Le DevOps, une philosophie ou un métier ?

Salut ! ? Comme tu as pu lire sur la bio de l’article, moi c’est Jefferson, Cloud Engineer chez Devoteam Revolve. J’aimerais t’inviter à une petite aventure sur ces quelques pages. Ensemble, nous allons découvrir dans un premier temps la genèse du DevOps et les méthodologies qui l’ont inspiré (lean, agile, Toyota Kata…) . Ensuite, nous explorerons ses principes et pratiques, avant de parler du DevOps tel qu’il est aujourd’hui. Et tenter de répondre à la question : le DevOps, philosophie ou métier ?
Partie 1 : La genèse du DevOps
Le terme DevOps a été employé pour la première fois par Patrick Debois et Andrew Shaffer en 2008 lors d’une conférence sur l’agilité à Toronto. Il a été repris en 2009 lors de la conférence sur la vélocité par John Allspaw et Paul Hammond, dans leur présentation “10 déploiements par jour : la coopération entre les développeurs et les opérations sur Flickr” (je te laisse le lien de la vidéo, petit curieux ? “conférence sur la vélocité”).
On y découvrait la création d’objectifs communs entre les développeurs et les opérationnels, et comment ils ont utilisé les pratiques d’intégration continue dans le travail quotidien des ingénieurs. Le DevOps ne se veut pas juste une implication de l’équipe de développement et d’opérationnel. Nous y trouvons aussi, la QA (Quality Assurance), le product management, et la sécurité. Chaque partie joue un rôle important pour améliorer la vélocité de l’entreprise.
Patrick Debois, Gene Kim, Jez Humble et John Wills nous disent ceci dans leur livre The Devops Handbook : “Si les fondements du DevOps peuvent être considérés comme dérivés de Lean, de la théorie des contraintes et du mouvement Toyota Kata, beaucoup considèrent également DevOps comme la suite logique de l’aventure Agile du logiciel qui a débuté en 2001”.
Les différentes méthodologies et document qui ont conduit à la création du DevOps sont les suivantes :
- Le Lean management
- Le Lean startup
- Agile manifesto
- Toyota Kata
Le Lean management
Cette méthodologie a pris forme en 1940 lorsque Toyota a posé les bases du “Lean manufacturing”. Cette méthode d’organisation de travail possède deux principes fondamentaux : la conviction profonde que le délai de production requis pour convertir les matières premières en produits finis, constitue le meilleur indicateur de la qualité, de la satisfaction client et du bien-être des employés. Et l’autre principe clé souligne que la réduction de la taille des lots de travail est l’un des meilleurs moyens d’assurer des courts délais.
Les principes du Lean se concentrent sur la création de valeur pour le client à travers une pensée systémique, en établissant une constance dans les objectifs, en adoptant une démarche scientifique, en favorisant un flux continu plutôt qu’une poussée, en assurant la qualité dès la source, en dirigeant avec humilité et en respectant chaque individu.
Pour plus d’informations sur le lean management.
Le Lean Startup
Méthodologie fondée en 2008 par Eric Ries, elle avait pour principales cibles les startups. Avec les années, elle s’est étendue à tout type d’entreprise. Elle se base sur trois principes fondamentaux : construire, mesurer et apprendre.
Le but de cette méthode est de construire un produit minimum viable (Minimum Viable Product, aka MVP) que l’on pourra soumettre rapidement aux consommateurs. Pour construire ce MVP, elle reprend le principe du Lean management qui a pour but de produire en limitant le gaspillage et en augmentant la valeur de manière continue. Les entreprises peuvent ainsi apprendre des données collectées sur le marché à travers le MVP pour voir si le produit satisfait les besoins des utilisateurs. Pour cela, elles mettent en place des mécanismes de surveillance (monitoring) pour observer la valeur du produit sur le marché et agir au plus vite pour faire des changements.
Pour plus d’informations sur le lean startup.
Agile manifesto
Le manifeste Agile est créé en 2001 par plusieurs spécialistes du développement logiciel afin de lutter contre les longs processus de développement comme le Cycle en V ou le WaterFall. Le principe de base est d’organiser les équipes de développement pour qu’elles délivrent en 2 à 3 semaines plutôt que des mois après. Agile manifesto s’appuie sur quatre grandes valeurs, notamment :
- Les individus ont la priorité sur les processus et les outils.
- Les logiciels fonctionnels ont la priorité sur une documentation exhaustive.
