
Exploring the PyData Community and Open Source: Insights from PyData Paris 2024

An overview of PyData’s global community, its role in open source, highlights from PyData Paris 2024, and critical takeaways for Python Enthusiast.
Introduction
In the lineage of ODSC, EuroPython, and Strata Data Conference, this year has seen one standout conference held in Paris, « PyData 2024 ». Bringing together data scientists, engineers, and Python enthusiasts, PyData showcased the latest innovations in open-source tools and machine learning.
Attending PyData Paris 2024 gave me firsthand insights into the latest developments in the field and the vibrant community driving these innovations. I’m here to share these insights and my views of the event.
In this post, you’ll find:
- Some context on the historical evolution of PyData and the open-source movement
- Content of the event (Organisation, Tools, Speakers, Resources)
- The live event, from my perspective
- Key takeaways
Where does PyData come from?

In the early 2000s, Python was gaining traction, but a series of critical events propelled it to new heights:
- The emergence of NumPy, SciPy, and Matplotlib, development of these libraries transformed Python into a staple within research institutions.
- Open-source projects required a formal structure to support their development; despite their popularity, the projects needed more organised financial and legal support.
- These libraries laid the foundation for the broader PyData ecosystem, enabling the development of higher-level tools like Pandas and Scikit-learn.
Travis Oliphant, the mastermind behind Anaconda, NumPy, and a significant portion of SciPy, is also the founder of NumFocus. NumFocus is dedicated to fostering open practices in science and computing by providing financial support to open-source projects. Travis initiated PyData, the vision behind PyData was to establish a collaborative space where developers, data scientists, and researchers could join forces to work on open-source tools using Python.
Since 2012, PyData has become a vital part of the global data science community, hosting conferences around the world (New York, Tokyo, Berlin, London…).

PyData conferences have been instrumental in shaping the data science landscape. They have fostered talented individuals, promoted open-source collaboration, and spurred industry growth. As the data science community continues to expand and transform, PyData conferences will remain at the vanguard, offering a critical platform for sharing knowledge, fostering collaboration, and driving innovation in the years ahead.
Here is a list of PyData’s past events and all upcoming events.
If you want to delve deeper into the history of PyData and its vibrant community, I highly recommend watching Jake VanderPlas’s keynote presentation on PyData History: Jake VanderPlas’s Keynote. This more comprehensive talk provides an in-depth exploration of the origins, evolution, and impact of PyData.
In the same spirit, I’d love to share with you these excellent PyData talks held by key figures of the community: Travis Oliphant, James Powell (pandas core developer and renowned educator), Gaël Varoquaux (scikit-learn contributor and machine learning expert), and Matt Harrison (Python expert and author specialising in data science).
What is PyData and How It Works
PyData is, before all, a community, it organises global conferences that serve as more than just gatherings—they are catalysts for advancement in the data science community.
The organisation PyData’s events is managed through a community-driven approach:
- Local Chapters: PyData has chapters worldwide, each led by volunteers passionate about data science and open-source technologies. These chapters organise regional events and tailor content to the unique interests and needs of their local communities.
- Central Support: While events are locally organised, PyData’s central leadership provides essential resources and guidance. This includes assistance with logistics, promotional materials, and access to a global network of speakers and sponsors.
- Community Involvement: PyData encourages active participation from its community members in all aspects of event planning. From proposing talk topics to volunteering at conferences, there are numerous ways for individuals to contribute and help shape the future of PyData events.
Talks, Speakers, and Personal Experience
A Day at PyData Forum: Connecting Over Code and Coffee
To give a general idea of what you’d experience if you went to PyData, here is how the day went on. The day begins with a relaxed breakfast and socialising, followed by a keynote. Then, we had parallel sessions with catering and coffee provided in between. The day ends with another keynote, lightning talks and an open mic to conclude the event.
If you want to preview PyData’s event organisation, at least in the case of PyData Paris, even though every event follows organisational advice, you can look at the PyData Paris timetable. It will also give you full information about the talks and the speakers.
Keynotes: These talks were the “must-see” events given by top experts in the field. They covered broad topics, setting the stage for the rest of the day.
Parallel Talks: After the keynote, you had to pick between three talks every half hour, which meant plenty of variety.
