
CLS Group : Industrialisation d’une plateforme ML Ops sur le Cloud avec Kubeflow

Suite à la mise en production d’une plateforme Cloud de traitement d’image, Devoteam Revolve a poursuivi son accompagnement chez CLS Group, pour une phase de collaboration visant à industrialiser le run de la plateforme sur Kubeflow.
Contexte
Durant le premier semestre 2022, CLS Group a construit, en collaboration avec Devoteam Revolve, une plateforme de traitement Data & ML basée sur Kubeflow, et l’a hébergée sur sa nouvelle Landing Zone Cloud. Sur la même période, un premier cas d’usage de traitement d’image a été migré sur cette plateforme.
La solution est basée sur un pipeline Kubeflow d’entraînement des modèles, avec un processus d’inférence pour chaque modèle créé. Ce processus itératif automatisé a notamment permis de multiplier par 4 la capacité de traitement des images.
Dans cet article, nous aborderons les sujets suivants :
- Kubeflow et son fonctionnement
- Construction et orchestration des pipelines Kubeflow
- Industrialisation et automatisation de la plateforme
- Monitoring et observabilité
- Intérêt de Kubeflow dans le contexte de projets Machine Learning sur Kubernetes
Kubeflow : le toolkit ML sur Kubernetes
Initialement conçu chez Google pour faciliter l’orchestration de tâches TensorFlow dans un cluster Kubernetes, Kubeflow est désormais un outil open source, multi-cloud et multi-plateforme permettant de faire du Machine Learning dans Kubernetes.
Kubeflow s’appuie sur la conteneurisation et le découplage en microservices pour former une plateforme portable pouvant s’exporter sur n’importe quel environnement capable de déployer un cluster Kubernetes (notamment les principaux cloud providers).
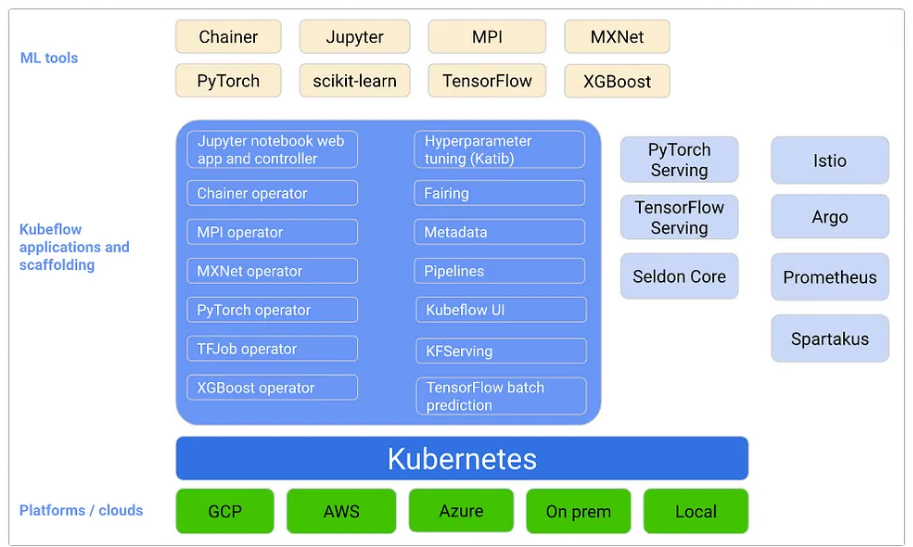
Figure 1 : Vue globale de Kubeflow
L’objectif premier est de rendre la mise à l’échelle des modèles d’apprentissage et leur déploiement en production aussi simple que possible. Pour cela, Kubeflow intègre plusieurs composants et outils open source qui prennent en charge les différentes étapes du workflow de data sciences, notamment :
- Kubeflow Notebooks, qui fournit des notebooks Python Jupyter aux data scientists.
- Kubeflow Pipelines, qui permet l’orchestration des pipelines ML.
- Katib, qui fournit un réglage des hyperparamètres sur Kubernetes.
- Seldon, qui est responsable du service modèle.
- Istio Service Mesh, qui gère et organise les interactions réseau entre tous les microservices.
