Prime Video, from serverless to monolith : a retrospective

Prime video has declared in one of their article that they’re changing their infrastructure from serverless/microservices to monolith. This topic went viral on the internet and people quickly start saying nonsense about it, saying stuff like “Serverless is the biggest scam”, “I told you that monolith was the way to go”, this is why I think that it’s not bad if we take a step back, take a deep look at the subject and try to understand it better so we can form a solid opinion about it.
For this, we will do the following :
- We will start by explaining the problem that prime video was facing
- Then, we’ll take a look at the serverless/microservices architecture they adopted and why it costs so much in this particular use case.
- Explain why they decided to migrate towards a “monolithic” approach (Yes I did put monolithic between “” and you’ll see why)
- Share my opinion about the new architecture
- Conclude.

I) Problem
As we know, Amazon prime offers thousands of channel live streams to their customers (eg. HBO, NBA TV …) and they wanted to monitor those channel streams at a large scale (audio/video) so they can take real-time actions.
To make things clear, from the beginning, the problem wasn’t with the streaming but with monitoring those streams at a large scale. I keep emphasizing the word large scale because, as mentioned in this article, the challenge is not how to monitor one stream (or a couple of streams), they have already implemented their tool for that, but the real challenge is how to run this tool at a high scale.
“Our Video Quality Analysis (VQA) team at prime Video already owned a tool for audio/video quality inspection, but we never intended nor designed it to run at high scale”
II) Serveless approach — why did it cost so much?
Let’s start first by analyzing the architecture they used in the serverless approach:
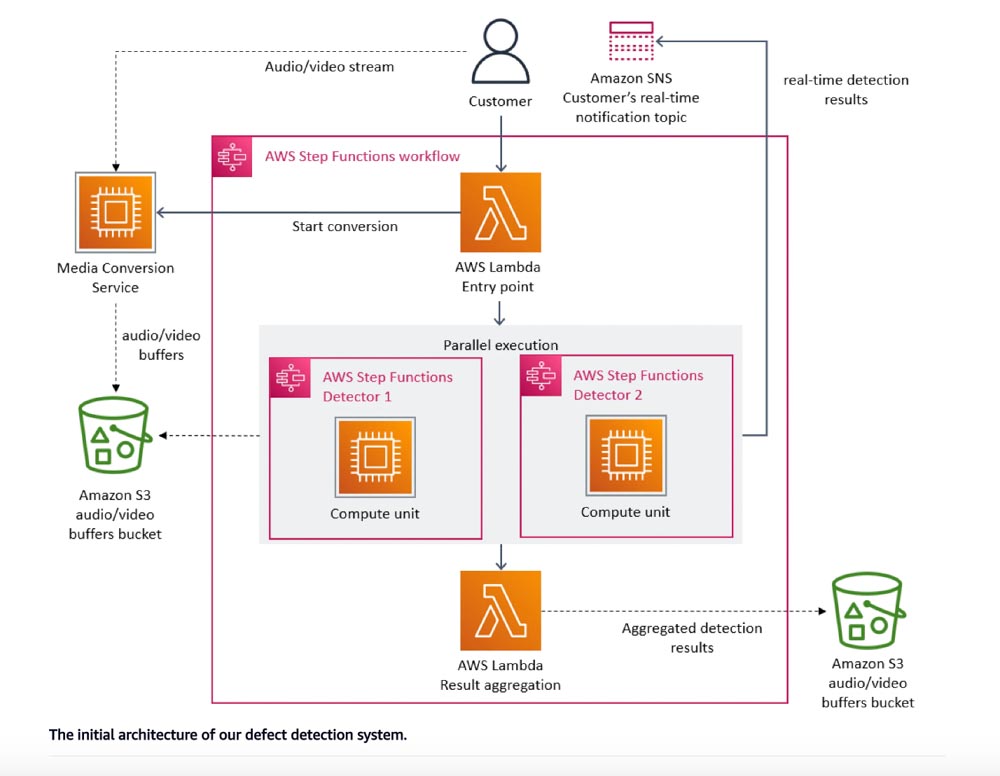
Let’s break down this architecture.
Basically, Amazon Prime used a serverless architecture composed of lambda functions and S3 orchestrated by AWS Step Functions. To make it a little bit clearer, this architecture is composed of 3 major components:
- Media Converter: This service receives the stream of data from the customer’s video and converts the audio and video into a format that can be used for analysis. It stores the converted data into S3 buckets for the next component to use.
- Defect Detectors: This component receives the converted frames and buffers from the Media Converter and analyzes them for any issues related to video or audio quality. It identifies defects such as freezes, block corruption, and audio-video synchronization issues.
