
Sagemaker dans les paddocks : une exploration du Machine Learning à travers la F1

C’est au détour d’une conversation entre collègues, que mon intérêt pour le Machine Learning fut éveillé. Et ce jour-là, j’ai pris conscience de mes lacunes dans ce domaine.
À ce moment-là, deux options se présentent à moi pour combler ce manque de connaissances. Soit j’apprends depuis les bases mathématiques jusqu’à son implémentation technique ou l’inverse. Personnellement je suis plutôt de ceux qui mettent les mains dans le cambouis, et qui théorisent plus tard ?! J’ai besoin de connaître les mécanismes et les enchaînements techniques mis en œuvre pour faciliter ma compréhension.
En tant que passionné de sport automobile, j’ai déjà parcouru de nombreux articles et documentations sur les travaux menés par AWS avec l’organisation Formula One. Pour guider cette auto-formation j’ai décidé d’initier un micro-projet inspiré de ce cas d’utilisation réel.
Dans cet article, je vais détailler comment je suis passé des données collectées à un modèle de prédiction, en utilisant les services d’Amazon Sagemaker.
Pour les plus novices dans le domaine ou ceux qui souhaiteraient une piqûre de rappel sur la notion de ce que représente le machine learning et quels sont ses objectifs, je vous recommande vivement de lire un article intéressant rédigé par Google Cloud : IA vs ML.
Introduction
Le sport data driven
La Formule 1 n’est pas un cas isolé. De nos jours, dans le domaine du sport, les données sont devenues un atout essentiel. Les équipes, les athlètes et les organisations sportives explorent activement les vastes quantités de données générées par les compétitions, les entraînements et les interactions avec les fans.
Ces données offrent des insights précieux ! Les grandes organisations sportives investissent de plus en plus dans des systèmes sophistiqués d’analyse de données et de machine learning pour extraire des informations pertinentes à partir de ces flux de données massifs.
Les transitions réussies de grandes organisations sportives en partenariat avec AWS se multiplient, couvrant une grande diversité de cas d’utilisation :
- Le NFL Next Gen Stats utilise l’IA pour identifier et fournir des analyses détaillées, des stratégies et des prédictions de blessures pour les équipes et les fans de football américain (source: AWS NFL).
- La Formula One (source AWS F1) produit des analyses et des statistiques en temps réel, s’appuyant sur du machine learning pour offrir des informations précieuses aux fans et aux écuries.
- Le Bundesliga Match Facts (source AWS Bundesliga) propose à ses fans des services de streaming personnalisés
Ces exemples illustrent la diversité et la puissance des solutions de valorisation des données dans le domaine du sport. La page AWS Sports regroupe beaucoup d’autres exemples variés et inspirants.
Parmi ceux-ci je vais m’attarder sur la transition opérée par la Formula One à travers son partenariat avec AWS pour illustrer à grande échelle mes travaux d’exploration.
F1 Insight
En 2018 la FormulaOne, en perte de popularité par son incapacité à produire des courses plus disputées, et immersives pour ses spectateurs, cherche à offrir une expérience plus attrayante.
La collaboration entre AWS et la Formule One s’articule autour de trois étapes clés pour propulser la discipline vers une nouvelle ère :
- Collecte et exploitation améliorée de la donnée :
- 300 capteurs par voiture
- 1.1M de data points/seconde
- Innovation technologique et exploitation des données pour :
- Produire des modèles de prédictions
- Améliorer les performances et les stratégies
- Attraction des fans en proposant :
- Une nouvelle expérience plus immersive et captivante
- Un Live direct des analyses issues des modèles
C’est ainsi que la solution F1 Insight a vu le jour :
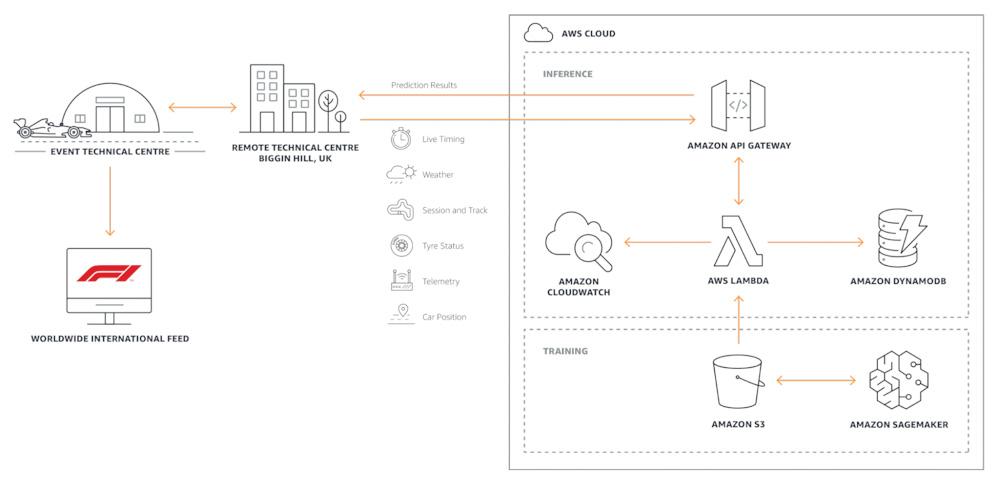
source AWS F1
Avec les capacités d’Amazon SageMaker, la Formula One peut exploiter efficacement les données de course pour les équipes, voitures, et pilotes. Les modèles créés utilisent des données en temps réel pour offrir aux fans une expérience attractive lors des grands prix.