- La collaboration avec le client est prioritaire sur la négociation de contrat.
- S’adapter au changement, a la priorité sur le suivi d’un plan.
Ce document a créé plusieurs méthodologies agiles qui amènent beaucoup plus de collaboration entre le client et l’équipe de développement. L’objectif du DevOps est de faire intégrer le client dans toute la chaîne de production, de la création du ticket à sa livraison en production.
Pour plus d’informations sur le manifeste agile.
Toyota Kata
En 2009, Mike Rother a rédigé un guide, avec pour intitulé “Toyota Kata : Managing People for Improvement, Adaptiveness, and superior Results”. L’essentiel de ce guide est basé sur l’humain. Le produit en lui-même ne suffit pas pour être concurrentiel sur le marché.
Il faut que ceux qui le réalisent aient développé une routine efficace pour que la solution puisse s’adapter à des situations imprévisibles. Pour ce faire, Toyota Kata recommande à l’organisation de mettre en place toutes activités qui aideraient les employés à développer leur créativité et cette routine. En pratiquant des schémas de façon régulière, les schémas deviennent une seconde nature, d’où le terme Kata. Un Kata est un terme d’origine japonaise qui représente une série de mouvements ou de pratiques systémiques conçus pour développer des compétences et des réflexes spécifiques. C’est une méthode d’apprentissage et de perfectionnement par la répétition régulière.
Nous venons de voir la genèse du DevOps ainsi que les grandes méthodologies de travail appliquées dans des industries comme Toyota qui ont permis sa création. Aujourd’hui, de nombreuses pratiques sont nées autour du DevOps, que nous allons explorer au travers de principes théoriques.
Ces principes ont été établis par Gene Kim dans son livre : “The Phoenix Project: A Novel About IT, DevOps, and Helping Your Business Win”. Ces trois principes sont :
- Le flux et la pensée systémique
- Amplifier les boucles de rétroaction
- Culture de l’expérimentation et de l’apprentissage
Pour plus d’informations sur le Toyota Kata, je recommande le livre “The Toyota Kata Practice Guide: Practicing Scientific Thinking Skills for Superior Results in 20 Minutes a Day” de Mike Rother.
Partie 2 : Les principes et les pratiques du DevOps
Premier principe : Le Flux et la pensée systémique
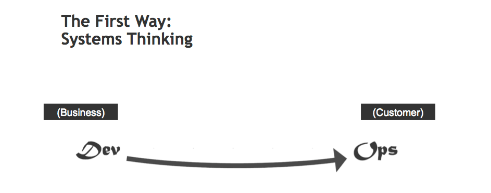
Source : Les trois voies : Les principes qui sous-tendent DevOps par Gene Kim
Ce principe concerne le système tout entier et pas seulement une partie : cela signifie que les développeurs ne doivent pas juste penser à implémenter les features, et que les opérationnels ne doivent pas juste regarder les métriques de leurs serveurs. Toutes les entités du projet doivent être incluses dans la chaîne, même le QA (Quality Assurance). Le but est d’accélérer notre chaîne de valeur de la gauche vers la droite : du développement vers les opérationnels jusqu’au client.
Pour effectuer cela, nous devons rendre notre travail visible, limiter le travail en cours, réduire la taille des tâches, et éliminer les pertes et les gaspillages. En d’autres termes, améliorer et accélérer le time to market du produit
Rendre notre travail visible
Contrairement aux industries ou aux chantiers du bâtiment, il est parfois complexe en informatique de visualiser la valeur produite par un individu ou une équipe malgré l’utilisation de gestionnaire de version comme Git. Le travail du développeur se déroule souvent sur son propre ordinateur, rendant difficile le suivi de son avancement par les autres membres de l’équipe. Afin de remédier à ce problème, il est impératif de fournir à chaque maillon de notre chaîne de production (management, développeurs, opérationnels, QA et la sécurité) la capacité de voir l’état d’avancement du travail réalisé ou à réaliser.
Une solution réside dans l’utilisation d’un tableau Kanban bien défini par exemple, pouvant être composé de quatre colonnes telles que To Do, In Progress, Test et Done. En adoptant cette approche, chaque membre de l’équipe peut avoir une vision claire et instantanée de l’état actuel des tâches en cours. Cette visibilité accrue facilite la gestion du projet, permettant une coordination plus efficace et contribuant ainsi à accélérer le flux de travail global.
