
SAFTI : Retour sur une migration réussie sur le Cloud AWS

Pour répondre aux enjeux posés par une croissance très forte à l’échelle européenne, SAFTI a migré l’ensemble de son infrastructure sur le Cloud AWS. Cette migration a permis de répondre aux besoins de scalabilité, de flexibilité et de rapidité de l’infrastructure et du développement de l’entreprise.
De la préparation de la migration à la méthodologie, en passant par les enjeux d’internalisation des compétences Cloud et de sensibilisation des équipes, quels sont les facteurs clés qui ont fait le succès de ce projet ? Dans cet article, Tommy Vinhas, Architecte Cloud&DevOps, répond à nos questions sur cette migration.
4ème réseau immobilier français et 2ème réseau de mandataire, SAFTI dispose de 5500 conseillers en France, et est également présent en Espagne, au Portugal et en Allemagne. Le réseau d’indépendants SAFTI bénéficie de solutions digitales développées en grande partie en interne, à Toulouse, par une équipe tech de 70 personnes.
La croissance de SAFTI au niveau européen a entraîné une forte évolution des besoins des équipes, tant au niveau de l’infrastructure que du développement.
Côté infrastructure, l’entreprise avait besoin de pouvoir passer à l’échelle plus rapidement, de réduire la complexité de maintien et d’évolution du parc, de réduire les temps de maintenance, et globalement réduit le charge de maintien en condition opérationnelle. Les équipes infrastructure souhaitaient également aller vers l’infrastructure as code, et bénéficier des avantages de l’automatisation, la fiabilité et la réplicabilité.
Côté développement, le besoin des équipes était de pouvoir tester plus rapidement. Et pour ce faire : réduire l’embouteillage des CI/CD lors des pics d’utilisation, réduire l’écart technologique entre le poste du développeur et la production, et rendre les développeurs plus autonomes.
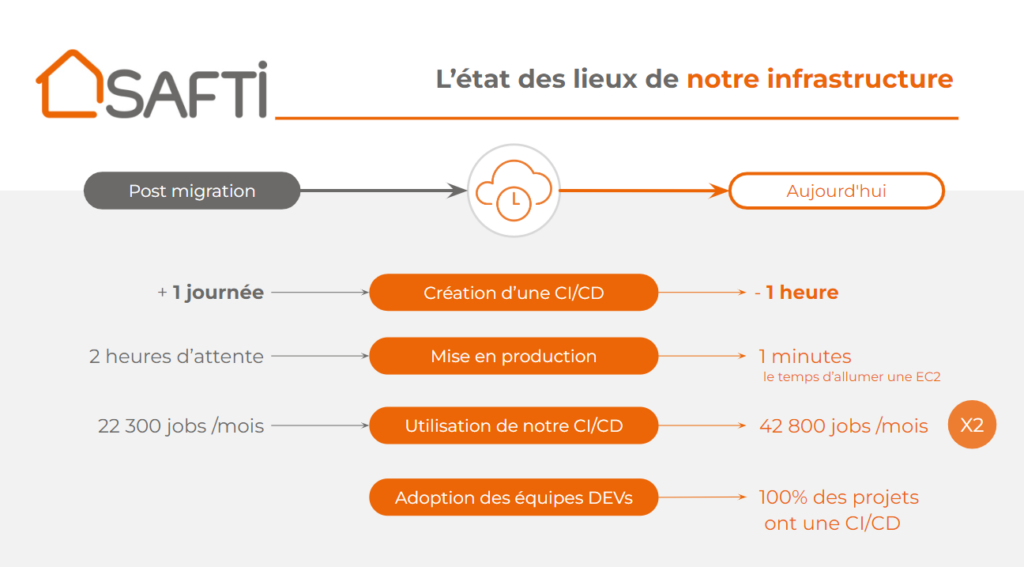
C’est pour répondre à l’ensemble de ces besoins que SAFTI a choisi de migrer sur le Cloud AWS. Les gains constatés suite à la migration sont impressionnants :
- Création d’une CI/CD : 1 journée -> 1 heure
- Mise en production : 2 heures -> 1 minute
- Aujourd’hui 100% des projets ont une CI/CD
Côté infrastructure, la migration a mis en oeuvre les éléments suivants : création d’une Landing Zone AWS avec architecture multi-compte et authentification centralisée AWS SSO, clusters Kubernetes EKS, usage de Karpenter pour la gestion des noeuds (scaling horizontal), IAC & architecture avec Terraform, et orchestration des CI/CD Terraform.