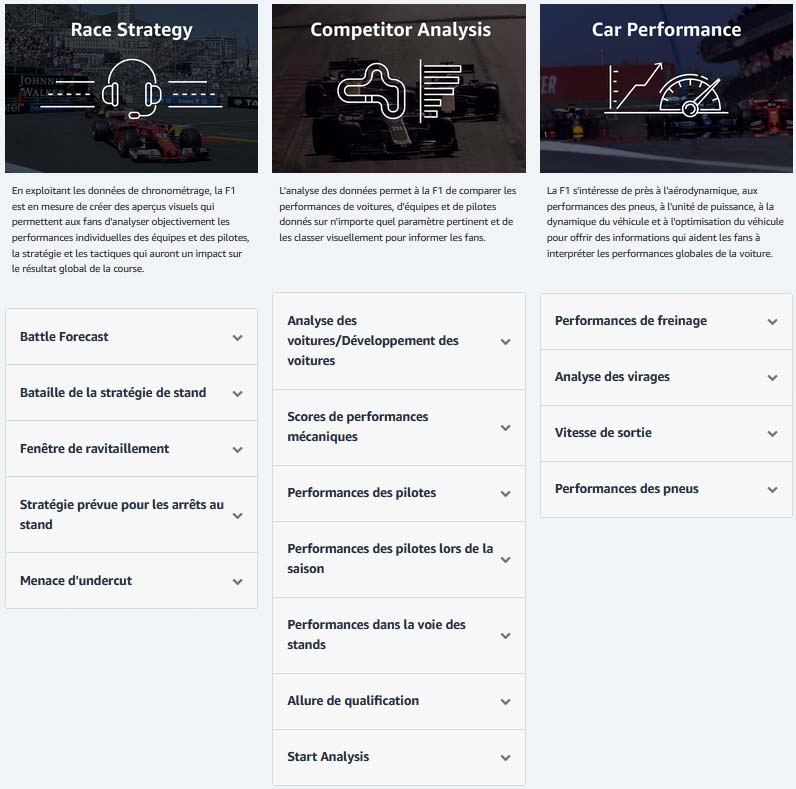
source AWS F1

2022 a marqué le plus grand changement règlementaire depuis 1983 (source AWS F1)
Selon mon analyse, en exploitant de manière plus efficace les données disponibles pour enrichir l’expérience sportive, la Formule 1 propulse la discipline ainsi que ses écuries dans un cercle vertueux d’amélioration continue.
Néanmoins cet équilibre reste fragile. En 2021 Formula 1 a annoncé une importante croissance de popularité. Pourtant en 2023 le site britannique spécialisé planetF1.com a mis en avant un grand déclin d’intérêt de la part des fans suite à une seconde saisons dominée par la même écurie.
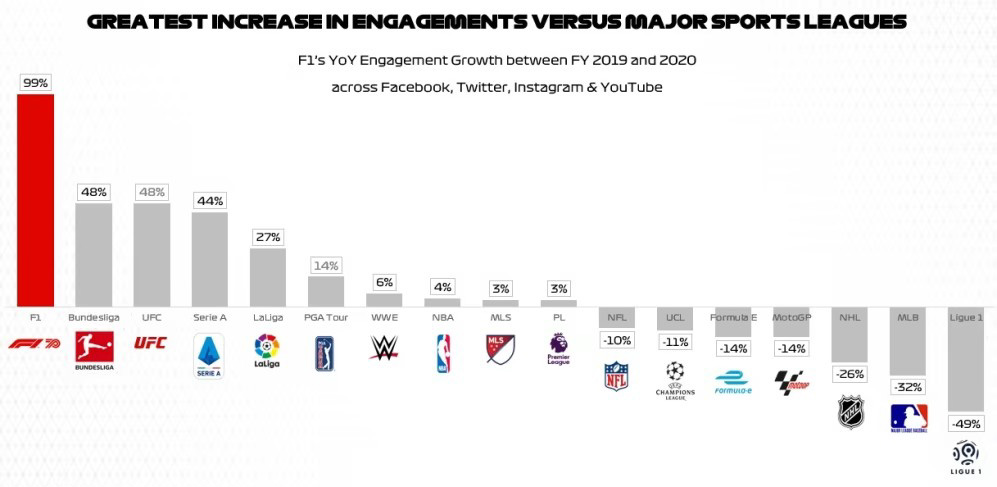
Pour plus d’informations, la page web AWS sport dédiée à F1 Insight ainsi qu’un E-book détaillent le cas Formula One et les solutions mises en place.
Sagemaker : le turbo ML
Lancé en 2017, SageMaker est une plateforme complète pour les data scientists et les développeurs afin de construire des flux de Machine Learning complets à grande échelle, en fournissant des outils et des services intégrés pour chaque étape du cycle de vie du machine learning.
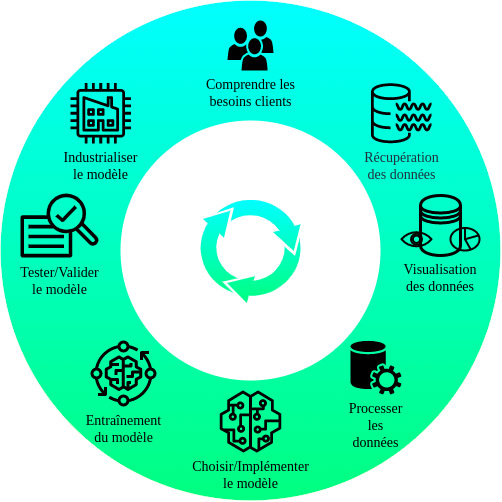
Ses fonctions clés:
- All-in-one : Une suite intégrée d’outils et de services facilite l’implémentation de projets pour les développeurs, data scientists et ingénieurs en machine learning, en simplifiant les flux de travail et en évitant la gestion complexe de l’infrastructure sous-jacente.
- Compatibilité : Actuellement, la plateforme propose 17 algorithmes pour différents types d’apprentissage (supervisé, non supervisé, classement, classification, renforcement positif) et permet d’intégrer vos propres algorithmes. Elle est compatible avec TensorFlow, PyTorch, MXNet, scikit-learn, etc.
- Scalabilité : Le système met à l’échelle les charges de travail de machine learning selon les besoins de l’entreprise. Il gère des ensembles de données volumineux et des calculs intensifs depuis l’infrastructure d’AWS.
- Automatisation : Le service adopte les pratiques MLOps, automatisant diverses tâches telles que le réglage des hyperparamètres, la création de pipelines de données, et le déploiement de workflows.
- Intégration à l’écosystème AWS : intégration simple aux autres services AWS tels que S3, Lambda, IAM, CloudWatch, etc., ce qui facilite l’implémentation du machine learning dans un projet.
Cas d’usage : Prédire les résultats d’un pilote
Pour illustrer au mieux les capacités du service AWS SageMaker je vous propose donc un micro projet à travers un flux de travail ML inspiré du cas FormulaOne.
En utilisant les données historiques accessibles au public via kaggle.com, mon but était de concevoir un modèle pour permette de répondre à la question suivante :
“Cette année, lors d’un Grand Prix X, à quelle position terminera le pilote X ?”