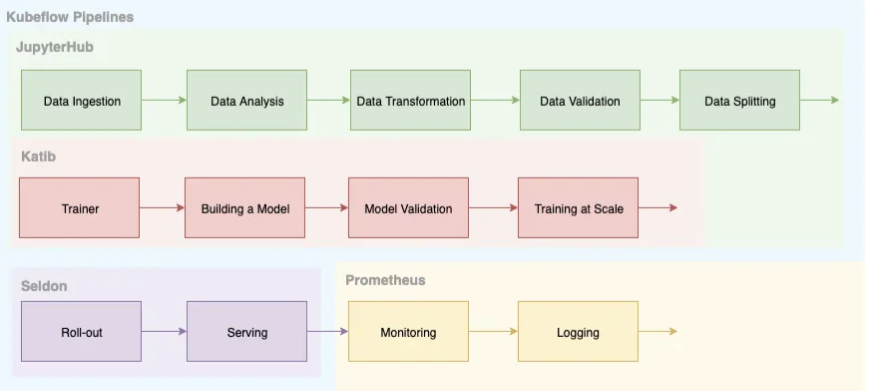
Figure 2 : Vue d’ensemble des pipelines Kubeflow
Il autorise également l’ajout de composants open source qui ne sont pas compris dans le package initial. CLS a choisi d’intégrer une brique MLFlow à sa plateforme pour gérer le cycle de vie ML et historiser les expérimentations.
Construction des KF Pipelines
Le service Kubeflow Pipeline fournit un SDK permettant de convertir un workflow ML en pipeline CICD. Pour être compatibles avec la plateforme, les étapes du workflow doivent être toutes indépendantes, c’est-à-dire que chacune doit être packagée et exécutable indépendamment des autres. Ces étapes sont ensuite organisées les unes par rapport aux autres pour former un Direct Acyclic Graph (DAG) intelligible par Argo Workflows.
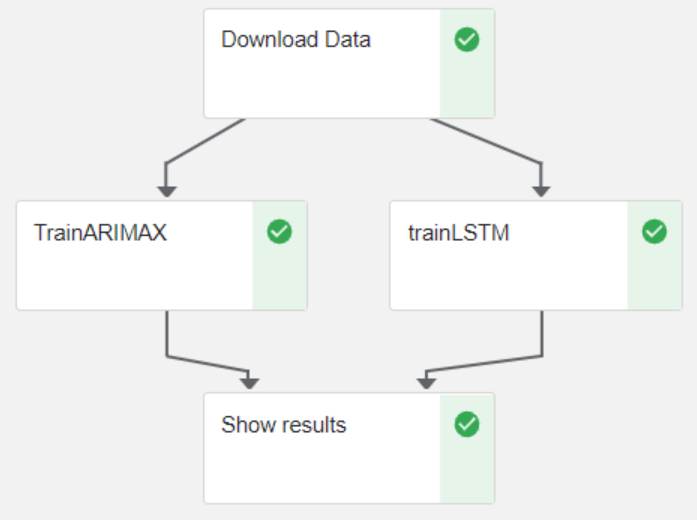
Figure 3 : Exemple de DAG
Chaque étape du workflow est définie, à l’aide du SDK de Kubeflow pipelines, sous forme d’un opérateur python.
from kfp import dsl
def preprocessing_op(....)Une fois toutes les étapes définies on les organise, pour faire correspondre les jeux de données produits avec ceux consommés, au sein d’une fonction Python décorée à l’aide de l’objet pipeline du SDK de Kubeflow pipelines.