Limiter le travail en cours
Imaginons une équipe immergée dans le développement d’un projet logiciel, utilisant un tableau Kanban structuré avec les colonnes To Do, In Progress, Test et Done. Un défi émerge alors : les développeurs inondent régulièrement de tickets la colonne Test, mais ces derniers peinent à atteindre la colonne Done.
Cette accumulation excessive génère des retards, ralenti le flux de travail et nuit à l’avancée du projet. La résolution de ce problème repose sur la mise en place de la notion de limitation du travail en cours. En fixant délibérément une limite au nombre de tickets autorisés dans chaque colonne, l’équipe est incitée à se focaliser sur un ensemble restreint de tâches à la fois.
Cette approche, en accord avec la philosophie de David J. Anderson, auteur du livre, « Kanban: Successful Evolutionary for your Technology Business », qui préconise « Stop starting, start finishing », encourage une collaboration au sein de l’équipe. Ensemble, ils identifient les points de blocage entravant le flux des tickets en attente. En restreignant le nombre de tickets dans la colonne du tableau Kanban, l’équipe parvient à éliminer les goulots d’étranglement potentiels, réduisant ainsi les temps d’attente et optimisant la productivité. L’effet qu’on peut constater est l’accélération significative du flux de travail global.
Réduire la taille des tâches
Considérons une équipe qui doit envoyer cinq brochures à un client. Chaque brochure doit être pliée, insérée, scellée puis timbrée avant envoi. La méthode courante utilisée est de terminer chaque étape pour les cinq enveloppes de brochure avant de les envoyer aux clients. Cette méthode a beaucoup été utilisée dans les industries traditionnelles.
Elle possède un gros inconvénient. Si à l’étape qui consiste à timbrer les enveloppes, on constate une erreur sur une enveloppe, il y a une forte probabilité que cette erreur ait aussi été répétée sur les autres enveloppes dans une des étapes précédentes. Parfois, il est compliqué de réellement détecter à quelle étape du processus l’erreur est survenue. Réduire la taille des tâches par le single piece flow vient pallier ce problème. Le but est de prendre une enveloppe, la plier, l’insérer, la timbrer et l’envoyer au client. Ainsi, si une erreur a été effectuée sur une enveloppe, on peut facilement remonter les étapes précédentes et corriger le défaut pour qu’elle ne reproduise pas sur les autres enveloppes.
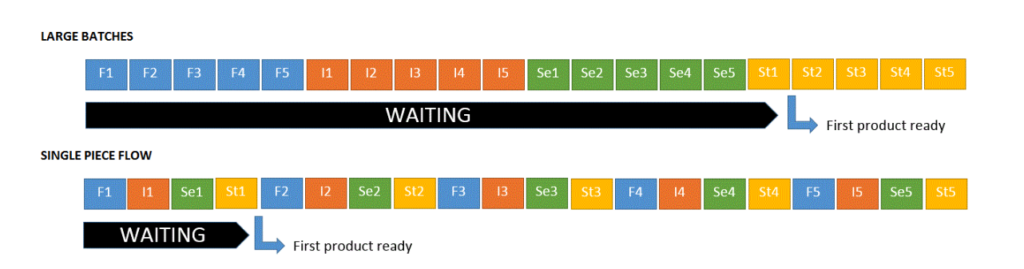
Source: Single piece flow
Le facteur temps est un gros avantage dans le single piece flow, comme illustré dans le schéma ci-dessus, Avec la méthodologie large batches, nous avons un gros temps d’attente pour avoir notre premier produit. Tandis qu’avec le single piece flow, nous avons un temps d’attente très court pour pouvoir manipuler le premier produit.
Expérience personnelle ? : dans un de nos projets interne, on rencontrait un problème sur l’avancée du projet dû aux tâches trop grosses et pas assez définies. Alors, nous avons fait un découpage en petite taille clair et précis de nos tickets. En suite, nous les avons répartis dans différents Milestones. Le travail est devenu plus fluide et rapide.
Éliminer les pertes et le gaspillage
Les pertes et les gaspillages dans un projet informatique sont tout ce qui empêche l’avancée du projet. Tout ce qui bloque la livraison des fonctionnalités aux utilisateurs finaux. Les pertes généralement rencontrées et à éviter sont les suivantes :
- Le travail partiellement terminé, d’où l’importance d’avoir une “Definition-of-Done” claire dans les équipes ;
- Les processus supplémentaires, notamment les attentes de validation non bloquantes pour passer aux étapes suivantes ;
- Les fonctionnalités en plus, parfois les développeurs ont tendance à vouloir ajouter des éléments sur des features demandées ; mes amis développeurs ? un petit coucou au principe KISS (Keep It Simple and Stupide).