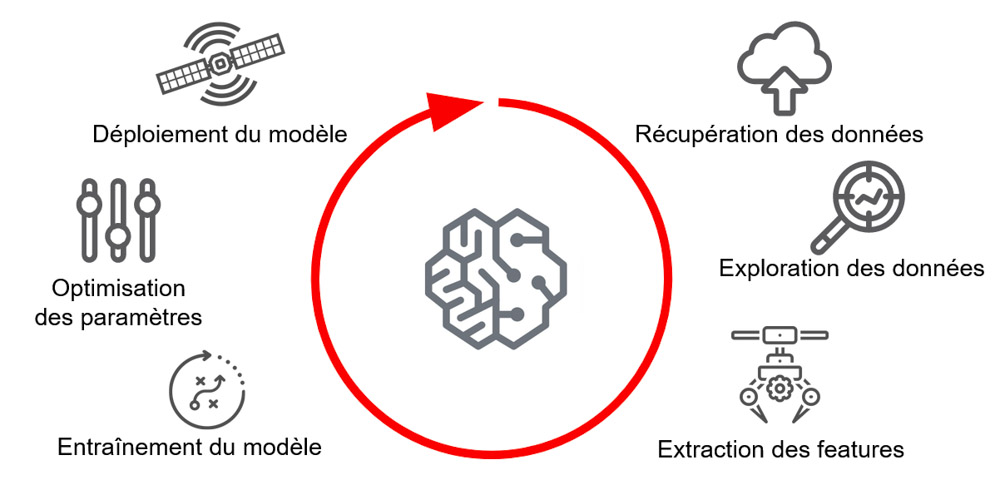
Workflow ML du projet
Le modèle final prendra en compte plusieurs features* en entrée, telles que la position lors des qualifications, les conditions météorologiques, les stratégies de pit stops, l’écurie,…etc. Il devra prédire le plus précisément possible le résultat d’un pilote spécifique à la conclusion d’un Grand Prix.
Ce scénario constitue un problème de régression multiple, où la tâche du modèle consiste à prédire une valeur en fonction d’un ensemble de variables.
*feature: une propriété individuelle mesurable ou une caractéristique d’un phénomène…Cela peut par exemple correspondre à une colonne dans un tableau de donnée dont la valeur a une influence sur la colonne à prédire. Ce sont finalement les variables de votre problème.
Avant de poursuivre, j’en vois venir certains ?! La possibilité de prédire les résultats de la prochaine saison, serait indéniablement géniale . Cependant, il est important de garder à l’esprit que la Formule 1 demeure un univers imprévisible et complexe. Les prévisions de performances élaborées par le modèle seront donc formulées dans l’optique de minimiser les écarts en se fiant au schémas et corrélations entre les différentes features.
Le décor étant posé, nous allons à présent parcourir les différents services Sagemaker au fil du projet.
L’atelier : SageMaker Studio
SageMaker Studio est un IDE conçu pour la gestion des données, le développement, le déploiement, et la surveillance des modèles. Avec une interface unifiée regroupant la plupart des sous-services offerts par SageMaker, il a servi d’environnement de travail pour l’ensemble des tâches du projet.
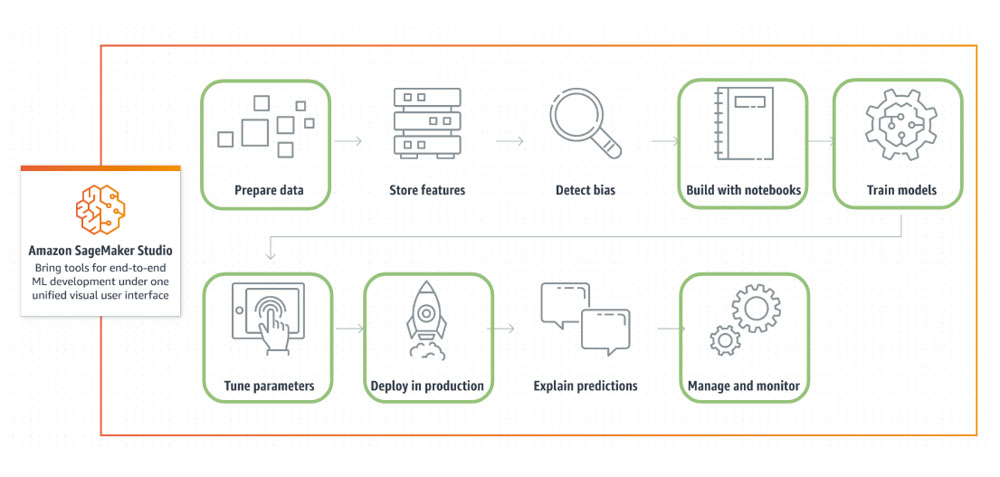
En vert : les étapes supportées et utilisées dans ce projet sur SageMaker Studio
Facturé en fonction du type d’instance et du nombre d’heures d’utilisation ( donc ne pas oublier de les éteindre ?!), ce service met à disposition un environnement “Ready-to-use” et scalable à la demande.
Par exemple, il est possible de développer des Jupyter notebooks*, gérer des pipelines ML & Data, explorer la Marketplace de modèles, connecter un gestionnaire de code, déployer un modèle, et bien plus…
*J’ai également eu l’occasion de découvrir le développement utilisant les Jupyter Notebooks, et je dois dire que j’ai été rapidement conquis !
Dans des implémentations à plus grande échelle, il permet également la possibilité de déployer des espaces de travail collaboratifs, ce qui facilite le partage de large volume de données, de code, d’environnement de développement et autres.