import os
import kfp
from kfp.v2.dsl import pipeline
@pipeline(
name=os.environ["PIPELINE_NAME"],
description="Check the kfpc heartbeat"
)
def pipeline_func(....)Orchestration des KF Pipelines
Le SDK de Kubeflow pipelines dispose d’un compilateur qui permet finalement de convertir ce pipeline python en une structure de données intelligible par l’orchestrateur Argo Workflows.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: heartbeat-
annotations:
pipelines.kubeflow.org/kfp_sdk_version: 1.8.18
pipelines.kubeflow.org/pipeline_compilation_time: '2023-02-28T12:38:34.070087'
pipelines.kubeflow.org/pipeline_spec: '{"description": "heartBeat", inputs":[{"default": "{\"type\": \"manual\"}", "name": "trigger", "optional": true, "type": "String"}, {"default": "", "name": "pipeline-root"}, {"default": pipeline/heartBeat","name": "pipeline-name"}], "name": "heartBeat"}'
pipelines.kubeflow.org/v2_pipeline: "true"
labels:
pipelines.kubeflow.org/v2_pipeline: "true"
pipelines.kubeflow.org/kfp_sdk_version: 1.8.18
spec:
entrypoint: heartbeat
templates:
- name: exit-handler-1
inputs:
parameters:
- {name: pipeline-name}
- {name: pipeline-root}
dag:
tasks:
- name: heartbeat-model
template: heartbeat-model
arguments:
parameters:
- {name: pipeline-name, value: '{{inputs.parameters.pipeline-name}}'}
- {name: pipeline-root, value: '{{inputs.parameters.pipeline-root}}'}
[...]Figure 4 : Exemple de pipeline.yaml généré
Ce fichier yaml est en fait la définition d’une Custom Resources Kubernetes (CRD) nommée Workflow qui décrit entièrement le pipeline. On y retrouve la définition des étapes, les dépendances des tâches ou la gestion de la persistance des états.
Une fois définie, cette CRD est analysée par le contrôleur d’Argo Workflows et l’ensemble des ressources nécessaires à l’exécution du pipeline sont créées les unes après les autres.
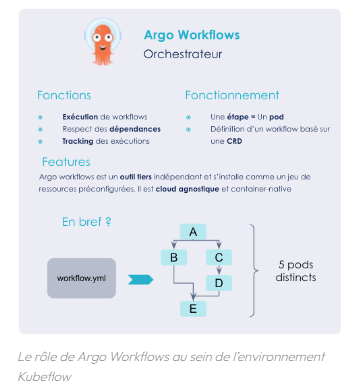
Figure 5 : Schéma d’explication du Argo Workflows
L’ensemble de ces éléments est versionné. Pour chaque ML pipeline, on stocke :
- les scripts python, les Dockerfiles ainsi que les fichiers de définition du pipeline de compilation du workflow dans un projet git dédié
- le fichier workflow.yaml généré dans un bucket S3 d’où il sera extrait par Kubeflow au Run du ML pipeline.
Déclenchement d’un KF Pipeline
Dans Kubeflow on parle de Run. En prérequis à la planification d’un run, il faut déclarer un pipeline et uploader le fichier pipeline.yaml source.
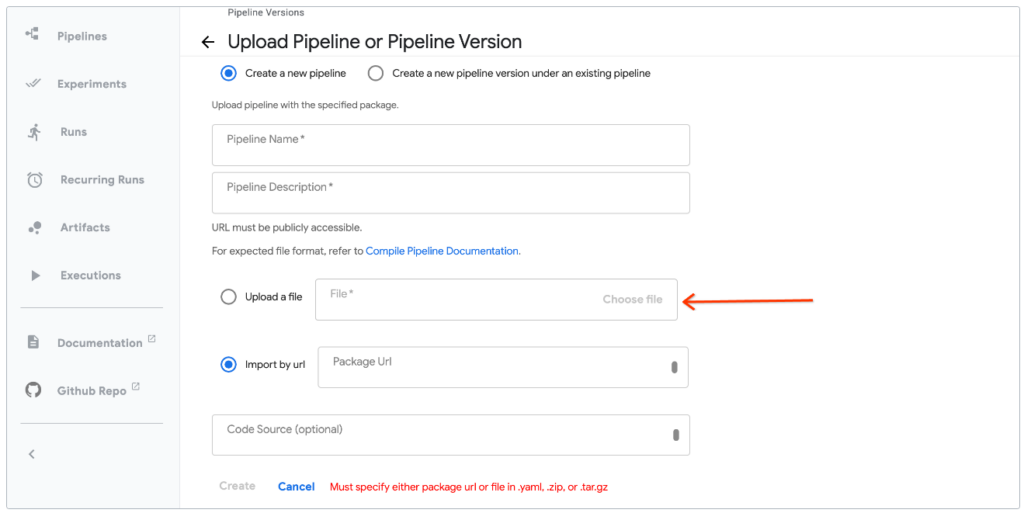
Figure 6 : Exemple de chargement d’un pipeline dans l’interface utilisateur de Kubeflow
Un run est une exécution unique d’un pipeline kubeflow. On peut répéter l’exécution de runs sur un même pipeline en utilisant des runs récurrents avec un déclencheur attaché.
