
IA responsable : quelles solutions pour réduire l’empreinte carbone des modèles ?

L’IA apporte des solutions à de nombreux problèmes, mais cela se fait aussi au prix d’une consommation énergétique accrue.
Nous verrons dans cet article un panorama des techniques existantes, concrètes, et faciles à mettre en place, pour rendre nos modèles d’IA moins gourmands en énergie, de manière à limiter leur impact environnemental. Nous aborderons les trois piliers de l’IA responsable : le monitoring, l’optimisation et le recyclage.
Cet article est fortement inspiré de la conférence “Réduction de l’empreinte carbone des modèles d’apprentissage automatique” présentée par Marc Palyart (Malt) à Dataquitaine 2023.
Monitorer
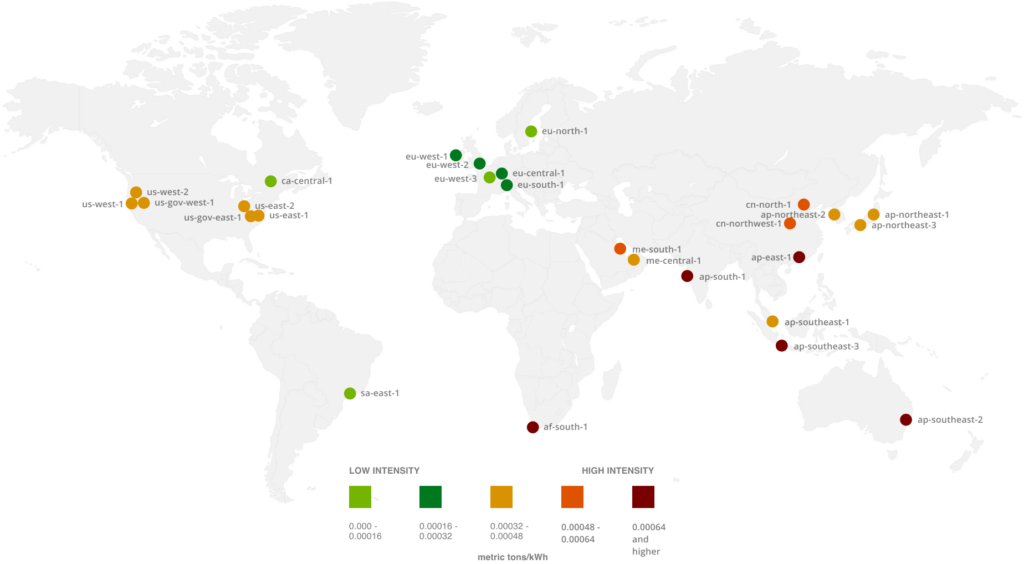
Impact des régions AWS en fonction de leur mix énergétique
Mesurer son impact en termes de bilan carbone est certainement la première chose à faire. Même si la démarche part parfois d’une obligation légale, cette quantification peut être source de prise de conscience dans l’entreprise. Monitorer va permettre de mesurer les améliorations qui ont été apportées, et le chemin qu’il reste à parcourir. Ces mesures peuvent venir compléter des KPI de performance existants.
Voici un petit listing d’outils qui permettent de le faire facilement :
- https://codecarbon.io/ : package python permettant d’intégrer dans son code le tracking de production de CO2, ou en tout cas une estimation de celle-ci.
- https://github.com/lfwa/carbontracker : package python pour le suivi carbone de modèles de deep learning.
- https://www.cloudcarbonfootprint.org/ : application de dashboard permettant de suivre la production de CO2 de son infrastructure cloud.
- Aws-customer-carbon-footprint-tool : service directement intégré à AWS. Pour l’instant les informations fournies sont encore limitées. Mais celà peut être une première étape avant de se tourner vers des outils plus complets.
Le calcul se fait généralement en partant des ressources consommées (CPU /GPU, RAM), de la consommation électrique associée, et du mix énergétique du datacenter. Bien qu’il ne s’agisse que d’une approximation, cela permet d‘identifier les facteurs les plus importants, et donc de concentrer nos efforts là où il y aura le plus d’impact.