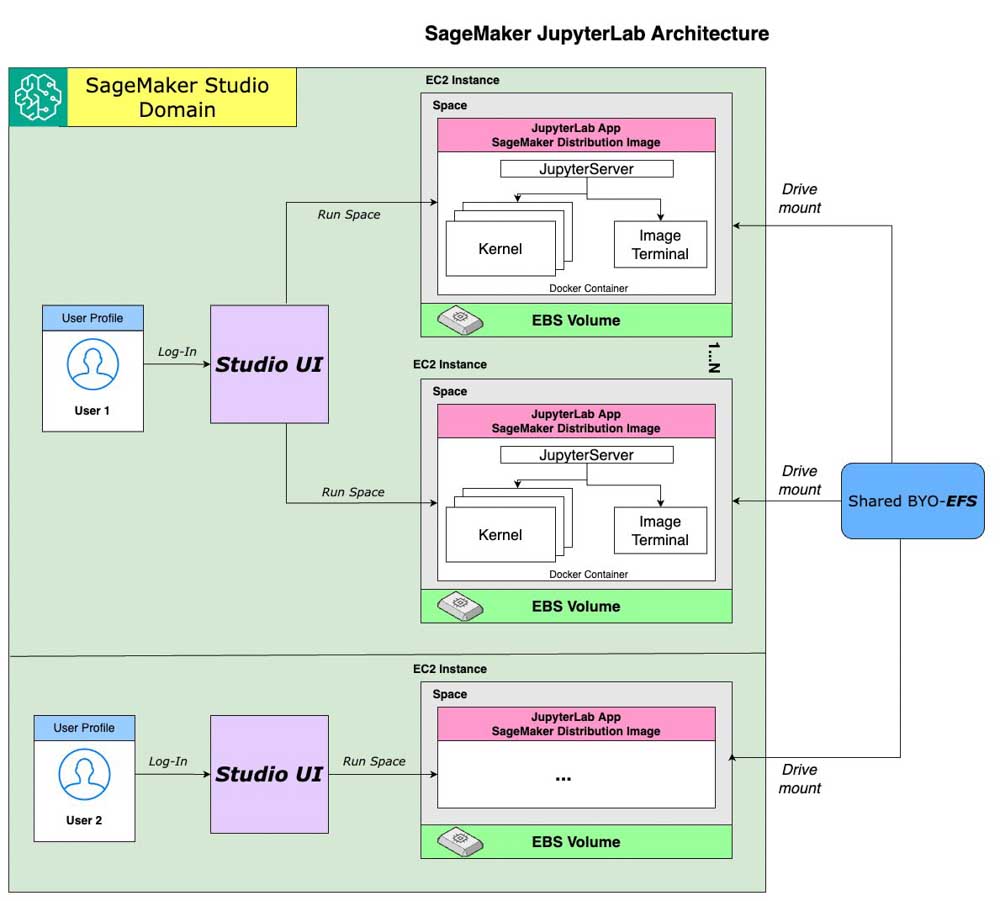
Depuis le 30 Novembre, il y la possibilité de monter automatiquement au lancement d’un instance Studio un EFS déjà existant.
La préparation des données
L’étape de préparation est essentielle pour que les données brutes soient utilisables pour l’apprentissage du modèle. Elle consiste à collecter, nettoyer, transformer, explorer, découper les données.
DataWrangler
DataWrangler est un outil qui propose une interface visuelle pour gérer l’ensemble du cycle de préparation de la donnée. De par son approche “no code”, il permet une ouverture plus grande auprès d’utilisateurs sans compétences avancées en programmation.
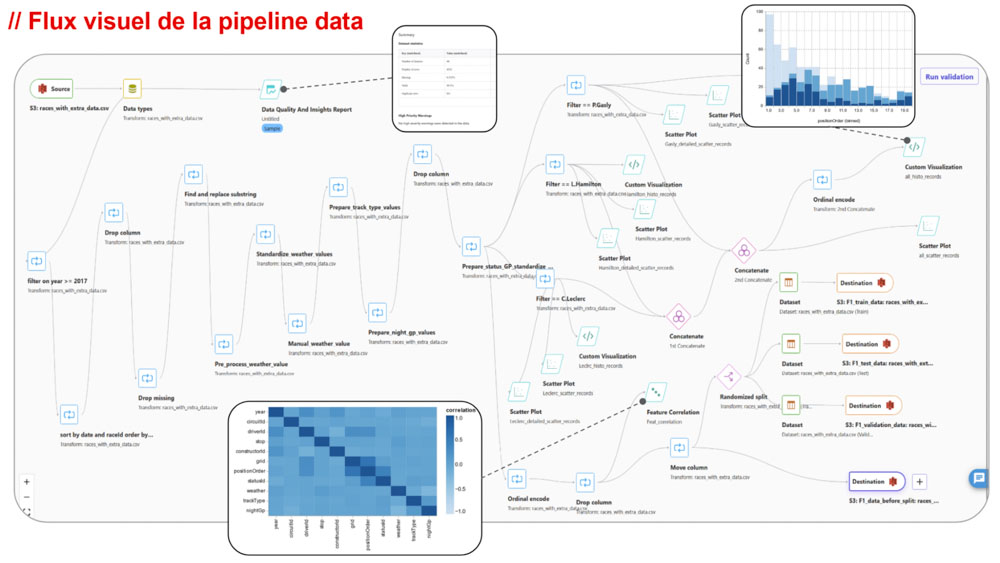
La préparation des données suit le mode opératoire suivant :
- Chargement des données brutes depuis S3
- Nettoyage des données
- Visualisation et analyse des données
- Extraction des features
- Découpage des données pour la phase d’entraînement
- Stockage des données prêtes à être utilisées
Datawrangler m’a également facilité l’opérationnalisation de ce flux. Tous les flux créés depuis l’interface peuvent être exportés sous forme de Jupyter notebook (python) et/ou transformés sous la forme d’une pipeline de transformation de données.
Bien que l’utilisation de ce service réduise considérablement le temps de l’analyse et de la préparation des données pour les non-initiés, il est important d’apporter un peu d’objectivité au tableau.
La simplicité a une limite ! Malgré la possibilité d’écrire des fonctions personnalisées dans certains cas, cela fonctionne avec un nombre limité de technologies et ce n’est pas toujours facile à réaliser.
Modélisation
La prochaine étape est la modélisation, cela consiste à sélectionner un algorithme approprié à notre scénario et à l’entraîner sur des données afin de créer un modèle. Généralement, 70 à 80 % des données sont utilisées pour l’entraînement, tandis que les 20 à 30 % restants sont dédiés aux tests et à l’évaluation des performances du modèle.
Cette phase intègre également des techniques d’optimisation des hyperparamètres* pour améliorer les performances du modèle.
*hyperparamètre: c’est un paramètre qui est utilisé pour configurer un modèle de Machine Learning. Contrairement aux paramètres du modèle, qui sont appris à partir des données d’entraînement, les hyperparamètres doivent être définis par l’utilisateur avant de commencer l’entraînement du modèle.
Training job
Nos données étant prêtes à être utilisées, nous entrons maintenant dans le cœur du machine learning : l’entraînement de notre algorithme.
SageMaker permet d’utiliser des algorithmes personnalisés mais parmi les algorithmes disponibles par défaut, il y en a un dont la réputation n’est plus à faire : XGBoost.
C’est un algorithme très polyvalent (régression, classification, classement), résistant à l’overfitting* , et très largement utilisé dans la communauté du Machine learning.
*overfitting : se produit lorsque le modèle affiche une très bonne précision sur les données d’entraînement, en correspondant très précisément à celles-ci. Cependant le modèle affichera des performances dégradées sur des données inconnues avant.