Industrialisation de la plateforme
Avec le déploiement prévu de nouveaux cas d’usages, CLS souhaite industrialiser le déploiement et l’administration de la plateforme mais aussi assurer la disponibilité et la performance de ce service.
Automatiser le déploiement
Le projet PIAO ML de CLS compte jusqu’à 5 instances running de la plateforme en parallèle; trois environnements permanents et des instances bac à sable temporaires. Dans ce contexte, standardiser le déploiement devient indispensable.
Depuis la release 1.6, un package d’installation Terraform est disponible. Il permet de provisionner l’ensemble des ressources cloud indispensables au déploiement de Kubeflow ainsi que des ressources complémentaires, à sélectionner dans une liste d’addons.
A l’init du projet EOPC, la dernière version de Kubeflow disponible était la release 1.4. Cette version propose des manifests kustomize d’installation des différentes briques Kubernetes, mais pas de template de déploiement de l’infrastructure sous-jacente (Cluster Kubernetes, Compute, Stockage, …) ni des ressources cloud complémentaires (RBAC, Authentification, …).
Le déploiement de la plateforme a donc été automatisé from scratch. Terrafom est utilisé pour instancier les ressources Cloud et Kustomize permet d’appliquer les manifests Kubernetes. Un pipeline CI/CD unique a été construit pour automatiser le déploiement mais aussi le démantèlement complet de la plateforme. Ce pipeline principal est découpé en sous-pipelines gérant chacun une brique de la plateforme – objets Kubernetes et ressources Cloud liées.
Le déclenchement est manuel. Au lancement, on détermine l’action à réaliser : Deploy ou Destroy puis on précise si l’action sera appliquée sur toute la plateforme ou sur une brique seulement.
Ces pipelines sont stockés dans un repository Git unique. Chaque branche/tag du projet Git porte la configuration d’une instance de la plateforme. On peut ainsi piloter le déploiement, la mise à jour et le démantèlement de plusieurs instances Kubeflow en parallèle.
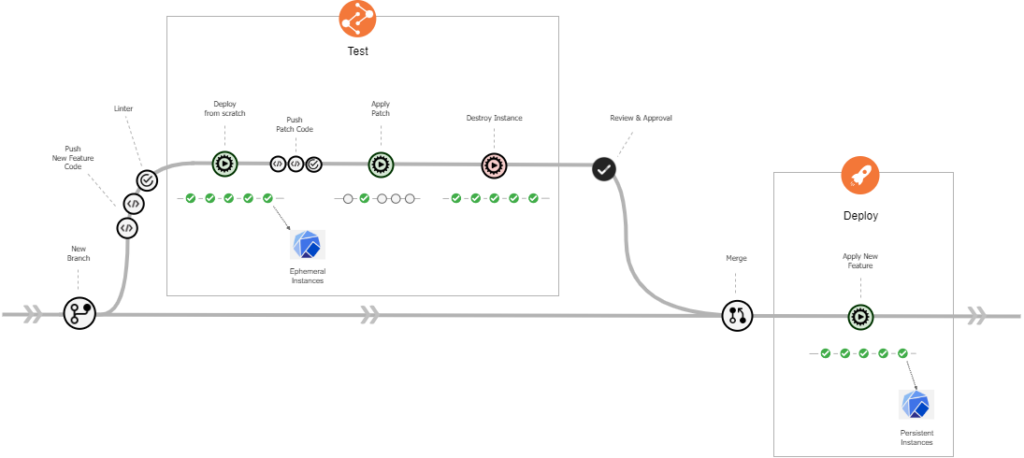
Figure 7 : Flow Git
La mise en place de ce pipeline de CI/CD permet de provisionner en quelques clics une nouvelle instance de la plateforme from scratch, mais aussi de déployer simplement une nouvelle configuration sur toutes les instances existantes.
Elle offre ainsi une garantie de cohérence des différentes instances à travers tous les environnements et assure de ce fait une compatibilité avec les pipelines de ML du dev jusqu’à la production.
Gestion des accès utilisateurs
Un pipeline complémentaire assure en amont la création d’un User Pool dédié à chaque instance dans le service cloud d’authentification utilisé ainsi que la déclaration des utilisateurs dans ce service. Ce pipeline gère aussi la suppression du pool d’utilisateurs une fois la plateforme définitivement démantelée, dans le cas des instances éphémères.