- Orchestration Service: AWS Step Functions for orchestration that triggers the Media Converter and Defect Detectors as required. It also aggregates the detected results and stores them in S3 buckets for further analysis.
So to resume, an entrypoint lambda function starts the workflow, by triggering the Media Converter and Defect Detectors. Each computing result generated by those components is stored in S3 for data sharing/transfer between different components.
Okay, what happened then ?
At first glance, this architecture seems good and cool, but when we look deeper, this design has scaling bottlenecks and can quickly generate high costs and here’s why :
- Concerning the price, Standard step functions are very expensive, they charge you by state transition ($0.000025 per state transition). Taking into consideration that there are multiple state transitions being performed for every second of the stream, plus the different read/write/data transfers being done on the S3 bucket (which are not cheap also $0.021 per GB) and let’s assume that we have 100 streams, the price, I guess… can go out of control very quickly ???
- For the bottlenecks, AWS step functions can’t handle such a high number of state transitions/requests, as they said, they quickly reached account limits.
III) The solution
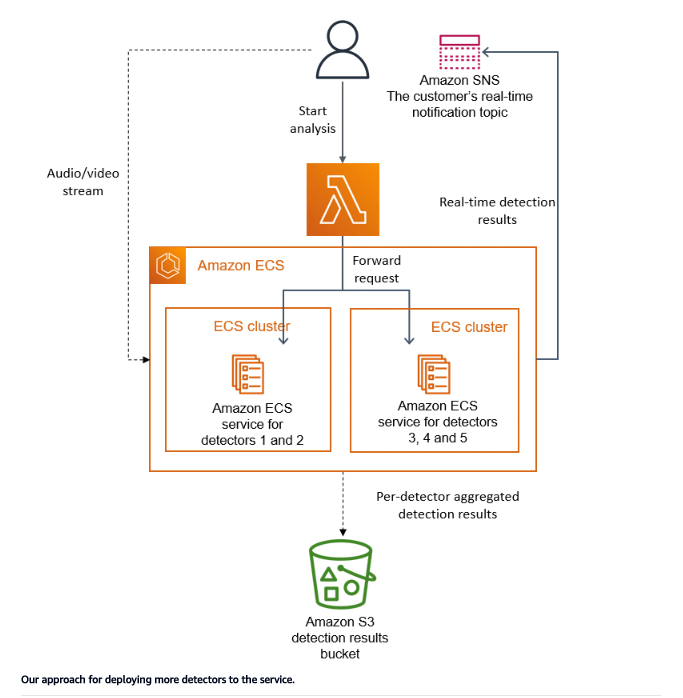
To solve these issues, the team opted for a simple solution, which is to move the distributed/separated system’s workflow to a single process that simplified the orchestration logic and kept the data transfer within the process memory since they used Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Elastic Container Service (Amazon ECS) instances for the deployment.
This helped them avoid the high costs generated by the step function orchestration, the data transfer on the S3 bucket level, and the scaling bottlenecks ( ECS/EC2 supports high scale since they can be scaled easily).
Here’s the new architecture:
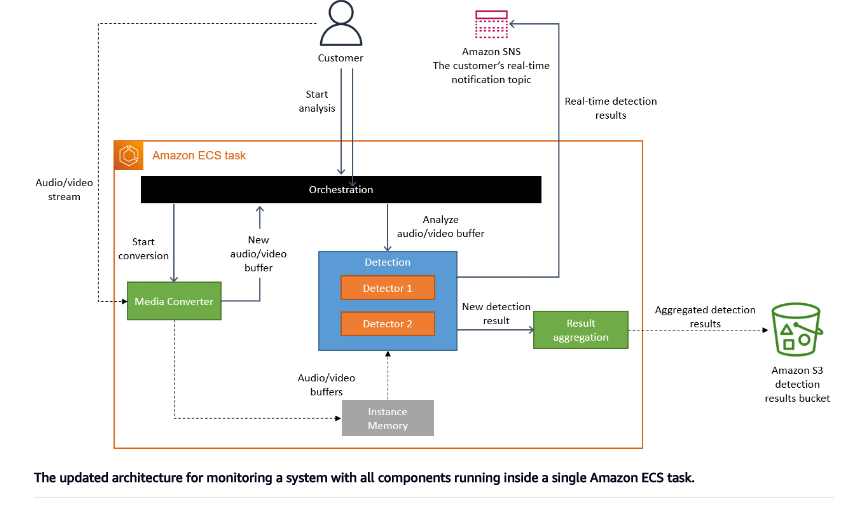
Actually, they didn’t change their initial code, they still have the same components used in the initial design (Media converter, detectors), this helped them reuse their code and quickly migrate to a new architecture.