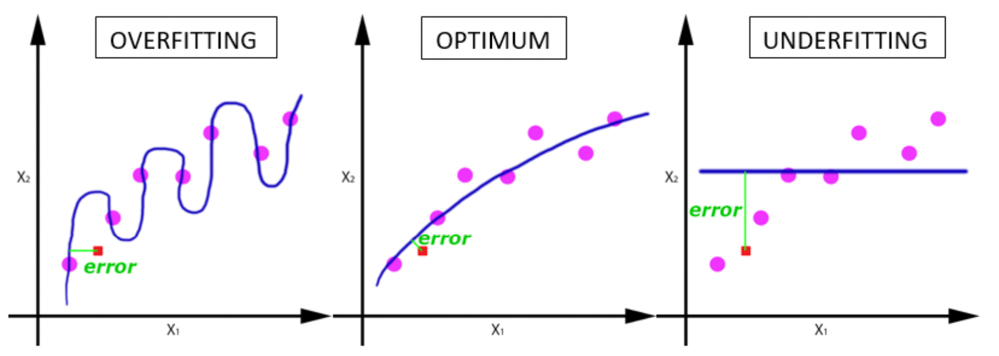
overfitting vs underfitting
Depuis diverses sources tel que votre Jupyter notebook, un script, la console, une pipeline le déclenchement d’une tâche d’entraînement se décompose en plusieurs étapes :
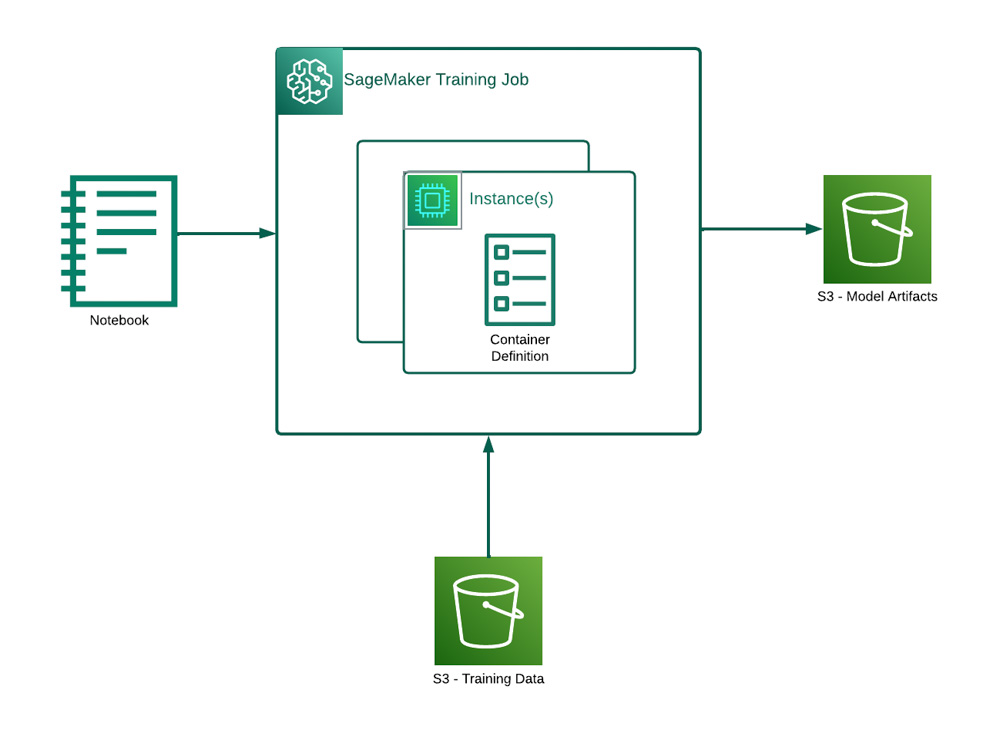
Sagemaker training job
- “Pull” image Docker de l’algorithme depuis un registre ECR public ou privé
- Transfert sur le container des données d’entraînement/validation depuis S3 paramétrés en entrée /opt/ml/input/data/[channel name]
- Exécution de l’entraînement
- Génération de l’artefact modèle dans le dossier du container /opt/ml/model et export sur le S3 paramétré
L’utilisation d’instances Spot pour cette tâche s’adapte particulièrement bien à ce cas d’utilisation, ce qui a entraîné une réduction significative des coûts d’entraînement, soit environ 50%.
En ce qui concerne la partie code, je dois admettre qu’elle est plus complexe à aborder qu’avec un outil comme Scikit-learn. Cependant, grâce au SageMaker training job, la puissance de calcul requise pour cette étape est dissociée de votre environnement de travail et tire parti des capacités de scalabilité des systèmes AWS…ce qui justifie amplement quelques lignes de code en plus.
On utilisera plus souvent la librairie SciKit en mode exploration au départ de notre projet, puis celle de Sagemaker pour l’industrialiser :
SciKit:
# Train an XGBoost regressor model
import xgboost as xgb
model = xgb.XGBRegressor(objective ='reg:squarederror', learning_rate = 1, max_depth = 20, n_estimators = 500)
model.fit(X_train, y_train)AWS Sagemaker:
# Set sagemaker estimator
Xgboost_regressor = sagemaker.estimator.Estimator(container,
role,
instance_count = 1,
instance_type = 'ml.m4.xlarge',
output_path = output_location,
use_spot_instances = True,
max_run = 500,
max_wait = 600,
sagemaker_session = sagemaker_session,
base_job_name='FormulaOnePredictor')
# Default value to start a first model estimator
Xgboost_regressor.set_hyperparameters(max_depth = 6,
objective = 'reg:squarederror',
alpha = 0,
eta = 0.3,
gamma = 0,
min_child_weight = 1,
subsample = 1,
num_round = 100,
booster = 'gbtree',
colsample_bylevel = 1,
colsample_bynode = 1,
colsample_bytree = 1)
# Creating "train", "validation" channels to feed in the model
train_input = sagemaker.session.TrainingInput(s3_data = s3_train_data,
content_type = 'csv',
s3_data_type = 'S3Prefix')
valid_input = sagemaker.session.TrainingInput(s3_data = s3_validation_data,
content_type = 'csv',
s3_data_type = 'S3Prefix')
data_channels = {'train': train_input,'validation': valid_input}
Xgboost_regressor.fit(data_channels)Hyperparameters tuning job
Le service de “tuning” du modèle offre une approche automatisée pour rechercher la combinaison idéale d’hyperparamètres, dans l’objectif de produire le modèle le plus performant possible.