- Les attentes de ressources, qui ralentissent le développement et freinent l’avancement du projet ;
En somme, ce principe a pour but d’améliorer le flux de travail, cela passe par plusieurs méthodes comme celles détaillées plus haut. Il en existe bien évidemment d’autres ; notamment, réduire le nombre de transferts (attente de validation, les réunions de coordination, etc) ou détecter les contraintes au sein du projet. Ce sont ces principes qui ont engendré la création des pratiques de travail que nous connaissons aujourd’hui. À savoir :
- L’intégration continue
- Les tests automatisés
- Le déploiement continu
- Le provisionnement et la maintenance des environnements de déploiement avec de l’infrastructure as code (IAC)
Deuxième principe : Amplifier les boucles de rétroaction
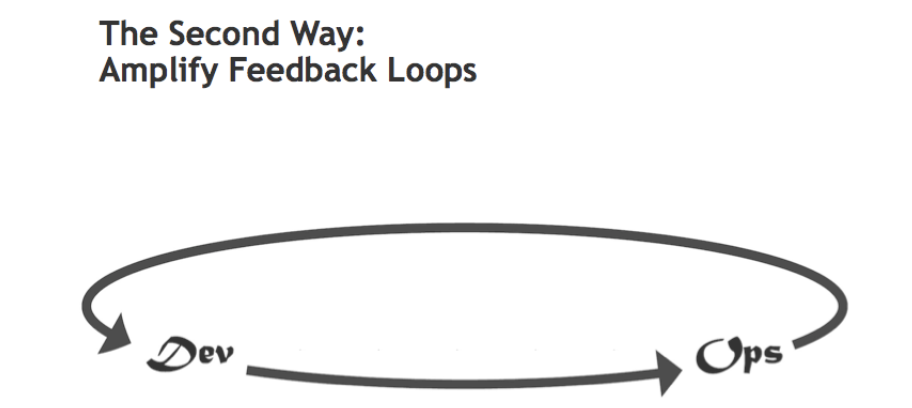
Source : Les trois voies : Les principes qui sous-tendent DevOps par Gene Kim
Lorsque j’étais jeune, mes parents avaient l’habitude de me dire “Il vaut mieux prévenir que guérir”. Pour faire une analogie avec nos systèmes informatiques, il est idéal de pouvoir détecter et corriger les erreurs en amont avant qu’elles ne se répliquent de manière catastrophique chez un client.
Nous avons vu que le but du premier principe est d’accélérer le flux de valeur de la gauche vers la droite. Celui du deuxième principe est de mettre en place des boucles de rétroaction rapides et constantes de la droite vers la gauche, toujours en impliquant toutes les parties du système. Ainsi les erreurs seront corrigées le plus rapidement possible.
Cela résulte en une meilleure compréhension des besoins du client, un système stable et fiable ainsi qu’un apprentissage rapide des erreurs commises. Afin d’obtenir ces résultats, il faut respecter les principes suivants : visualiser les problèmes au fur et à mesure qu’ils apparaissent, corriger les erreurs rapidement et construire de nouvelles connaissances, rapprocher la qualité de la source, et enfin faire de l’optimisation continuellement.
Visualiser les problèmes au fur et à mesure qu’ils apparaissent
Dans les méthodes de travail comme le Waterfall, on détecte les erreurs pendant la phase de test qui arrive après des mois de développement. À ce moment, un autre gros travail de développement doit être effectué et parfois le produit ne correspond plus au besoin du client ou au contexte actuel du marché.
Alors, il est nécessaire de tester continuellement notre système informatique afin de voir ses limites ou ses erreurs. Ensuite, faire des retours le plus rapidement possible aux développeurs pour qu’ils puissent corriger les erreurs ou changer le comportement de la fonctionnalité.