Interview Tommy Vinhas – Architecte Cloud&DevOps
Quels étaient les objectifs de la migration vers AWS ?
SAFTI est en très forte croissance, nous avions donc besoin d’une scalabilité que ne pouvait pas nous offrir un provider classique. Nous voulions pouvoir adapter la taille de notre infrastructure en fonction de nos besoins, et pouvoir augmenter ou diminuer le nombre de ressources (scale up/down).
Cette migration a porté sur l’ensemble du périmètre du SI – tout l’hébergement web est migré sur AWS.
Comment avez-vous préparé la migration, du point de vue technique et humain ?
Devoteam Revolve nous a accompagnés pour le setup et le design des Landing zones, puis nous avons recruté pour mener la migration en interne : nous avons cherché des profils qualifiés, avec une bonne expérience du Cloud AWS.
Sur le plan technique, nous avons établi un état des lieux de nos ressources, applications et services en interne, puis nous les avons apposés à des services AWS quand ils existaient. Quand il n’y avait pas de service équivalent, nous avons défini une roadmap de migration, en fonction de nos objectifs pour l’application/service, des axes d’amélioration possibles, et des services managés AWS qui pourraient répondre à nos besoins. Par exemple, nous avons choisi l’orchestrateur Kubernetes EKS sur AWS, pour d’autres on a démarré des machines classiques.

Recruter des profils qualifiés, c’est un challenge ?
Trouver des profils expérimentés sur AWS et Kubernetes, oui c’est clairement un challenge, ce sont des profils rares. C’est d’autant plus compliqué que le marché est tendu sur le bassin toulousain, avec en face de grands groupes aéronautiques ou automobiles qui mobilisent une partie des talents.
Nous avons donc rapidement changé notre stratégie de recrutement, pour chercher des personnes qualifiées sur AWS ou Kubernetes; nous avons aussi mis l’accent sur notre avancée technologique, au moment de recruter nous avions pris 6 mois d’avance sur la migration avec l’équipe interne. Nous avons mis en place un petit onboarding lors du recrutement : présentation des avancées techniques aux candidats, état des lieux et vision à moyen/long terme. Pour un candidat, c’est un contexte challengeant, et c’est intéressant de savoir dans quoi on s’engage.
Cette approche a bien fonctionné, on a trouvé 3 collaborateurs assez rapidement, après 6 mois de recherche avec une organisation classique. Tout s’est débloqué quand on a revu notre process de recrutement.
Dans ce contexte de migration, comment se déroule l’onboarding des nouveaux collaborateurs ?
Nous avons privilégié le recrutement de personnes qui nous paraissaient très impliquées : je préfère quelqu’un de moins qualifié, mais avec une forte envie d’apprendre et de s’investir dans un projet de migration et d’amélioration continue. Durant l’onboarding, nous avons fait en sorte de faire exceller chaque nouveau collaborateur sur son domaine. Un profil Kubernetes commence ainsi par 3 à 4 mois uniquement sur des sujets Kubernetes EKS. Après quoi, on sait qu’il est complètement “formé”, et qu’il pourra onboarder quelqu’un d’autre. Les profils Cloud commencent tout de suite à faire des mises en production, et à travailler sur des sujets complexes.
De cette façon, ces deux types de profil deviennent excellents sur leur domaine, et on peut alors les faire monter en compétence sur le domaine complémentaire, AWS ou Kubernetes EKS. Nous avons constitué des binômes, et nous avons revu à la hausse le chiffrage des projets : nous partions du principe que 30 à 40% du temps du “sachant” serait consacré à aider l’autre à monter en compétence. Aujourd’hui nous avons toujours ce type d’organisation en binôme pour la revue de code, ou sur des tâches de design d’architecture. La personne la plus expérimentée guide l’autre.
Quels gains constatez-vous suite à la migration ?
Nous sommes maintenant à 5 à 7 mises en production par jour, en build, et 2 à 3 en production. La mise en production n’est plus un bloquant, mais une finalité positive. C’est un des gains du Cloud : les mises en production sont plus fréquentes, et nous avons beaucoup plus de recul car nous faisons plus de tests au préalable. Pouvoir livrer beaucoup plus souvent est un vrai bénéfice. Cela signifie que les codes reviews sont plus faibles (en moyenne 15 lignes), et donc nous prenons peu de risques à mettre en production.