Cette fonctionnalité s’appuie sur le mécanisme de “training job” pour orchestrer et paralléliser plusieurs tâches d’entraînement de l’algorithme. Chaque tâche est configurée avec des valeurs d’hyperparamètres distinctes définies automatiquement en suivant une stratégie (Bayésien, grille, aléatoire ou Hyperband), puis évaluées en fonction d’une métrique spécifique à l’algorithme.
Liste des hyperparamètres pour XGBoost sur AWS
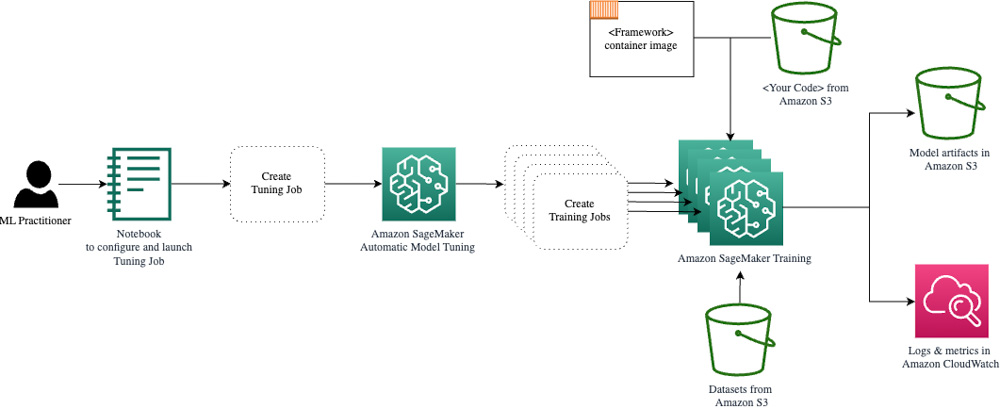
Un hyperparameter tuning job se décompose en une multitude de tâche d’entraînements parallélisé
Les stratégies de recherche des hyperparamètres
| Bayesian ( par défaut) | ||
| Quand l’utiliser : * Compute limité * Optimisation coûteuse * Large range continue | + Exploration et consommation efficiente + Recherche “intelligente” | – Processus complexe – Point de départ random |
| Grid search | ||
| Quand l’utiliser : * Faible plage de paramètres * Peu d’hyperparamètres | + Évalue toute l’optimisation possible dans les ranges configurées + Implémentation simple + Bonne reproductibilité | – Coût élevé – Inefficience sur de larges ranges d’hyper paramètres. |
| Random search | ||
| Quand l’utiliser : * Compute très limitées * Incompréhension des paramètres * Exploration du modèle | + Optimisation du temps et des coûts de tuning | – Efficience limitée avec un résultat variable d’un job à l’autre |
| Hyperband | ||
| Quand l’utiliser : * Compute limité * Optimisation coûteuse * Efficacité d’optimisation parallèles * Grand nombre d’hyperparamètres | + Rapide détection des bons paramètres + Allocation des ressources sur les bons modèles. | – Peut manquer de meilleures optimisations dans la création initiale. |
Les stratégies sont détaillées dans cette page AWS – How Hyperparameter Tuning Works.
Dans ce cas, j’ai utilisé la stratégie “Bayesian” pour ajuster les paramètres en se basant sur la métrique Mean Absolute Error qui nous retourne une valeur de performance dans la même unité que la prédiction que l’on souhaite obtenir. Dans un scénario de régression simple ou multiple on tend à réduire au maximum la valeur de la MAE.
Il existe plusieurs métriques fréquemment utilisées pour évaluer la performance d’un modèle traitant de problèmes de régression.
Le calcul de ces métriques s’effectue en comparant les prédictions générées par le modèle avec les valeurs réelles présentes dans les jeux de données de tests. Dans ce processus, nous disposons déjà des réponses attendues pour les données de test, ce qui nous permet de mesurer la précision du modèle en confrontant ses prédictions avec la réalité.
| Mean Absolute Error (MAE) | |
| + Interprétation dans la même unité que les prédictions + Résilient face aux prédictions aberrantes | – Perd en efficacité lorsque les prédictions affichent de grandes marges d’erreur |
| Mean Squared Error (MSE) | |
| + Pénalise plus fortement les grandes erreurs | – Sensible face à un trop grand nombre de prédictions aberrantes |
| Root Mean Squared Error (RMSE) | |
| + Pénalise mieux que MSE les erreurs faibles + Interprétation dans la même unité que les prédictions + Gère mieux que MSE les grandes erreurs | – Sensible face à un trop grand nombres de prédictions aberrantes (même si il est moins sujet à ce phénomène que le MSE) |
| R-Squared (R2) | |
| + Traduit la précision globale du modèle (entre 0 et 1),1 représentant l’ideal | – Perd son efficacité avec la présence d’un grand nombre de features indépendantes – Sensible face à un trop grand nombres de prédictions aberrantes |
Plus de détails sur les métriques d’évaluation sur le site neptune.ai .
Déclaration de code pour une tâche d’hyperparameter tuning job.
# Set list of hyperparameters range value as searching scope
hyperparameter_ranges = {'eta': ContinuousParameter(0.01, 0.3),
'alpha': ContinuousParameter(0, 9),
'max_depth': IntegerParameter(3, 10),
'min_child_weight': IntegerParameter(3, 9),
'subsample': ContinuousParameter(0.5, 1),
'num_round': IntegerParameter(50, 150),
'colsample_bytree': ContinuousParameter(0.5, 1),
'colsample_bynode': ContinuousParameter(0.5, 1),
'colsample_bylevel': ContinuousParameter(0.5, 1)}
# Creating a hyperparameters tuning job
tuner = HyperparameterTuner(Xgboost_regressor,
objective_metric_name = 'validation:mae',
hyperparameter_ranges = hyperparameter_ranges,
objective_type = 'Minimize',
max_jobs = 20,
max_parallel_jobs = 5,
base_tuning_job_name='Formula-One-Tuned-Predictor')Déploiement
Model endpoint
Nous disposons désormais d’un modèle entraîné et optimisé prêt à être utilisé pour générer les prédictions souhaitées. Comment le mettre en action ?
C’est là qu’intervient SageMaker endpoint, qui a pour fonction d’exposer le modèle afin de lui soumettre nos inférences*.
*Inference : désigne le processus d’utilisation d’un modèle préalablement entraîné pour effectuer des prédictions, des classifications ou des réponses.
