
Working with data files from S3 in your local pySpark environment

Even though AWS provides more and more resources and possibilities to work with your data in the Cloud, some people still feeling the need to work with their data into their local pySpark environment. The idea of this article / tutorial is to show how to do that and help you to understand what happens under the hood.
This article was written in collaboration with Fabien Lallemand.
Accessing to a csv file locally
With pySpark you can easily and natively load a local csv file (or parquet file structure) with a unique command. Something like:
file_to_read="./bank.csv"
spark.read.csv(file_to_read)Bellow, a real example (using AWS EC2) of the previous command would be:
(venv) [ec2-user@ip-172-31-37-236 ~]$ pyspark
....
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.3.1
/_/
Spark context Web UI available at http://ip-172-31-37-236.eu-west-1.compute.internal:4040
Spark context available as 'sc' (master = local[*], app id = local-1675094700680).
SparkSession available as 'spark'.
>>> spark.read.csv("./bank.csv")
DataFrame[_c0: string, _c1: string, _c2: string, _c3: string, _c4: string, _c5: string, _c6: string, _c7: string, _c8: string, _c9: string, _c10: string, _c11: string, _c12: string, _c13: string, _c14: string, _c15: string, _c16: string, _c17: string, _c18: string, _c19: string, _c20: string]
>>> exit()Here, the file is correctly converted as a Spark DataFrame.
However, this function does not work if you try to access the same file located in a S3 bucket.
In the following example, we copy our local file to an AWS S3 bucket and try to access it directly by changing the file name. we only configured our CLI with a aws configure command with nothing else.
In your bash environment, copy your file (bank.csv) to your personal bucket (here, the AWS S3 Bucket is named my-bucket-789):
(venv) [ec2-user@ip-172-31-37-236 ~]$ aws s3 cp ./bank.csv s3://my-bucket-789/bank.csv
upload: ./bank.csv to s3://mv-bucket-789/tmp.csv(As you can see, AWS credentials are correctly set up, otherwise the aws s3 cp would fail).
Now, if you try to directly access your S3 file from your local computer you will have to following error:
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.3.1
/_/
Using Python version 3.7.16 (default, Dec 15 2022 23:24:54)
Spark context Web UI available at http://ip-172-31-37-236.eu-west-1.compute.internal:4040
Spark context available as 'sc' (master = local[*], app id = local-1675100682884).
SparkSession available as 'spark'.
>>> file_to_read="s3a://my-bucket-789/bank.csv"
>>> spark.read.csv(file_to_read)
23/01/30 18:32:22 WARN FileStreamSink: Assume no metadata directory. Error while looking for metadata directory in the path: s3a://my-bucket_789/bank.csv.
java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.fs.s3a.S3AFileSystem not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2688)
....NOTICE: As you can see, we identify the file with a « s3a prefix ». Using a S3 prefix (as we usually do with the CLI) would generate an error:
'No FileSystem for scheme "s3"'Installation of the Hadoop-AWS module
When pySpark is installed in your environment, only the minimum necessary packages are already installed by default.
That’s, in order to access the AWS S3 Bucket from your pySpark environment you will need to install additional Hadoop module for AWS.
Dependency installation: The easiest and fastest way
To simply solve this error you will have to add an argument to your pyspark command.
The option --packages org.apache.hadoop:hadoop-aws:3.3.2 will automatically download and install (or load to the context if is already installed) the hadoop-aws dependency into your context, if you don’t have installed yet.
By default, you will find in your spark local installation (or python lib folder if you install spark with a pip install pyspark command).
These are the Hadoop jar files:
[ec2-user@ip-172-31-37-236 venv]$ find . -name "hadoop*"
./lib/python3.7/site-packages/pyspark/jars/hadoop-client-api-3.3.2.jar
./lib/python3.7/site-packages/pyspark/jars/hadoop-client-runtime-3.3.2.jar
./lib/python3.7/site-packages/pyspark/jars/hadoop-shaded-guava-1.1.1.jar
./lib/python3.7/site-packages/pyspark/jars/hadoop-yarn-server-web-proxy-3.3.2.jarThese modules are updated synchronously with the hadoop-aws jar file. Consequently, it could be a good idea to keep the version syncrhonised as well.