De la même manière qu’il est possible de conserver ces mesures dans la partie monitoring infra, il peut être aussi intéressant de les intégrer dans le monitoring ML, ce qui permettra de mieux sensibiliser les data scientists (avec MLFlow par exemple). En mettant côte à côte les performances des modèles, et les consommations électriques associées, on peut commencer à réfléchir non plus seulement en termes d’efficacité, mais aussi en termes d’efficience.
Optimiser
Une fois les premières estimations faites, nous pouvons démarrer l’optimisation du système. Voici une liste non exhaustive des techniques d’optimisation les plus couramment utilisées.
- S’autoriser à concevoir des systèmes sans IA
En effet, il s’agit de la première règle du Machine Learning établi par Google: “n’ayez pas peur de lancer un produit sans machine learning” (Google, Machine Learning Rules). Comme c’est un sujet à la mode, on peut avoir tendance à en mettre un peu partout, sans que ce soit toujours pertinent. L’auteur nous propose de toujours se laisser la possibilité de remplacer les modèles prédictifs par des règles métiers simples, si elles suffisent à répondre au besoin, ou à même abandonner un projet dans le cas où la valeur ajoutée n’est pas évidente.
- Utiliser des modèles simples, peu gourmand en ressources
Dans beaucoup de cas des algorithmes ML classiques permettent d’obtenir de bons résultats, et il n’est donc pas nécessaire de faire appel à du deep learning. Et même dans le cas des algorithmes de deep learning, tous ne se valent pas en termes de consommation de ressources. Il est donc important de toujours comparer les performances prédictives rapportées aux performances énergétiques.
- Choisir la localisation des datacenters en fonction de leur impact environnemental
Dans certaines régions l’accès à des sources d’énergie verte est plus facile/développé. Elles ont donc un meilleur mix énergétique. Sélectionner une région en fonction de ces critères peut donc aussi faire partie du plan d’action. Attention cependant au transfert des données, qui lui aussi a un impact. Cela pourrait se révéler contre productif.
- Optimiser la recherche des hyperparamètres
Lors de la phase d’optimisation des hyperparamètres, plutôt que de tester de manière systématique l’ensemble des combinaisons possibles, il vaut mieux privilégier une recherche aléatoire, voire mieux, bayésienne. De nombreuses librairies permettent de le faire, comme Optuna par exemple. AWS SageMaker propose également une solution clé en main.
- Déployer des traitements batch
Dans bien des cas, un traitement en temps réel n’est pas nécessaire, et peut facilement être remplacé par un traitement batch. Un traitement en temps réel nécessite un endpoint qui soit toujours actif pour pouvoir répondre aux demandes. Lorsqu’une solution batch n’est pas possible, il reste la possibilité d’utiliser des solutions serverless, ou bien de gérer intelligemment le scaling de l’application.
- Utiliser du matériel performant
Les fabricants de matériel, prennent de plus en plus en compte les aspects de consommation d’énergie dans le développement de leur produits, en plus des performances de calcul. Il peut donc être intéressant de faire un peu de veille sur les nouvelles instances disponibles, de manière à pouvoir mettre à jour ses pipelines de traitement lorsqu’un nouveau processeur ou une nouvelle carte graphique est disponible. Par exemple, le passage d’une instance P4 (A100) à une P5 (H100) permet un gain de x6 sur le temps de training de GPT-3 (jusqu’à x30 pour les LLM), pour une consommation qui a été multipliée par 1,75 entre les deux versions. En terme d’efficience énergétique, on a donc un gain supérieur à x3.
- Utiliser du matériel adapté
Pour utiliser du matériel adapté à la tâche à réaliser, il faut trouver le meilleur compromis, comme avoir un bon ratio mémoire/puissance de calcul exemple. A noter que la meilleure configuration pour la phase de training sera souvent différente de celle pour l’inférence. S’il y a un doute entre plusieurs solutions matérielles, pourquoi ne pas faire un benchmark pour identifier les meilleures?
- Mettre à jour ses librairies
De la même manière, mettre à jour ses librairies régulièrement permet non seulement d’améliorer la sécurité de ses applications, mais parfois aussi de pouvoir bénéficier des dernières optimisations logicielles. Elles permettront d’exploiter au mieux le matériel utilisé.