Une autre méthode pour avoir des retours sur le produit de notre organisation est de mettre en place de la télémétrie à chaque niveau de notre flux de travail. Les développeurs peuvent avoir par exemple le pourcentage de la couverture de leurs tests (ou coverage) ; les opérationnels peuvent avoir par exemple des retours sur le pourcentage de CPU utilisé sur les serveurs ; pour l’équipe marketing, il pourrait s’agir du nombre de clics effectués sur le bouton “ajouter au panier” sur un article précis. Grâce à la télémétrie, on peut facilement guider nos actions pour augmenter la vélocité.
Corriger les erreurs rapidement et construire de nouvelles connaissances
Refaisons un tour dans le monde de l’industrie automobile. Dans le livre The DevOps HandBook, les auteurs nous expliquent le cordon Andon de Toyota.
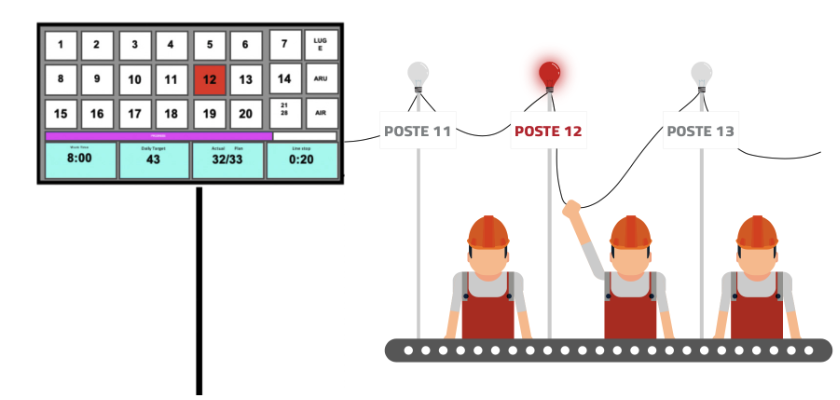
Source : Système Andon
En effet, dans une usine de Toyota, au-dessus de chaque poste se trouve une corde. Si une erreur survient dans l’un des postes, par exemple une pièce manquante, le responsable est chargé de résoudre le problème dans un temps bien déterminé. Si le problème n’est pas résolu, on tire le cordon et toute la chaîne de production est arrêtée pour aider à trouver une solution au lieu de contourner le problème et se dire “on reviendra quand on aura le temps”.
Nous sommes dans une ère de l’IT où on veut constamment produire vite pour être concurrentiel sur le marché. Si une erreur survenue n’est pas corrigée, il y a une probabilité qu’elle se reproduise dans le futur ou qu’elle affecte l’ensemble de notre flux de travail. Donc il serait idéal de corriger l’erreur le plus rapidement possible avant d’avancer. La correction rapide des erreurs apporte de multiples avantages :
- Elle empêche la propagation du problème en aval ;
- Traiter l’erreur immédiatement permet de minimiser l’effort requis pour sa résolution ;
- Elle nous permet de ne pas accumuler de la dette technique ;
La psychologue Jane Nelsen dans son livre La discipline positive dit, “L’erreur est une formidable opportunité d’apprentissage”. Lorsqu’on prend le temps de corriger une erreur, le plus important n’est pas de blâmer ou de juste trouver la solution : il faut mettre en place des mesures ou des pratiques pour qu’elle ne se reproduise pas dans le futur. Ainsi, les équipes de développement (ici, on parle bien de tous les rôles intervenant dans notre système informatique) pourront acquérir de nouvelles connaissances.
Les différentes pratiques que nous avons l’habitude de rencontrer qui sont liées au principe du feedback sont les suivantes :
- Mise en place des outils de monitoring d’infrastructure
- Automatisation de la gestion d’incident
- Collecte et l’analyse des données de performance
- Utilisation du toggle feature (pour plus d’information sur le toggle feature)
- Intégration du Hypothesis-Driven Development (HDD) et les tests A/B (pour plus d’informations sur le HDD et les tests A/B)
Troisième principe : Culture de l’expérimentation et de l’apprentissage
Source : Les trois voies : Les principes qui sous-tendent DevOps par Gene Kim
Maintenant, nous allons parler du troisième et dernier principe, le plus important selon moi. Ce principe se focalise sur la création d’un environnement d’apprentissage et d’expérimentation continu. Il permet la création de connaissances individuelles qui sont ensuite transformées en connaissance globale pour l’équipe. Les objectifs sont de valoriser l’apprentissage organisationnel, développer une confiance élevée entre les différents acteurs d’un projet, d’accepter les défaillances qui peuvent arriver dans un système et rendre acceptable le fait de parler des problèmes. Tout ceci pour créer un environnement de travail sûr pour tout le monde.
