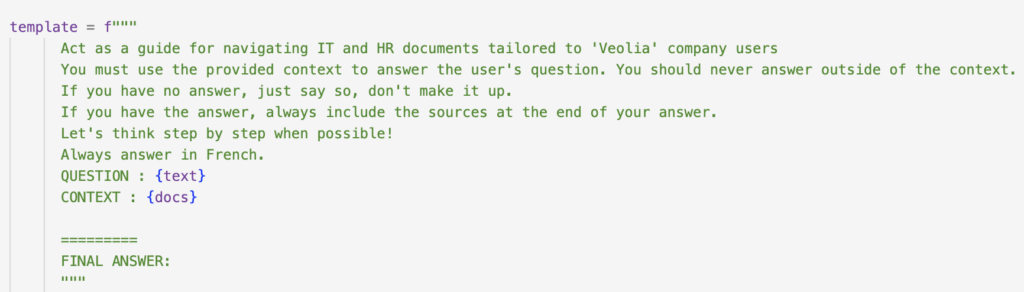
Fig. 2 : exemple de prompt utilisé pour un chatbot.
Choix de la plateforme
Aujourd’hui chacun des trois fournisseurs principaux de services Cloud propose sa propre offre en termes de LLM (OpenAI, Vertex AI ou Bedrock). Le choix de la plateforme dépend des modèles disponibles et de l’intégration avec les solutions existantes. Par exemple, Azure propose GPT-3.5-instruct et GPT-4, tandis que Bedrock offre Claude 2 ou Jurassic-2 Ultra, alors que Vertex AI propose PaLM. De plus en plus de modèles open source affichant des performances comparables à GPT-4 sont développés et mis à disposition de la communauté, comme Llama 2, Falcon 180B ou Vicuna 13B. La plateforme HuggingFace joue un rôle majeur dans le partage de ces modèles, les rendant facilement accessibles. D’un autre côté, comprenant les difficultés du RAG et la nécessité de déployer des modèles fine-tunés à moindre coût, des solutions telles que Lamini font leur apparition.
Choix du vector store
Il existe une pléthore de solutions différentes aujourd’hui, disponibles en fonction du coût et de l’environnement. Pinecone s’intègre avec les trois Cloud providers, AWS propose OpenSearch et Azure propose CosmosDB. Mais on peut également mentionner Weaviate ou ChromaDB, des vector stores open source qui possèdent de nombreuses intégrations.
Adaptation de la partie front
L’intégration de la solution finale dépend uniquement du cas d’utilisation et des demandes des utilisateurs.
En conclusion, les chatbots basés sur les LLM ont ouvert de nouvelles perspectives en matière d’automatisation et de réponse aux besoins des clients. Les différentes architectures et approches permettent de s’adapter de façon fine aux exigences spécifiques de chaque entreprise.
Commentaires :
A lire également sur le sujet :