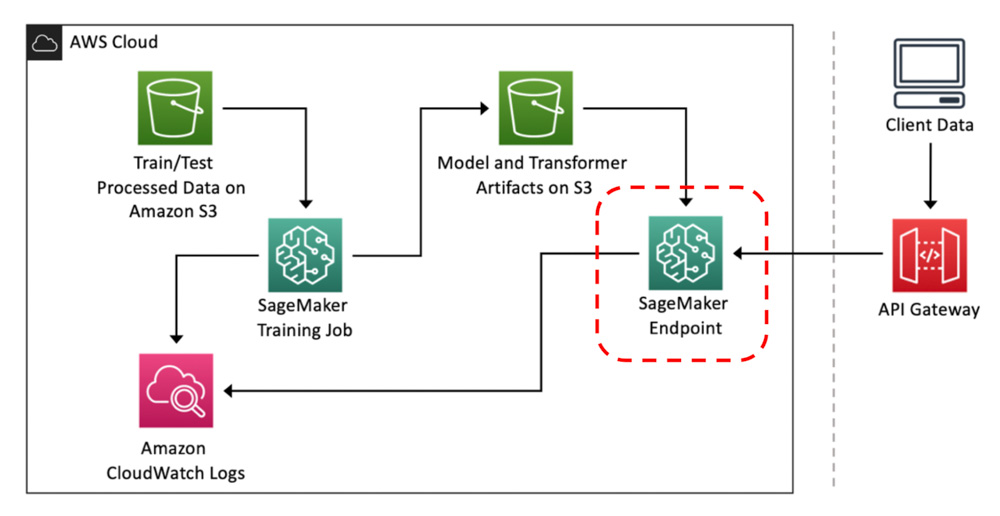
Sagemaker model endpoint “in situ”.
Avec Sagemaker endpoint, 4 types de déploiement de endpoint sont possibles :
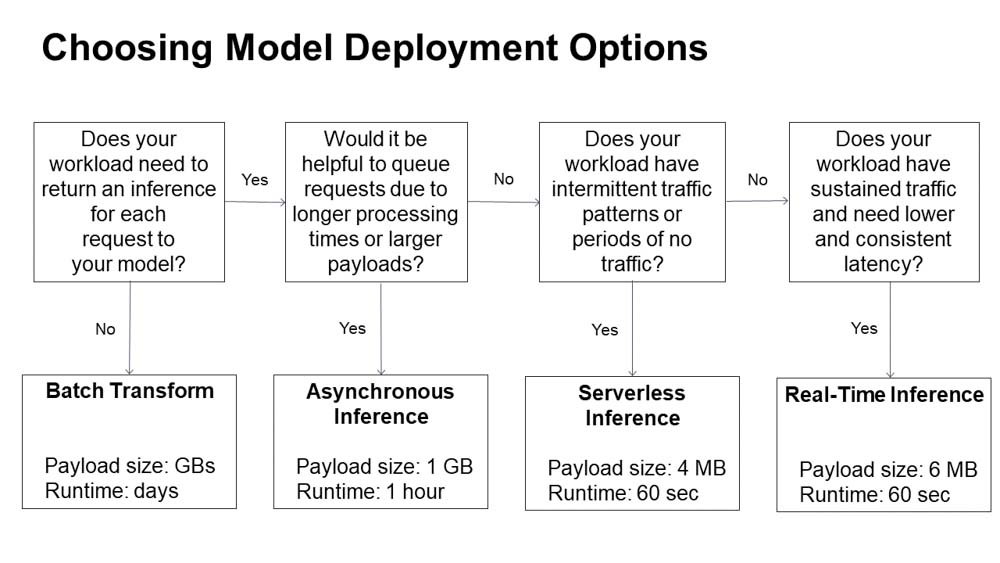
AWS propose ce diagramme d’aide à la décision
Dans un but de démonstration, j’ai procédé au déploiement de 2 endpoints serverless : le premier expose mon modèle avant optimisation et le second mon modèle “fine-tuned”.
Le premier déploiement était temporaire et avait pour vocation de définir une performance de référence. Grâce à cette base j’ai pu calculer l’amélioration (ou non) apportée par le tuning et modéliser graphiquement la performance du modèle final.
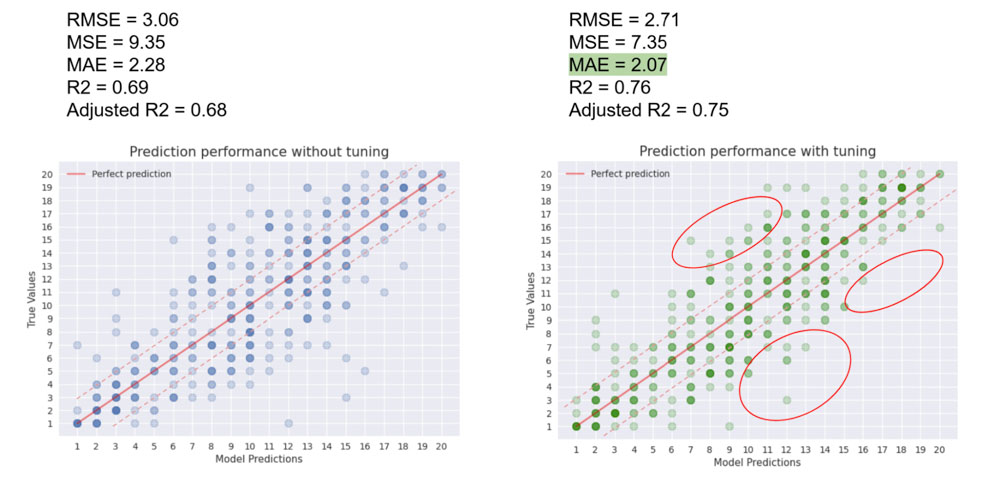
Ces deux graphiques représentent la modélisation faite sur des données inconnues avant et après la phase de tuning. On constate une légère augmentation de la performance, qui est en grande partie corrélée avec le temps alloué à la phase d’optimisation (dans mon cas 2h).