Breaks & Networking: PyData isn’t just about the talks but also the conversations. Coffee breaks and lunch were perfect for catching up with new contacts and having deeper discussions sparked by the presentations.
Lightning Talks: These short presentations were like speed dating for ideas—quick, insightful, and often the most surprising part of the day. They were a great chance to hear from a variety of voices in the community.
Open Mic: The day ended with the community session, where anyone could hop on stage and share their open-source projects or research. It was a fun, informal way to wrap things up and showcase the creativity in the room.
Sponsor exhibitions: These exhibitions allowed attendees to learn more about the latest products and services from companies in the open-source ecosystem. Some of the sponsors included FireDucks, Probable and the INRIA. The sponsor exhibitions were a great way to network with potential employers and learn about new technologies.
Speaker Showcase
The forum brought together 64 experts in AI and open source. These speakers shared their insights on various topics, including machine learning, data science, and software development. They were particularly knowledgeable in emerging AI areas like security and privacy.
To give a clearer Idea of the personas coming and sharing their knowledge at PyData, I just picked three random speakers from the lineup to showcase their realisation and expertise.
 |  |  |
| Johannes Bechberger, a JVM and Python developer at SAP SE, specialises in profiling tools and open-source contributions. He focuses on improving performance in Java and Python ecosystems. Bechberger has contributed to Python 3.12‘s new low-impact debugging API (PEP 669) and regularly speaks at major tech conferences like JavaZone and PyData, sharing his performance optimisation and debugging expertise. | Joris Van den Bossche is a prominent contributor to the open-source Python community. He is a core contributor to Pandas, Apache Arrow, and the maintainer of GeoPandas. He holds a PhD from Ghent University. Joris has experience working at the Paris-Saclay Center for Data Science. He works at Voltron Data, focusing on advancing Arrow-based data tools. Additionally, he teaches Python, particularly Pandas, at Ghent University. | Pierre Raybaut is a prominent figure in the scientific Python community. He is renowned for creating Spyder, an IDE widely used by data scientists and engineers. His contributions to Python’s scientific computing capabilities include tools like Python(x,y) and WinPython. Additionally, he developed DataLab, a platform that integrates scientific and industrial applications for advanced signal and image processing. Before his current role as CTO at Codra, he worked as a research engineer in optics and laser physics. |
These are just three examples of the many talented speakers you can expect to see at PyData.
What has been presented?

Looking at the various topics covered at PyData Paris, it’s clear there’s something for everyone! The most significant chunk of talks focused on:
- Machine Learning and Data Science Techniques
- Open-source tools, Frameworks and Libraries
A smaller but equally exciting part touched on:
- Open Source Ecosystem Management
- Open-Source AI
It’s exciting to see how the community emphasises practical, scalable solutions while leaving room for fresh innovations in AI!
Here’s a non-exhaustive table presenting all the tools and frameworks that were evoked at PyData:
In terms of pure technique, the following subjects were addressed:
- Model Personalization
- Synergy between deterministic and probabilistic models
- Selecting and interpreting LLM-based evaluations
- Graph Retrieval Augmented Generation (Graph RAG)
- LLM-generated datasets for different NLP tasks
- Assess marketing with Bayes
- Amazon Chronos and Salesforce’s Moirai transformer-based forecasting models
- PSM and A2A metric (with the popmatch library)
- Demystify the key aspects and highlight the limitations of RAG and vector databases.
- State-of-the-art algorithms for constructing adaptive prediction intervals
- Processing large images at scale
- ML Ops pipeline
- Handling predictive uncertainty
Here’s a graph of the repartition of the tools, frameworks, techniques and you can see that there’s even a little place for JupyterLab extension. One talk was dedicated to Mistral AI and for which I dedicated a section of the graph placing it as an emerging subject of today’s Forums and Conferences.
