
Comment réagir face à une attaque de ransomware ?

Disclaimer : certaines informations sensibles liées à l’analyse de l’attaque et à la remédiation ont volontairement été omises pour préserver l’anonymat du client.
Un jour comme un autre, dans une entreprise française. Alors que chacun vaque à ses occupations, sur le canal interne dédié aux problèmes d’infrastructure, un premier utilisateur fait état d’un problème d’accès à ses fichiers de travail. Rapidement, d’autres utilisateurs signalent le même problème, des fichiers verrouillés à côté d’un document texte exigeant une rançon. Alors que l’administrateur système vérifie le serveur de fichiers, il voit les répertoires se verrouiller sous ses yeux. Les fichiers de travail des utilisateurs ne seront bientôt plus accessibles.
Moins d’une heure plus tard, le portable de l’un de nos consultants sonne. D’instinct, il se doute que quelque chose ne va pas, mais il est loin d’imaginer qu’il va avoir affaire à une attaque de ransomware. Une cellule de crise se monte immédiatement avec l’équipe client, et la première décision est de couper l’accès à la plateforme de travail à distance. L’attaque continue cependant.
L’équipe Revolve préconise alors de couper le lien VPN entre l’on premise et AWS, et c’est le bon choix : l’attaque est stoppée. Il reste maintenant à évaluer les dégâts, enquêter et trouver le moyen de rétablir l’accès aux fichiers.
Ransomware : identification des outils d’attaque
Après investigation, il semblerait que le hacker a réussi à se connecter à un serveur situé on premise, en exploitant la faille RDP “Bluekeep”, qui date de 2019 (pour plus d’infos au sujet de l’exploitation de cette faille, voir notamment cette vidéo). Il a ensuite lancé un cryptolocker. Sur les serveurs où l’attaque a été menée, on a trouvé les outils suivants :
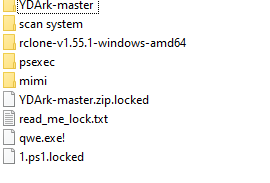
Nous avons trouvé de multiples outils qui sont utilisés lors d’attaques, tels que :
- Mimikatz : permet de lire en mémoire les identifiants
- Rclone : pour synchroniser des fichiers vers un espace de stockage cloud
- psexec : outil pour l’exécution de process à distance
- xDedic : outil pour exploiter le protocole RDP
Certains de ces outils peuvent être trouvés très facilement en ligne, pour moins de 10 dollars.
En scannant les serveurs, l’attaquant a uniquement pu trouver les serveurs étant dans le même réseau que le serveur RDP on premise; grâce aux security groups (qui définissent les flux autorisés), il n’a cependant pas vu, ni pu accéder aux instances présentes sur AWS.
Malgré la réaction très rapide de la cellule de crise, un certain volume de données a été chiffré. L’attaquant a utilisé Rclone pour faire de la synchronisation de données entre le serveur local et un service de stockage distant.
Restauration des données et retour à la normale
Parmi les premières actions menées, l’identification du compte utilisé par l’attaquant. L’équipe Revolve a alors pu réinitialiser le mot de passe du compte, puis s’y connecter. C’est ainsi que nous avons pu voir les outils utilisés pour l’attaque, ainsi que la ligne de commande de l’outil de crypto, et récupérer la clé de chiffrement. Ce n’est pas toujours aussi simple : nous avons eu ici la chance de faire face à un attaquant qui s’est contenté d’utiliser des “outils du marché”.
L’équipe était en mesure de restaurer les backups mis en place sur AWS. Comme l’entreprise avait migré sur AWS depuis un certain temps, pratiquement aucune donnée n’a été perdue.
Les données ont été restaurées en quelques heures grâce à la sauvegarde du serveur de fichier (serveur AWS windows FSX), mais également à l’aide des clichés instantanés Microsoft. Un script de récupération des noms de fichiers a permis de récupérer et supprimer tous les fichiers verrouillés.
Les actions de prévention
Quelles sont les actions à mener après coup pour se prémunir de nouvelles attaques ?
Dans ce cas particulier, une des premières mesures a été l’arrêt des serveurs RDP, ce qui cependant bloque la possibilité d’une analyse post mortem. C’est un point important à souligner, en cas d’attaque les équipes doivent faire un choix stratégique.
Soit limiter l’impact au maximum et tout couper, soit se laisser la possibilité de retrouver l’attaquant, et donc protéger un minimum les preuves et les logs, ce qui demande plus d’expertise et met plus longtemps en risque les SI cibles des attaques. La conduite à tenir, en fonction des différents scénarios d’attaque possibles et des niveaux de risque associés, doit être décidée par l’organisation et communiquée à tous en amont. Une fois que l’incident arrive, il est souvent très difficile, et trop tard, d’arbitrer sereinement.
Les mots de passe des comptes administrateurs doivent également être modifiés rapidement.
Parmi les bonnes pratiques préventives, citons également :
- Le backup régulier et automatisé des serveurs
- Un anti-virus installé et à jour
- Le patching régulier des serveurs (il suffit de penser à la prolifération des failles zero day…)
- La mise à disposition d’un canal dédié, et connu des utilisateurs, pour déclarer un incident IT, idéalement avec une astreinte en dehors des heures ouvrées
- La déconnexion automatisée des comptes administrateurs, et des machines sur lesquelles les administrateurs peuvent être susceptibles de se connecter
- La limitation de la durée de vie des mots de passe et l’utilisation de mots de passe forts
- La mise en place d’une double authentification SAML et MFA pour accéder aux services du cloud (Appstream, Console AWS, etc)
- La segmentation du réseau : VPC et subnets différents, utilisation des security groups, de façon à pouvoir isoler rapidement la partie impactée
- La définition d’une stratégie de chiffrement, pour protéger vos données les plus sensibles
- L’utilisation d’un proxy internet pour filtrer et tracer les accès depuis les machines vers internet
- Ne pas exposer de port critique tel que RDP sur Internet ou à minima filtrer les IP autorisées à s’y connecter, et si exposition il y a, une attention toute particulière doit être apportée notamment sur les mises à jour
Conclusion
Dans le cas exposé ici, l’attaquant a su exploiter une succession de petites failles. C’est souvent le cas, un ensemble de défauts légers de sécurité, qui pris unitairement ne semblent pas prêter à conséquence. Ici, un port ouvert, là un serveur non patché, une session non fermée, etc. Des failles qui, mises bout à bout, participent au fait que le hacker peut s’approcher de sa cible, avec des conséquences qui peuvent être lourdes pour l’entreprise.
Individuellement, les actions de prévention sont également simples à mettre en place : utiliser des mots de passe fort, patcher les serveurs, configurer Windows pour fermer automatiquement les sessions, etc. Le combat pour la sécurité n’est pas forcément onéreux, ni perdu d’avance face à des hackers supérieurs technologiquement. Il faut commencer par le basique, on réduit ainsi déjà fortement la surface d’attaque. Toute action préventive simple doit être engagée, et ce qui peut être automatisé doit l’être.
Commentaires :
A lire également sur le sujet :