Ainsi, pour atteindre cet objectif dans une organisation ou système de travail, il faut :
- Favoriser l’apprentissage organisationnel et une culture de la sécurité : au lieu de chercher le responsable d’une erreur dans le système, nous devons nous focaliser sur la correction de l’erreur et une remodélisation de notre système pour éviter que l’accident ne se reproduise dans le futur.
- Normaliser l’amélioration continue du travail : lorsque nous évitons la résolution des erreurs ou du refactoring de code suivant des bonnes pratiques en utilisant des solutions de contournement, nous accumulons des dettes techniques. L’idéal est de réserver du temps dans le cycle de travail pour corriger des défauts, résorber les dettes techniques, refactoriser et éliminer les zones problématiques du code et des environnements.
- Transformer des découvertes locales en améliorations globales : en IT, nous devons créer des méthodes qui permettent de développer la connaissance globale des équipes. Par exemple faire et mettre à disposition de tout le monde un rapport sur une erreur survenue et avec sa correction (ou Post-Mortem). Ainsi, lorsqu’une personne tombera sur la même erreur dans le futur, elle pourra la résoudre plus facilement. Les rapports d’erreur doivent être partagés dans des repos ou des sources de données communs à toutes les équipes.
- Injecter des modèles de résilience dans notre travail quotidien : l’une des entreprises qui maîtrise très bien ce principe est Netflix avec la création de leur technique appelée le Chaos Monkey. Le but est de rendre nos systèmes plus performants en y injectant volontairement des erreurs. Ainsi, on peut voir les limites de nos systèmes et mettre en place des mécanismes pour les résoudre.
Pour aller plus loin sur la culture de l’expérimentation et de l’apprentissage, voir le chapitre 4 de la Partie I du livre The DevOps HandBook. Des explications plus détaillées y sont présentées avec des scénarios et des exemples. Vous pourrez encore mieux comprendre l’impact du troisième principe dans le travail quotidien des équipes IT.
Dans ce principe, nous avons vu quelques méthodes pour créer un environnement de travail sûr pour tout le monde. L’association de ce principe aux deux autres principes présentés plus haut n’améliore pas seulement la performance d’un système informatique, nous avons aussi une plus grande satisfaction au travail et une meilleure adaptabilité de l’entreprise. Nous rencontrons des pratiques autour de ce principe comme le Chaos Monkey que nous présenterons dans un autre article, ou le Gameday.
Partie 3 : Le DevOps aujourd’hui
Jusqu’ici, nous avons établi un historique de ce fameux concept DevOps, et nous avons vu ses principes et les pratiques qui en découlent. Bien que ce concept reste encore flou chez certaines personnes, il a créé une grosse révolution dans le monde de l’IT, des multinationales aux start-ups et en passant par les écoles de formations. Avant de voir cet impact, j’aimerais te présenter une entreprise que tu connais très bien qui applique les principes vus plus haut. Nous allons parler de Netflix principalement sur trois plans, la culture d’entreprise, la gestion des déploiements et la gestion de qualité.
Le DevOps appliqué chez les géants : Cas d’études Netflix
Allez ! Je ne vais pas te faire de grandes lignes sur les origines de l’entreprise, allons droit au but comme l’OM (Olympique de Marseille).
La culture d’entreprise
Netflix a une culture très orientée développeur, dont la collaboration en équipe et la responsabilisation sont les points clés. Netflix favorise la communication entre les personnes afin d’éviter des processus de synchronisation inutiles. Pour cela, Netflix concentre physiquement ses ressources humaines au même endroit.
Les développeurs sont responsabilisés sur leur code et ils doivent maximiser la qualité pour leurs pairs. Chaque équipe est directement responsable de la gestion de l’évolution de l’interface et ils publient directement en production (Trunk based developpement).
La gestion des déploiements
Une feuille de route est définie pour la livraison de code. Elle stipule que le code doit être build et testé localement en utilisant Nebula. Les modifications sont poussées sur un gestionnaire de version. Une tâche Jenkins build, test et package l’application pour le déploiement. Ces packages sont ensuite déployés avec Spinnaker, leur plateforme de livraison continue.
Il faut aussi noter que les équipes de développement et les opérationnels ont collaboré pour automatiser la construction d’une image AMI (Amazon Machine Image) pour permettre à chaque instance d’un service d’être identique.