However, if you want get the latest version of this module you can refer to maven repository.
Notice You will have to use the argument everytime you will launch the pyspark if you want to manipulate S3 file. Something like:
pyspark --packages org.apache.hadoop:hadoop-aws:3.3.2Dependency installation: THE HARD WAY
If you want to simply launch you pyspark with a command pySpark, you will have to manually download and deploy the jar file.
To do this you need to determine the version of the module you want to download.
This can be accomplished by looking for the lib hadoop-client-api-X.Y.Z.jar as defined the previous chapter.
1. Get the version to install
The following example, show you how to achieve it, in the case you install pySpark in your python environment (with pip install pyspark for example).
Inside of your Python environment, go to the site-packages folder and search inside of the pyspark/jars the Hadoop client version:
cd venv/lib/python<YOUR_PYTHON_VERSION>/site-packages/pyspark/jarsls hadoop-client-*Output:
hadoop-client-api-X.X.X.jar hadoop-client-runtime-X.X.X.jar(where X.X.X is the version that is installed).
2. Download the package from MAVEN repository « hadoop-aws »
Go to https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-aws Select the correct version (based on what you discovered previously):
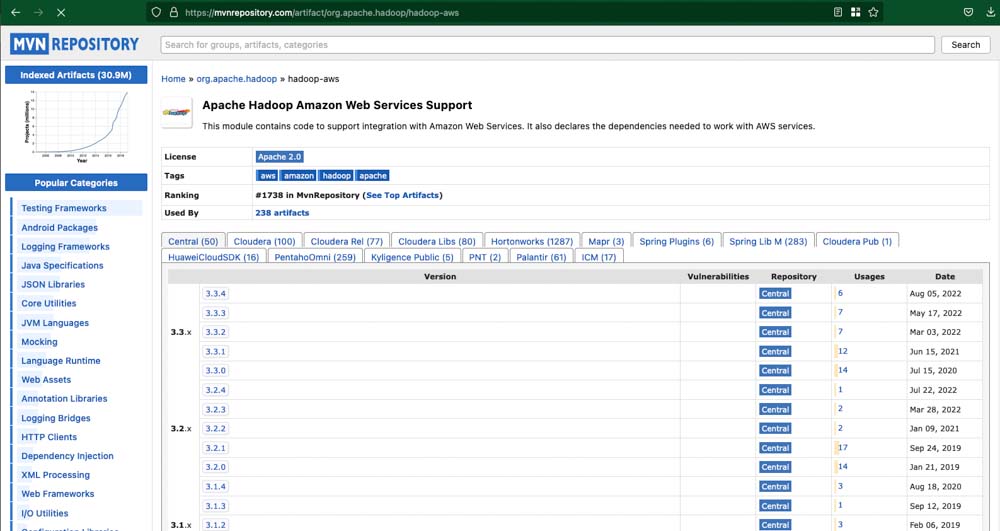
Then, download the .jar file (click in the jar in the Files line)
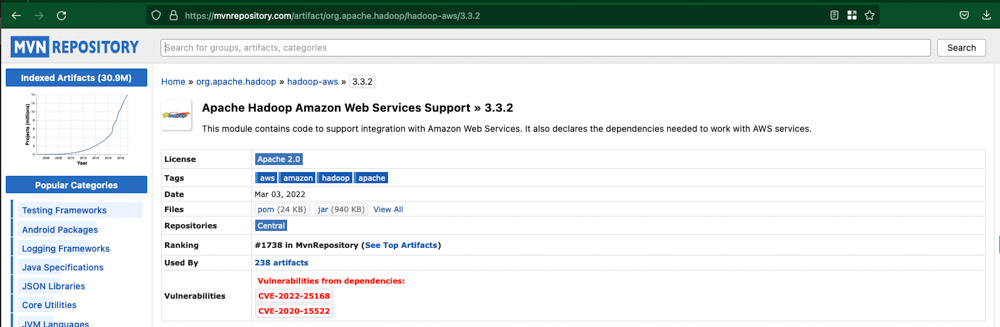
3. Move the .jar file to the pySpark environment
Now, copy from where the .jar file is saved to the pySpark environment, i.e.,
venv/lib/python<YOUR_PYTHON_VERSION>/site-packages/pyspark/jarsWhen this is done, you could open your pySpark and the package will be then installed in your environment.