Initialement intégrée au pipeline de déploiement principal, cette brique d’authentification a été isolée dans un pipeline dédié. La dé-corrélation du cycle de vie de la plateforme et du pool d’utilisateurs associé permet aux utilisateurs de conserver leur accès à une instance même après une suppression et un redéploiement complet de celle-ci.
Les identifiants permettent aux utilisateurs d’accéder à l’interface Kubeflow. Cependant, l’accès aux différents services, qui composent la plateforme Kubeflow, l’isolation des utilisateurs, au sein de Namespaces individuels et de Namespaces équipes partagés, sont gérés au travers de la RBAC kubernetes.

Figure 8 : Exemple d’isolation d’utilisateurs
Basée sur des objets Kubernetes – Rôles, Namespaces, mais aussi polices Istio – cette gestion des accès est directement liée au cycle de vie de la plateforme. La RBAC est donc reconstruite, à chaque redéploiement de la plateforme Kubeflow, à partir de la liste des users définis pour cette instance dans le service d’authentification.
Plusieurs axes d’amélioration sont envisagés pour cette gestion des utilisateurs; l’une étant de s’affranchir de la CI/CD pour la gestion “quotidienne” des utilisateurs sur les plateformes pérennes, en utilisant la console du service d’authentification.
En effet, l’automatisation de la création des utilisateurs, qui apporte un gain évident lorsqu’il s’agit de peupler tout un pool d’utilisateurs à la création d’une nouvelle instance, devient vite un mécanisme fastidieux lorsqu’il est question de gérer l’ajout ou la suppression d’un seul utilisateur.
Reste la configuration de la partie Namespaces et RBAC de Kubeflow. Aujourd’hui basée sur une liste d’utilisateurs intégrée au pipeline de CI/CD, elle devra alors évoluer pour interroger directement le contenu du pool d’utilisateurs dédié à l’instance.
Monitoring de la Plateforme
Mise en oeuvre d’un KF pipeline : HeartBeat
Bien qu’il assure un déploiement réussi de l’ensemble des briques de la plateforme Kubeflow et de l’infrastructure Cloud sous-jacente ainsi qu’une configuration cohérente d’un environnement à l’autre, le pipeline de CI/CD ne garantit pas le bon fonctionnement de la plateforme de ML.
Dans cette optique, un Kubeflow pipeline nommé HeartBeat a été développé. Il permet de valider à intervalles réguliers, la disponibilité des principales fonctionnalités de la plateforme. Il est déployé par défaut sur l’ensemble des instances pérennes et peut être déployé à la demande sur les instances bac à sable, via le pipeline de CI/CD. Ce KF-pipeline est piloté par un cron job (Recurring Run).
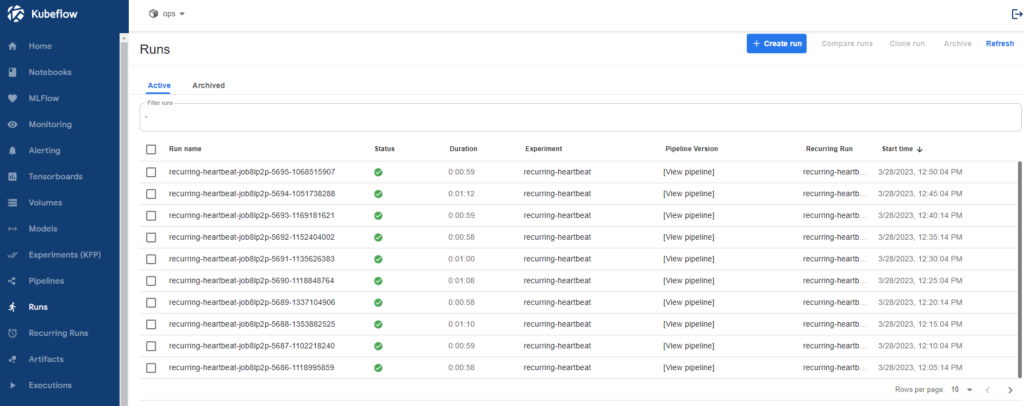
Figure 9 : Exemple d’exécution du pipeline HeartBeat dans l’UI Kubeflow
Le statut success/failed est envoyé dans Alert Manager qui va d’une part notifier les équipes sur des channel Microsoft Teams dédiés en cas d’incident et d’autre part exposer une API. Cette API interrogée par l’outil de monitoring Nagios permet d’intégrer le service PIAO ML au processus de surveillance centralisé de CLS : notification des équipes métier et suivi des incidents via Jira.