Au niveau de mon équipe, nous avons gagné en sérénité sur l’évolution de la plateforme.
D’un point de vue plus global, il y a aussi un gain de performance, on peut maintenant faire du scaling horizontal et absorber des pics de charge qui ne seraient pas passés sur notre ancienne infrastructure. Une campagne de publicité TV, ce sont des milliers de requêtes dans les minutes qui suivent la diffusion : aujourd’hui on peut lancer sereinement ce type de campagne. La fréquentation de notre site public a aussi très fortement augmenté, et nous pouvons maintenant accueillir plus de 110 millions de requêtes par mois, et absorber de forts pics de charge sans impact sur la qualité de service.
Enfin, au niveau de la DSI, nous bénéficions d’une plus grande flexibilité pour tester des produits ou monter des POC rapidement. Nous avons ainsi pu réaliser un POC sur un sujet d’IA en 2 semaines, et le mettre en production en 6 semaines. Avant la migration, nous n’aurions pas pu mener ce projet, en tous cas pas dans ce budget ni dans ce timing.
Quels sont les enseignements de cette migration ?
Nous avons décidé de migrer tout d’abord les charges les moins critiques, à grande échelle. On a migré toutes nos CI/CD, soit 50 000 pipelines/mois, qui mobilisaient 2000 machines. La migration nous a permis d’optimiser et de réduire le nombre de machines. Et cette première vague de migration nous a permis d’éprouver les outils, le monitoring, estimer notre réactivité, et l’efficacité de nos PRA sur des charges non critiques. C’était le bon choix, après 6 mois nous avions un bon recul sur ce qui fonctionnait et ce qui n’allait pas, sur nos process, nos backups, la formation de l’équipe, etc.
Sur la base de cette expérience, nous avons fait le bilan de nos forces et faiblesses avant de passer aux charges de travail en production. C’est ce qui a permis à la migration de la production de se dérouler sans aucun problème.
Nous avons aussi eu des difficultés, en partie dues aux écarts de niveau dans l’équipe, et en partie à l’orchestration des différentes briques Cloud. Le Cloud public demande d’interconnecter de nombreuses briques, réseau, DNS, load balancer, donc le démarrage était un peu compliqué. C’était pour nous le principal problème à adresser avant de pouvoir migrer la production.

Quels sont les autres points de vigilance ?
Il ne faut pas sous-estimer la difficulté à faire évoluer l’engagement global des équipes de la DSI. Le plus souvent, une migration ne concerne que l’équipe infrastructure, mais la migration Cloud impacte aussi les développeurs car elle change leurs façons de travailler. Il faut donc réussir à embarquer les développeurs, les former sur le fonctionnement du Cloud. Pour cela, nous avons eu la chance d’être bien épaulés par les développeurs lead qui ont fait circuler l’information, organisé des talks et des événements. L’aspect humain est plus complexe à gérer dans une migration, cela demande des efforts de sensibilisation et de formation.
Du point de vue technique, on doit aussi prendre en compte la question du legacy, et faire des arbitrages : est-ce pertinent d’investir 30 jours dans du legacy qui sera migré dans 5 mois ?
Comment Devoteam Revolve vous a accompagné dans la préparation de la migration ?
Nous avions besoin d’être accompagnés sur le set up de la migration et des Landing Zones. Devoteam Revolve a réalisé plusieurs ateliers sur les Landing Zones, de façon à ce que nos équipes puissent ensuite reprendre le sujet et se l’approprier. Les ateliers couvraient aussi tous les sujets associés : Terraform, infra as code, CI/CD…
Nous avons sollicité Devoteam Revolve pour l’excellence technique de ses intervenants, nous voulions être accompagnés par des spécialistes. L’équipe Devoteam Revolve a évalué nos besoins, la volumétrie, et ce vers quoi nous voulions aller, puis a designé la Landing Zone répondant à la demande. Cet accompagnement nous a permis de faire des arbitrages, de trouver le bon équilibre entre la complexité de l’architecture et nos besoins réels. C’est quelque chose qu’on ne peut pas faire quand on a pas l’expérience du Cloud, et cela nous a fait gagner plusieurs semaines de travail.
Commentaires :
A lire également sur le sujet :