Managing AWS Credentials with aws-hadoop module
You now have all the lib required to access your S3. However, even if your machine is correctly configured with an aws configure or with a role, pySpark will not be capable of accessing the AWS S3 Bucket, so you will have to make additional validation before having a functional environment.
Here is the error you could have if you directly try to access your data on S3 without any additional configuration.
[ec2-user@ip-172-31-37-236 ~]$ ./spark-3.3.1-bin-hadoop3/bin/pyspark --packages org.apache.hadoop:hadoop-aws:3.3.4
Python 3.7.16 (default, Dec 15 2022, 23:24:54)
[GCC 7.3.1 20180712 (Red Hat 7.3.1-15)] on linux
......
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.3.1
/_/
Using Python version 3.7.16 (default, Dec 15 2022 23:24:54)
Spark context Web UI available at http://ip-172-31-37-236.eu-west-1.compute.internal:4040
Spark context available as 'sc' (master = local[*], app id = local-1675154949309).
SparkSession available as 'spark'.
>>> file_to_read="s3a://my-bucket-789/bank.csv"
>>> spark.read.csv(file_to_read)
23/01/31 08:49:46 WARN MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties
23/01/31 08:49:48 WARN FileStreamSink: Assume no metadata directory. Error while looking for metadata directory in the path: s3a://my-bucket-789/bank.csv.
java.nio.file.AccessDeniedException: s3a://my-bucket-789/bank.csv: org.apache.hadoop.fs.s3a.auth.NoAuthWithAWSException: No AWS Credentials provided by TemporaryAWSCredentialsProvider SimpleAWSCredentialsProvider EnvironmentVariableCredentialsProvider IAMInstanceCredentialsProvider : com.amazonaws.SdkClientException: Unable to load AWS credentials from environment variables (AWS_ACCESS_KEY_ID (or AWS_ACCESS_KEY) and AWS_SECRET_KEY (or AWS_SECRET_ACCESS_KEY))
at org.apache.hadoop.fs.s3a.S3AUtils.translateException(S3AUtils.java:212)
......Use AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY
By Default pySpark will try to get the credentials from the OS environment variable AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY,
Consequently, if you specify these values pySpark will be able to access your AWS S3 Bucket data without any other configuration. This is how you set your variables:
export AWS_ACCESS_KEY_ID=<YOUR_ACCESS_KEY_ID>
export AWS_SECRET_ACCESS_KEY=<YOUR_SECRET_KEY>
And that’s it. Now you could try on pySpark (as example below):
[ec2-user@ip-172-31-37-236 test2]$ ./spark-3.3.1-bin-hadoop3/bin/pyspark --packages org.apache.hadoop:hadoop-aws:3.3.2
Python 3.7.16 (default, Dec 15 2022, 23:24:54)
[GCC 7.3.1 20180712 (Red Hat 7.3.1-15)] on linux
Type "help", "copyright", "credits" or "license"for more information.
.....
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.3.1
/_/
Using Python version 3.7.16 (default, Dec 15 2022 23:24:54)
Spark context Web UI available at http://ip-172-31-37-236.eu-west-1.compute.internal:4040
Spark context available as 'sc' (master = local[*], app id = local-1675161465632).
SparkSession available as 'spark'.