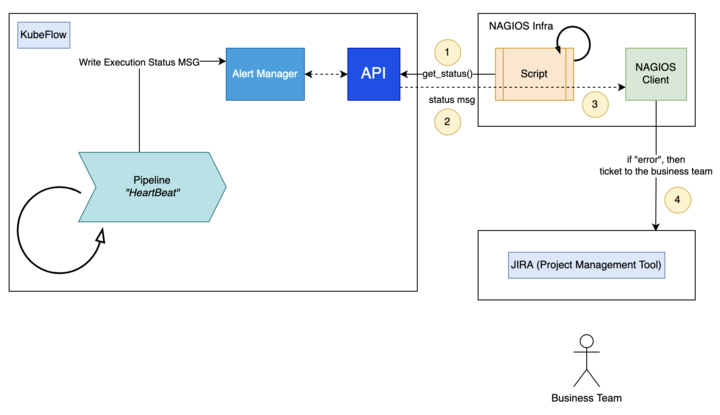
Figure 10 : Monitoring et Alerting HeartBeat
Observabilité de la plateforme : Dashboard Grafana
Le monitoring des performances de la plateforme est rendu possible d’une part par Kubeflow et Argo Workflows – qui traquent et enregistrent automatiquement les performances et les métadonnées associées à tous les pipelines d’entraînement – et d’autre part par l’environnement Kubernetes lui-même – qui offre une parfaite intégration avec des solutions de monitoring telles que Prometheus. Cependant, cette intégration des services de monitoring n’est pas prise en charge par Kubeflow, à ce jour, et leur configuration reste à la charge de l’administrateur.
En complément, l’utilisation de Grafana pluggé à la vue Dashboard de l’interface Kubeflow permet la construction de tableaux de bords qui restituent les métriques liés aux pipelines ML mais aussi des données plus générales permettant de mesurer la santé du cluster qui héberge la plateforme.
Un premier Dashboard Health a été mis en place pour suivre les métriques du pipeline HeartBeat.
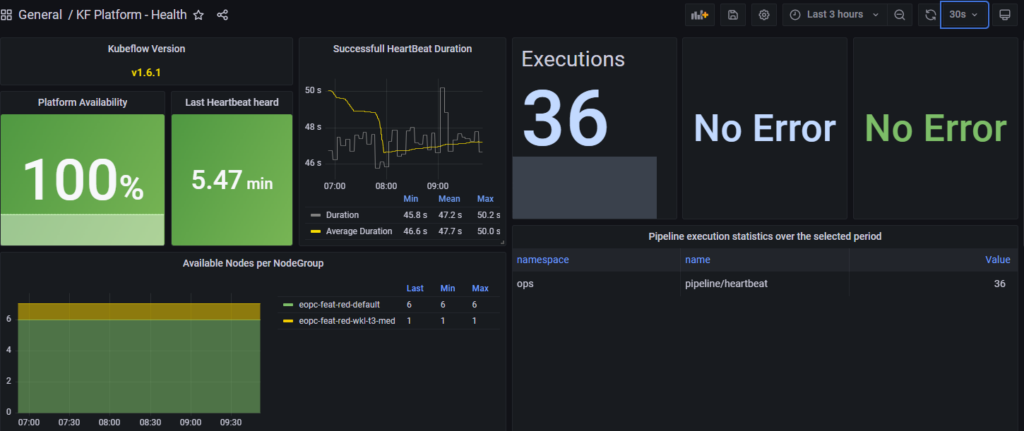
Figure 11 : General / Kubeflow (KF) Platform – Health – Grafana dashboard
Un second Dashboard plus générique, Pipeline Status, permet de consulter ces mêmes métriques pour n’importe lequel des KF pipelines déployé sur la plateforme.