Optimiser ses modèles
L’utilisation d’un framework de portabilité et/ou d’optimisation des modèles :
On peut citer ONNX qui est la référence en termes de portabilité des modèles de deep learning, TensorRT (Nvidia) et Openvino, qui facilitent la compilation pour des devices spécifiques, ou encore DeepSparse qui se concentre sur l’exécution CPU. Du côté des modèles à base d’arbres, on peut aussi citer Treelite, même si les gains seront moins significatifs que pour des modèles de deep learning.
Ces framework sont généralement utilisés pour déployer sur des infrastructures edge, avec des devices peu puissants, et avec de fortes contraintes en termes de consommation. Ce qui est souvent ignoré, est qu’il est aussi possible d’utiliser ces techniques d’optimisation dans des environnements plus classiques, comme dans le cloud, donc dans un contexte où les ressources ne sont en théorie pas aussi limitées. Sur AWS, SageMaker Neo permet justement de faciliter la compilation/optimisation des modèles, que ce soit pour les utiliser sur des instances cloud, ou dans un contexte de edge computing. Cette approche peut être assez rapide à mettre en place, et sans avoir de compétences particulières dans ce domaine.
Un modèle compilé pour le device cible sera généralement plus rapide, prendra moins d’espace mémoire, moins de ressources CPU/GPU. Sa taille réduite facilitera aussi son transfert par le réseau en cas de mise à jour, ainsi que son stockage. Les dépendances installées seront aussi généralement plus réduite.
Pour entrer un peu plus dans la technique, voici quelques-unes des techniques utilisées pour l’optimisation des modèles :
- Quantization/Réduction de précision
Une technique propre aux réseaux de neurones qui consiste à réduire le nombre de bits utilisés pour représenter les poids. On réduit donc la précision de calcul, en passant par exemple d’une précision de 32bits à 16bits, voire à 8bits. Ce qui va permettre un gain de temps lors de l’inférence, une réduction de la mémoire nécessaire, de la puissance de calcul et donc une réduction de l’énergie consommée. L’impact sur les performances en termes de prédictions peut être plus ou moins significatif. La quantization peut se faire après ou durant le training. La quantization post-training est plus courante et plus simple, mais a tendance à plus réduire les performances prédictives que la “quantization-aware training”.
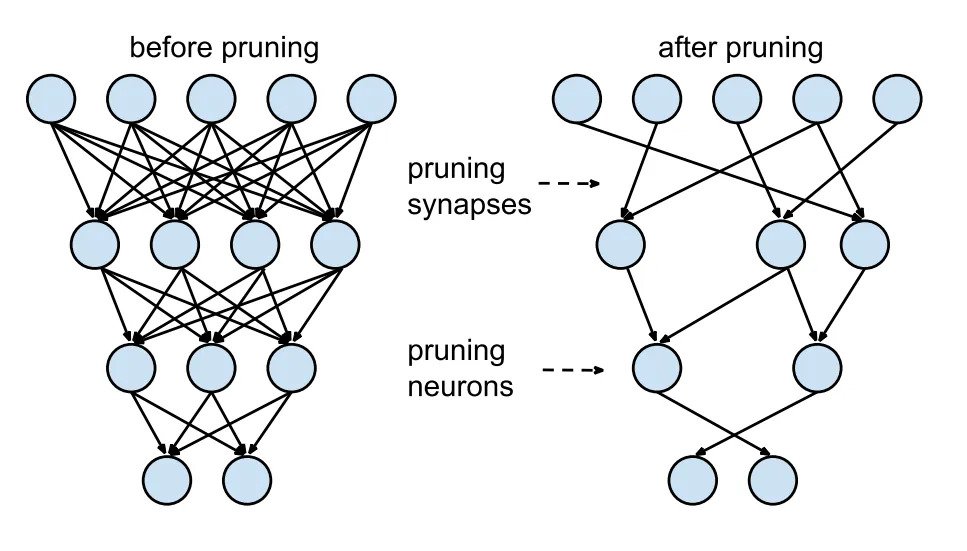
- Pruning
Optimisation du graphe par la suppression de certains neurones ou de certaines connexions qui ont le moins d’impact. De même pour les algorithmes à base d’arbres, il est possible d’élaguer certaines branches qui n’ont qu’un faible impact sur la prédiction.