>>> file_to_read="s3a://my-bucket-789/bank.csv"
>>> spark.read.csv(file_to_read)
23/01/31 10:38:09 WARN MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties
DataFrame[_c0: string, _c1: string, _c2: string, _c3: string, _c4: string, _c5: string, _c6: string, _c7: string, _c8: string, _c9: string, _c10: string, _c11: string, _c12: string, _c13: string, _c14: string, _c15: string, _c16: string, _c17: string, _c18: string, _c19: string, _c20: string]
>>> exit()
Using an instance role attached to an EC2 instance
If you setup your environment in a EC2 with a role configured to access the S3 bucket, you will have nothing to do. The role will be automatically used by your pySpark.
Having a more granular control with SPARKCONF
You can have additional use case where you will need to specifically specify to Spark how to get the credentials.
This is the case for example if you want to work with multiple configuration in your aws_config file or if you want to work with AWS Cloud9.
For example, in the case you only use aws configure, the OS VARIBLES are not set.
This technique will only work for ACCESS_KEY. What about if you want to specify another credential or if you need to use a role?
In this case, the module hadoop-aws can be configured with specific properties defined in a SparkConf object and attach it to your SparkContext.
The following commands are related to the way that pySpark connects to AWS. Fore more details of these commands, please go to this reference here.
>>> from pyspark import SparkConf
>>> conf = SparkConf()
>>> conf.set('spark.hadoop.fs.s3a.access.key','1234567890123456')
>>> conf.set('spark.hadoop.fs.s3a.secret.key', 'AZERTYUIOPQSDFGHJKLMWXCVBN')
'fs.s3a.aws.credentials.provider',
>>> conf.set('spark.hadoop.fs.s3a.aws.credentials.provider', 'org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider')
>>> conf.set('spark.jars.packages', 'org.apache.hadoop:hadoop-aws:3.2.1')where 1234567890123456 is my ACCESS_KEY_ID and AZERTYUIOPQSDFGHJKLMWXCVBN my SECRET_KEY_ID
Note that conf.set('spark.jars.packages', 'org.apache.hadoop:hadoop-aws:3.2.1') is the line that install hadoop-aws into your context, if you don’t have yet.
This step will create the Spark session and install any necessary dependency.
spark = SparkSession.builder.config(conf=conf).getOrCreate()notice you can have access tot these properties later on by using the spark session class
>> spark.conf.get('spark.hadoop.fs.s3a.secret.key')
'AZERTYUIOPQSDFGHJKLMWXCVBN'Errors summary
During this article we encountered errors. Here is a summary:
| Java Errors | Proposed Solutions |
|---|---|
| No FileSystem for scheme « s3 » | replace s3 with s3a in order to identify you file (i.e. s3a://my-bucket/my-file) |
| Class org.apache.hadoop.fs.s3a.S3AFileSystem not found | install hadoop-aws lib as defined in this article |
| No AWS Credentials provided by TemporaryAWSCredentialsProvider SimpleAWSCredentialsProvider EnvironmentVariableCredentialsProvider | SparkConf needs to be setup with AWS credentials |
Doing it with a Real Example
Pre-requirements
- AWS Account with the Access key configured. More details about how to do that you could find here.
- AWS CLI configured in your (local) machine. More details of how to do that could be found here.
- Python environment configured and the pySpark properly installed. More details for how to create your Python enviroment here and how to install pySpark here.
- Java installed. More details of how to install could be find here.