So to resume, their new approach is to move their distributed workflow logic into a single process using Amazon ECS and EC2 instances. The S3 bucket, in this case, is only used to aggregate the results at the end of the process, and this is it, that way they reduced their costs by 90%
My opinion on this new architecture.
Even though this solution seems “simple” I can say that’s well-designed and solved the problems that they were facing. But let’s zoom in on it a little better.
The main components in these two architectures are the detectors, and in reality, they don’t only have 2 detectors but they have multiple detectors, and they’ll keep adding new ones. What’s worth mentioning here is that the scaling logic is based on them. They scale whenever they add a new detector.
In the initial design, we can see that each detector was in a step function apart, which means that they could scale horizontally, adding a new detector is basically creating a new microservice and plugging it into the orchestration.
Something like this:
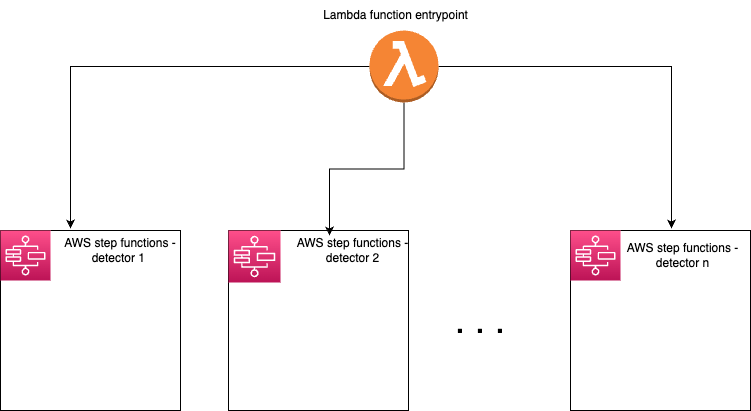
However, in the new architecture the scaling can only happen vertically. The more detectors they add in their code, the more resources they need to provide and as obvious as it may seem they quickly exceeded the capacity of a single instance.
What did they do then ?
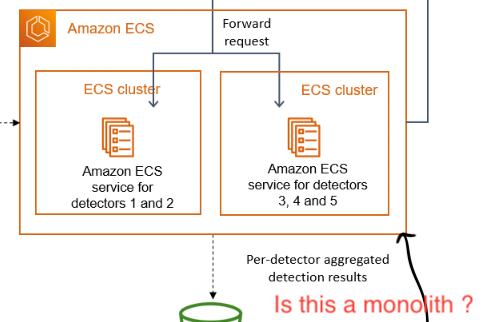
To address this issue they decided to regroup some detectors together, create a task for each group of detectors and deploy each task in its respective cluster. Based on parameters and an orchestration layer they have created they can distribute customers’ requests. If we illustrate this in a diagram we have something like this.
Is this a monolith ?
When I saw this, questions started to pop up in my head. If we zoom in on the ECS part of the diagram, doesn’t it seem to you like a microservices architecture? Is this really a monolith? I mean you have different detectors separated in different ECS clusters with parameters and orchestration layers? Maybe I am wrong but is it really a monolith? For me, it sounds more like a microservices approach and this is why at the beginning of the article I put the word monolith between “”.
Any other suggestions maybe ?
Is it true that step functions can be expensive since they charge you by state transition, but this is the case when choosing Standard step functions. In fact, when you create a state machine you can select a Type of either Standard or Express. The standard type charges you by state transition, as we have seen, but the express mode charges you by duration and memory conceptions and doesn’t take into account the number of transitions being made, plus this is an “on-host orchestration” which is something they’re looking for. This could have been a simpler solution, I don’t have enough information to really know why they didn’t do it.
Another point to add, I can’t understand why they didn’t use ECS Fargate instead of ECS/EC2, maybe they wanted to have full control over their instances but this will add more complexity (maintaining ec2) and price (price of EC2 instances)
V) To conclude
- So first of all, in system design there’s no “the way to go solution” there are only trade-offs, what works for this particular use case might not work for another use case. The prime team has specifically mentioned this : « We realized that distributed approach wasn’t bringing a lot of benefits in our specific use case« .
- Another point, in this particular problem, I feel that there are some misunderstandings of some concepts: microservices, monolith, and serverless. I am not gonna make a course about this, but serverless shouldn’t be compared with microservices but with server-based architecture instead. We can still run monolith on a serverless architecture.
Monolith and microservices are software architectures however serverless and server-based designs are infrastructure architectures. - Last point, please take your time to look at the problem, and try to understand it and its context before jumping to conclusions. This is really important if we want to grow technically.
Commentaires :
A lire également sur le sujet :