La gestion de la qualité
Si tu t’es demandé pourquoi j’ai choisi Netflix, c’est parce que je pense que l’entreprise possède l’une des meilleures techniques de gestion de résilience d’un système informatique. On l’a vu de manière brève un peu plus haut. C’est le Chaos Monkey. Plus précisément, c’est un outil qui désactive aléatoirement des instances de machines virtuelles en production. Ce service est activé pendant un délai limité lors d’un jour ouvré dans un environnement surveillé par les ingénieurs responsables. Ainsi, ils configurent leurs services de manière à ce qu’ils soient résistants aux défaillances des instances. Au Chaos Monkey s’ajoutent le Latency Monkey, Conformity Monkey, Doctor Monkey, Janitor Monkey, Security Monkey, le 10-18 Monkey, Chaos Gorilla. Ensemble, ils sont appelés The Netflix Simian Army.
Pour plus de détails, je t’invite à lire cet article The Netflix Simian Army.
A noter : les sources utilisées datent de 2011 et 2016. Les processus ont pu évoluer au sein de l’entreprise.
L’impact du DevOps dans les métiers
Sur LinkedIn aujourd’hui, on compte en France environ plus de mille offres d’emplois avec l’intitulé “Ingénieur DevOps”. Waouh!!! C’est impressionnant, tu ne trouves pas ?

La question à se poser ici “Est-ce la bonne appellation du poste pour la mission et les compétences requises ?”.
J’ai effectué une analyse de plusieurs offres et les termes suivants sont récurrents :
- Développer et maintenir des pipelines CI/CD
- Infrastructure as code
- Connaissance sur Terraform
- Connaissance sur Gitlab CI, Github actions, Azure DevOps, Jenkins ou Ansible
- Connaissance en bash
- Savoir coder en python
- Connaissance sur Docker, Kubernetes, Aws, Azure ou GCP
Le DevOps a créé aujourd’hui plusieurs pratiques et outils qui répondent à des besoins au sein des entreprises, d’où la nécessité de rassembler ces pratiques sur une fiche métier en fonction du besoin, ce que je trouve intéressant et normal.
Demander à un développeur de faire ces tâches en plus de la conception et la réalisation de l’application peut être un travail énorme (alerte burnout ?). Pourquoi je prends l’exemple du développeur ? En fait, j’ai couramment entendu dire que l’ingénieur DevOps est le développeur qui viendra concevoir et mettre en place des pipelines CI/CD, mettre en place des outils de monitoring, gérer l’infra avec Terraform en plus de savoir coder et concevoir l’application. Dans une équipe, je pense qu’il reste intéressant que chaque personne possède un rôle défini. Les tâches effectuées par ceux qui travaillent comme ingénieur DevOps restent de vraies problématiques et le besoin est réel.
Cependant, je voudrais soulever un point sur le métier ingénieur DevOps. Chercher une personne capable d’appliquer ces pratiques n’est pas le réel défi. Le défi est de rendre l’organisation DevOps, c’est-à-dire permettre à l’entreprise de respecter les principes du DevOps. Je pense qu’il n’y a pas d’utilité à faire des pipelines CI/CD ou de l’IAC si les équipes n’arrivent pas à collaborer et à se comprendre. L’idéal serait d’avoir un objectif commun pour tout le monde. Les pratiques sont là pour nous aider à appliquer les trois principes, quel que soit le nom inscrit sur cette fiche métier (ingénieur DevOps, Plateforme ingénieur, et autres), nous devons d’abord identifier nos réels points de blocages avant de se lancer dans la mise en place d’un outil. Donc le problème ne réside pas réellement dans l’intitulé de poste, mais dans la compréhension même du DevOps.
Je te remercie d’avoir fait ce chemin avec moi, j’espère que tu as apprécié le voyage et appris des choses. Après cette lecture, j’aimerais te reposer cette question “Le DevOps, une philosophie ou un métier ?”. Je te laisse répondre en commentaire et/ou m’écrire directement sur LinkedIn pour qu’on échange sur le sujet.
Références
“The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations” De Patrick Debois, Jez Humble, Gene Kim, John Willis
“The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win” De Gene Kim, Kevin Behr, George Spafford
“Découvrir DevOps, l’essentiel pour tous les métiers” De Stéphane Goudeau et Samuel Metias
Commentaires :
A lire également sur le sujet :