Exemple d’inférence du modèle final
inference_response = runtime.invoke_endpoint( EndpointName=endpoint_name, Body=b"2023,18,1,4,131,5,1,2,0,0", ContentType="text/csv", ) - Le paramètre body fournit la liste des variables en entrée au modèle:
- 2023 : l’année du GrandPrix
- 18: ID du circuit
- 1: ID du driver
- 4: Nombre de pit stops
- 131: ID de l’écurie
- 5: Place en qualification
- 1: Statut prévisionnel
- 2: Météo
- 0: Type de piste
- 0: GP de nuit
Plus simplement on souhaite prédire la réponse à la question suivante :
En 2023, durant le GP de Sao Paulo, qui se déroule sur circuit asphalte permanent de jour avec une météo de forte chaleur, le pilote Lewis Hamilton qui a fait 5e en qualification, qui n’a pas de problème déclaré (mécanique ou physique), qui court avec l’écurie Mercedes, avec une stratégies de 4 pit stops, quel sera sa position en fin de Grand Prix?
Réponse du modèle : 7
Lewis Hamilton a réellement fini avec la 8e position.
Autres exemples :
# inference for the 2023 Sao Paulo GP of Pierre Gasly
inference_response = runtime.invoke_endpoint(
EndpointName=endpoint_name,
Body=b"2023,18,842,4,214,13,1,2,0,0",
ContentType="text/csv",
)
12Pierre Gasly a réellement fini 7e grâce à une surperformance impressionnante ce jour-là.
# inference for the 2023 Monaco GP of Charles Leclerc
inference_response = runtime.invoke_endpoint(
EndpointName=endpoint_name,
Body=b"2023,6,844,2,6,3,1,4,1,0",
ContentType="text/csv",
)
4Charles Leclerc fini avec la 6e position.
La ligne d’assemblage
Sagemaker pipelines
L’automatisation, l’idempotence du processus et la standardisation du travail que j’ai présenté précédemment seraient la consécration parfaite ! Ce que je vous ai présenté jusqu’à présent représente des heures de travail considérables.
Lorsque la saison 2024 commencera, SageMaker pipeline me permettra de déployer et actualiser mon modèle rapidement, sans avoir à exécuter manuellement tous les notebooks Jupyter.
Ce service est tellement vaste qu’il mériterait un article à lui seul. Néanmoins, je vais le présenter brièvement avec l’architecture que j’ai mise en place pour ce projet. Cette configuration de pipeline est inspirée de toutes l’information et les exemples disponibles que j’ai pu découvrir dans le dépôt github d’exemple AWS SageMaker.
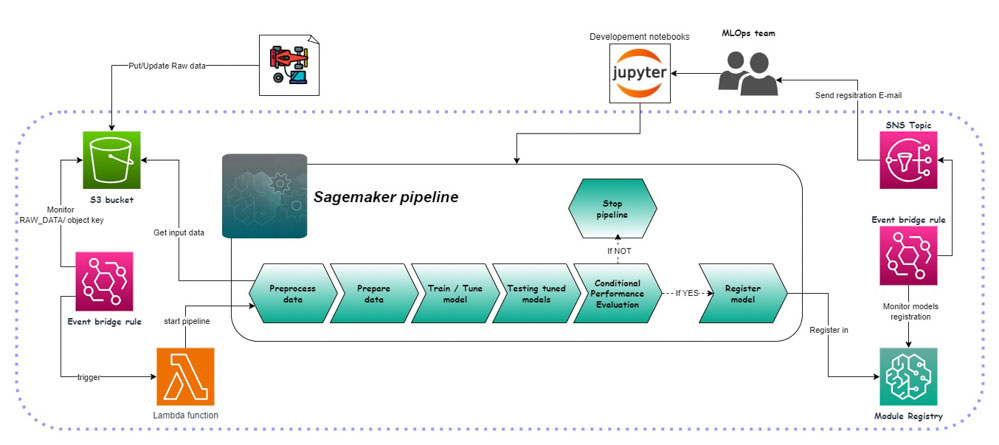
Les pipelines SageMaker permettent une personnalisation totale. Cette caractéristique constitue à la fois un atout majeur et un défi. Les possibilités sont vastes, mais tout doit être construit à partir de zéro. Chaque étape s’exécutant dans un container peut être définie par un jupyter notebook, un script python, boto3, ou d’autres méthodes selon les besoins spécifiques du projet.
Avec ce design « event-driven », dès qu’il y a un ajout de nouvelles données brutes sur S3, EventBridge et Lambda déclenche une nouvelle exécution de la pipeline. Lambda garantit qu’il n’y a qu’une seule exécution simultanée de la pipeline.
Après avoir entraîné et optimisé le modèle, la performance du modèle est évaluée pour garantir que le modèle final sélectionné sera le plus précis sur des données inconnues, parmi ceux créés durant la tâche de tuning. Cette étape n’est pas conventionnelle, je ne l’ai pas observé dans beaucoup de pipeline, mais il est implémenté ici comme garantie supplémentaire contre l’overfitting.
Ensuite, un autre test, cette fois-ci conditionnel, est effectué sur le modèle sélectionné. Une comparaison entre la Mean Absolute Error (MAE) du dernier modèle publié dans le registre et celle du modèle actuellement déployé est réalisée. Si le modèle sélectionné affiche une performance inférieure, il ne sera pas publié et la pipeline interrompue. En revanche si le modèle présente une précision supérieure il sera publié dans le registre et une notification par e-mail sera envoyé à l’équipe ML Ops et le nouveau seuil de publication mis à jour.
Conclusion
Nous arrivons au terme du travail d’exploration Sagemaker que j’ai mené (…pour l’instant) au cours de ces derniers mois. L’intégralité de mon code est disponible ici (gitlab revolve).
J’ai déjà quelques idées d’axes d’améliorations possibles autour de ce modèle :
- Features engineering : extraction de nouvelles features ou suppression de feature indépendante actuelle apportant de la complexité
- Hyperparameter tuning job : transition vers une stratégie d’optimisation de type “Hyperband”
- Algorithme : exploration d’autres algorithmes ou autres versions de l’algorithme actuelle
Pour aller plus loin dans l’architecture autour de l’industrialisation du modèle, la prochaine étape consisterait à construire une pipeline d’inférence du modèle pour une automatisation de bout en bout et simplifier l’invocation du modèle.
Cette exploration marque mes premiers pas dans l’univers de la Data/AI/ML. Pour accompagner cette introduction au Machine learning j’ai inclus différents liens tout au long de l’article qui m’ont été d’une grande aide dans la réalisation de ces travaux, pour toute personne qui serait intéressée d’en connaître davantage.
Issu de l’univers des sysops je serais ravi de recevoir vos feedbacks, sur mon code, les services présentés, etc.
Merci d’avoir pris le temps de lire cet article, en espérant n’avoir perdu personne en cours de route ! ?
Pour plus de détails sur le pricing de SageMaker, voir ici.
Commentaires :
A lire également sur le sujet :