- Optimisation des calculs en matrice creuse
Certaines librairies comme Neural magic optimisent ces calculs, de manière à pouvoir faire tourner de manière plus efficace des algorithmes sur CPU, au point de pouvoir se passer de GPU, et donc de réduire la consommation.
- Optimiser son code Python
Dans le cas d’un algorithme custom, il peut être intéressant d’optimiser son code python en utilisant une librairie qui va compiler les parties les plus gourmandes en ressource. Par exemple, on peut citer Numba qui permet de le faire assez rapidement, en ajoutant un décorateur à la fonction qui nous intéresse.
Recycler
De manière générale, la réutilisation des modèles va permettre de réduire le temps d’entraînement, ce qui entraîne une réduction de la consommation énergétique.
Elle peut prendre de nombreuses formes, dont en voici quelques-unes.
- Ré-entraîner intelligemment
On parle souvent de réentraînement automatique lorsqu’on aborde le sujet du ML Ops. Pour faire face aux éventuels drifts de données, le réentraînement offre souvent une solution simple à mettre en place, et dans la plupart des cas efficace. Cependant, il ne faut pas oublier que ces réentrainements vont consommer de l’énergie de manière récurrente. Il est donc primordial de bien concevoir cette partie, de manière à ne réentraîner les modèles uniquement lorsque c’est réellement nécessaire, et non pas de façon systématique.
- Mettre en place des caches
Dans le cas où certaines requêtes pourraient se représenter, un système de cache sur les prédictions permettra de réduire la charge sur l’endpoint d’inférence.
- Faire du fine tuning/transfert learning
Le principe est de prendre un modèle qui a été entraîné sur certain dataset, et de le réentraîner/l’ajuster à la cible qui nous intéresse. Le temps d’entraînement nécessaire s’en trouvera très fortement réduit. Il existe une pléthore de “modèles zoo” qui en proposent gratuitement, comme ceux de Hugging face, de Pytorch et Tensorflow pour ne citer que les plus connus.
- Faire du Zéro shot/ Few shot learning
Sous ces termes se regroupe un ensemble de techniques qui permettent de repousser les limites du transfert learning. Grâce aux nouvelles architectures de deep learning, il est maintenant possible d’entraîner des modèles performants avec très peu d’exemples. Cela veut dire moins de travail d’annotation pour les humains (avec toutes considérations éthique qui en découle), et moins de ressources énergétique consommé pour le fine tuning. Il est quand même important de ne pas oublier que l’entraînement du modèle source est quant à lui souvent très gourmand. Mais leur réutilisabilité compense largement ce défaut. C’est un investissement énergétique initial qui sera de plus en plus amorti avec le temps. On peut faire un parallèle avec la fabrication d’un panneau solaire ou d’une éolienne.
- Distiller ses modèles
Cette approche permet de réduire la taille d’un modèle. Et qui dit modèle plus petit, dit moins de calcul, et donc moins de consommation. Le principe est assez simple: on utilise les prédictions de notre modèle de départ (teacher) comme source d’entraînement pour un modèle plus petit (student). Ce principe de distillation est souvent utilisé sur les architectures modernes. Il est intéressant de noter que certains hub comme Hugging face propose des modèles déjà distillés. Dans ce cas, pourquoi ne pas les utiliser comme remplacement des modèles originaux, pour faire du transfert learning par exemple?
Comme vous pouvez le constater, ces techniques permettent non seulement d’optimiser la consommation énergétique, mais aussi souvent la vitesse d’inférence des modèles.
Comme les coûts d’infrastructure sont également réduits, il peut être intéressant d’intégrer ce type d’approche lors d’un projet FinOps. Lorsque les intérêts financiers sont alignés avec les intérêts écologiques, cela peut être un levier très efficace.
A lire également, notre compte-rendu sur l’événement Dataquitaine.
Commentaires :
A lire également sur le sujet :