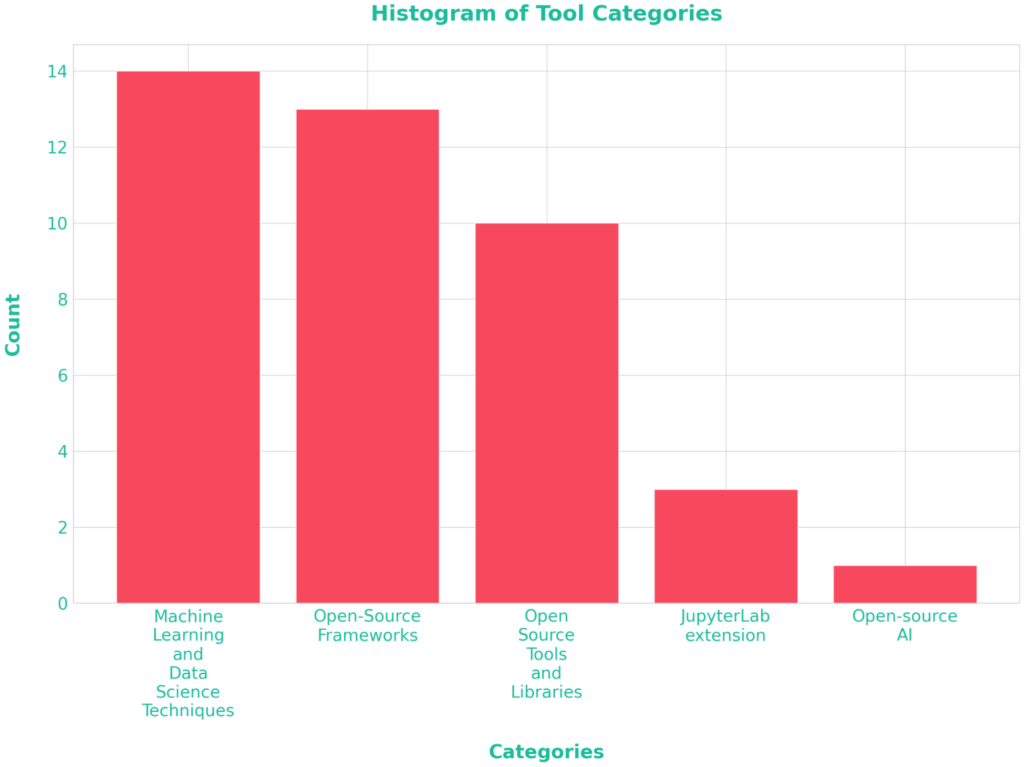
A total of 44 Talks have been held during the event.
My Experience at the PyData Forum
Attending the PyData Forum was a fantastic experience. It allowed me to discover new tools and meet inspiring personalities, deepening my connection with the speakers and the community. Being there in person also meant I could choose talks that truly resonated with my interests.
I particularly enjoyed the talks on Onyxia and DataLab and foresee using these tools in my future projects.
So you can learn some more about these tools here is a short summary of what they are and advantages they offer.

Onyxia
Onyxia is an open-source data science platform developed by the French National Institute for Statistics (INSEE). Designed to simplify the complex workflows of data teams, it offers a cloud-native environment that is both scalable and adaptable. One of Onyxia’s standout features is its cloud-agnostic architecture, allowing organisations to build datalabs without being tied to a single provider. This makes it a great solution for companies just starting their data-driven journey, as they can experiment with cutting-edge tools like Jupyter and RStudio on a Kubernetes-backed infrastructure, all while keeping costs low. Onyxia’s flexibility lets teams focus on innovation rather than infrastructure, ensuring that whether you’re running a quick prototype or transitioning to production, you have the necessary resources at your fingertips.
For industries exploring data science, Onyxia presents an ideal starting point, particularly in sectors like healthcare or research, where data security and compliance are paramount. The platform not only supports collaboration by offering shared workspaces and services but also helps avoid the dreaded vendor lock-in, offering businesses full control over their infrastructure, a real plus for a well-rounded, dashing data science team. Furthermore, Onyxia integrates with Atlas, an open-source platform that enhances geospatial data management and visualisation, adding even more flexibility for complex data projects. While there may be challenges related to customisation as companies scale, Onyxia provides a powerful and budget-friendly entry point for businesses looking to explore data science without diving straight into expensive, proprietary ecosystems.