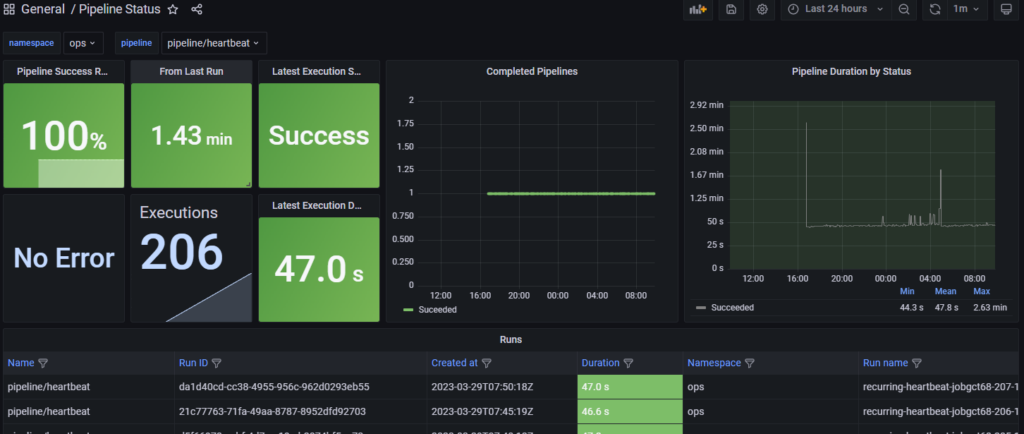
Figure 12 : General / Kubeflow (KF) Platform – Pipeline – Grafana dashboard
Enfin, plusieurs Dashboards de surveillance du cluster permettent de consulter entre autres la liste des pods du cluster, leur regroupement par namespace, leur répartition par nodes ou encore leur consommation de ressources.
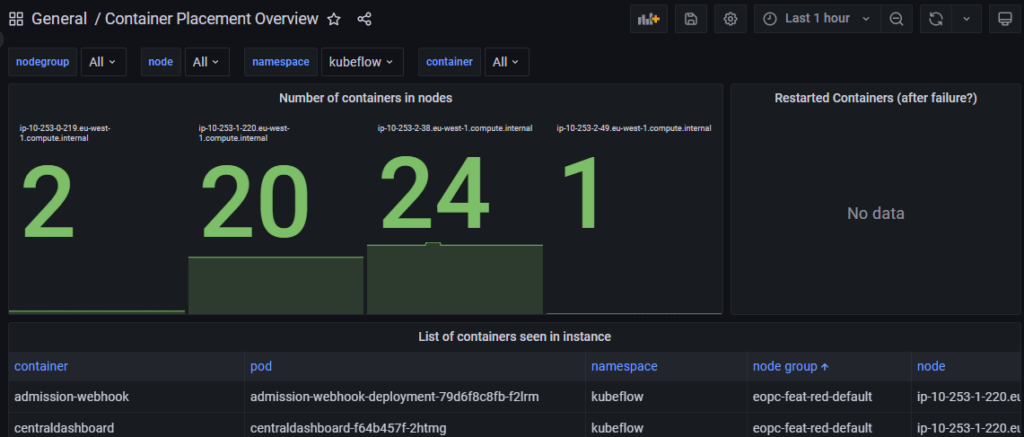
Figure 13 : General – Container Placement Overview – Grafana dashboard
Conclusion
La force de Kubeflow repose sur son versioning, sur le regroupement des expérimentations et sur l’orchestration de ses pipelines. Autre atout majeur : sa conception Kubernetes native lui permet d’exécuter en arrière-plan la gestion des ressources du cluster, permettant aux data scientists de se concentrer principalement sur leurs algorithmes.
Cependant, cette plateforme comporte un très grand nombre de briques logicielles différentes et interdépendantes dont les configurations sont parfois complexes à saisir dans leur ensemble. Pour donner un ordre d’idée, la plateforme PIAO ML en environnement DEV, pour son fonctionnement de base, c’est-à-dire en l’absence de tout ML pipeline en cours, ce sont 5 nœuds, 110 pods et près de 400 ressources tous types confondus.
En conclusion, Kubeflow est une boîte à outils très complète qui permet de faire du Machine Learning dans Kubernetes. Attention, toutefois, à ne pas sous-estimer les complexités sous-jacentes.
Bibliographie
Commentaires :
A lire également sur le sujet :