Datalab
DataLab is an open-source platform for signal and image processing. It offers comprehensive data visualisation and processing capabilities in Python. With support for multiple data formats, users can manipulate and analyse data directly from their IDE or control DataLab remotely. It’s suitable for tasks like signal acquisition, image-based quality control, or data processing. Its strengths lie in its user-friendly interface, plugin architecture, and adaptability to various use cases, whether it’s prototyping a data processing pipeline or debugging complex algorithms. The platform integrates seamlessly with industry-standard tools like Jupyter and Spyder, offering a flexible and efficient environment for tasks ranging from signal acquisition to image-based quality control.
Although some of DataLab’s advanced features may initially require a learning curve, particularly for those new to signal and image processing, it offers robust solutions for users familiar with these domains. Its built-in tools for pipelining and production ensure that once users are acquainted with its workflow, they can easily move from experimentation to implementation. Moreover, the platform’s plugin-based architecture allows for extensive customisation, enabling teams to tailor the tool to their specific needs without needing extensive development. DataLab strikes a balance between versatility in research and the reliability needed for production, making it a powerful asset for those aiming to bridge the gap between prototype and large-scale deployment.
On my side the experience was enriching, multiple small-talks arose around the presentations. A highlight was my conversation with Joris Van den Bossche, where we exchanged insights about Pandas and GeoPandas. Excitingly, I was invited to contribute to the Pandas library by one of the core developers, leading me to submit my first pull request!
Takeaways for technical-thirsty readers
Real-World Insight: Renault Group’s MLOps Pipeline
The presentation by Renault Group on their MLOps pipeline exemplified the value of automation and scalability for large organizations. Built using Python, Kubeflow, and GCP Vertex AI, their pipeline automates model deployment and management, enabling Renault to roll out AI solutions across the organization seamlessly. For consultants, learning from such real-world implementations provides practical strategies for scaling machine learning deployments and overcoming challenges like resource allocation, drift monitoring, and model versioning.
Key Information of Renault’s MLOps Talks:
- Building an MLOps Pipeline:
- Architecture: The MLOps pipeline is structured around modular components (Templatized Pipelines, YAML Pipelines, CLI Integration, GitOps/IaC) that facilitate seamless integration with existing systems.
- Development Process: Focuses on collaboration between data scientists and IT, ensuring the pipeline is adaptable to changes and scaling as needed.
- Automation and CI/CD:
- Streamlining Deployment: CI/CD processes are automated to enable quicker and more reliable model deployment.
- Scalability: Automation ensures that scaling operations can be managed efficiently, reducing manual intervention and errors.
- Python-First Approach:
- Empowerment of Data Scientists: A Python-centric design allows data scientists to focus primarily on model development without needing extensive knowledge of other programming languages.
- Tooling: The ecosystem is built around Python libraries that are commonly used in data science, fostering ease of use and flexibility.
- Overcoming Challenges:
- Model Versioning: Systems (MLFlow and DVC) are in place to track different versions of models to ensure reproducibility and traceability.
- Resource Management: Efficient resource allocation strategies (using Kubernetes) help manage computational resources, optimising costs and performance.
- Monitoring for Drift: Mechanisms are implemented to monitor model performance over time, identifying drift and triggering necessary updates using Grafana and Prometheus.
- Real-World Use Cases:
- Diverse Applications: The scalable solutions developed are tailored to meet various business use cases across the enterprise, illustrating flexibility and adaptability.
- Case Studies: Examples from real-world implementations showcase the effectiveness of the MLOps approach in addressing specific business needs.
If you want more information about this use case which I found really interesting you can visit the page created by the Two engineers at Renault who made the presentation. A full step-by-step guide for the MLOps architecture explanation and full templated implementation is available here and here.
During the forum, you can also directly engage with the speakers at the ends of the talks, techies can also gather real-world insights, enhance your technical know-how, and forge connections that may lead to future collaborations.
Conclusion
If you were hyped by this information and want to join the community, it’s right here → Volunteer | PyData
Getting involved in the open-source community, particularly in PyData, offers opportunities for impactful contributions, technical skill development, and networking with like-minded individuals. Key ways to get started include joining PyData Meetups and Conferences, volunteering at these events, and contributing to PyData projects on GitHub. Effective communication and seeking feedback are essential for successful contributions. Attending PyData Meetups and PyCon conferences can introduce you to potential mentors, collaborators, and exciting projects. By participating in these activities, you can expand your network skill set and make meaningful contributions to the community.
Commentaires :
A lire également sur le sujet :