The data
The data that we would like to recover from the S3 looks like that (example2.json):
[{
"RecordNumber": 2,
"Zipcode": 704,
"ZipCodeType": "STANDARD",
"City": "PASEO COSTA DEL SUR",
"State": "PR"
},
{
"RecordNumber": 10,
"Zipcode": 709,
"ZipCodeType": "STANDARD",
"City": "BDA SAN LUIS",
"State": "PR"
}]This file is already uploaded into our AWS account. If we go to our AWS account, we could see the data on the S3:
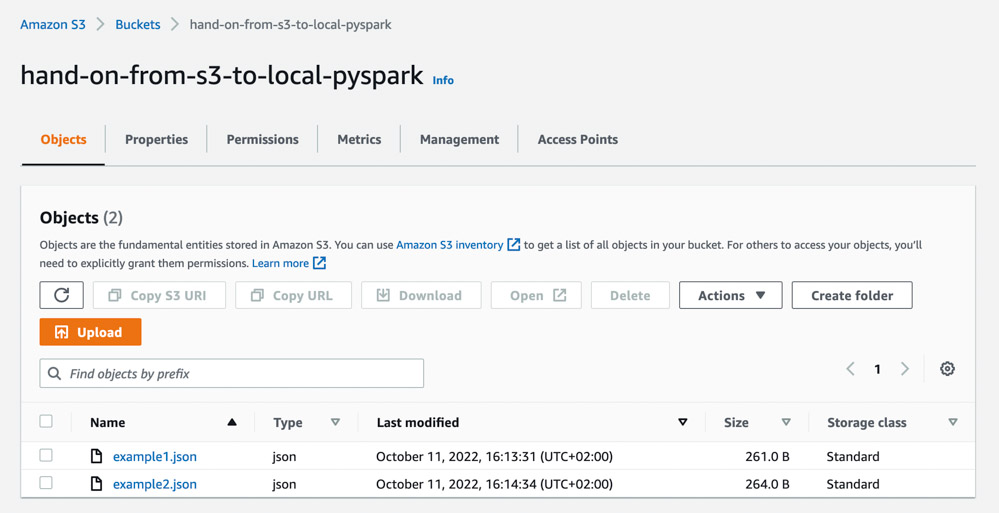
So, the S3 name is: hand-on-from-s3-to-local-pyspark and the file name is example2.json.
The local environment (PySpark)
The code
Now, it’s time to code!
1. Set AWS_ACCESS_KEY_ID and AWS_SECRET_KEY Environment Variables
Set these Environment Variables with your AWS Access Key and Secret Key, respectively into your context.
2. Launch pySpark
Launch your pySpark:
pyspark --packages org.apache.hadoop:hadoop-aws:3.3.2
This is what will prompt into your screen
:: loading settings :: url = jar:file:/XXX/XXX/XXX/XXX/XXX/venv/lib/python3.9/site-packages/pyspark/jars/ivy-2.5.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
Ivy Default Cache set to: /XXX/XXX/.ivy2/cache
The jars for the packages stored in: /XXX/XXX/.ivy2/jars
org.apache.hadoop#hadoop-aws added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-0c4387cc-52a9-454e-a719-c1ac031269cf;1.0
confs: [default]
found org.apache.hadoop#hadoop-aws;3.3.2 in central
found com.amazonaws#aws-java-sdk-bundle;1.11.901 in central
found org.wildfly.openssl#wildfly-openssl;1.0.7.Final in central
:: resolution report :: resolve 113ms :: artifacts dl 3ms
:: modules in use:
com.amazonaws#aws-java-sdk-bundle;1.11.901 from central in [default]
org.apache.hadoop#hadoop-aws;3.3.2 from central in [default]
org.wildfly.openssl#wildfly-openssl;1.0.7.Final from central in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 3 | 0 | 0 | 0 || 3 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-0c4387cc-52a9-454e-a719-c1ac031269cf
confs: [default]
0 artifacts copied, 3 already retrieved (0kB/5ms)
22/10/27 14:21:26 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
3. Read the data from S3 to local pySpark dataframe
It’s time to get our .json data! Note that our .json file is a multiline type. So the read method bellow is adapted to grab that properly. More info about different spark.read methods for .json format could be find here.
multiline_df = spark.read.option("multiline","true").json("s3a://hand-on-from-s3-to-local-pyspark/example2.json")
multiline_df.show()
output:
+-------------------+------------+-----+-----------+-------+
| City|RecordNumber|State|ZipCodeType|Zipcode|
+-------------------+------------+-----+-----------+-------+
|PASEO COSTA DEL SUR| 2| PR| STANDARD| 704|
| BDA SAN LUIS| 10| PR| STANDARD| 709|
+-------------------+------------+-----+-----------+-------+
On that way, we had access our S3 data into our local pySpark environment!
The local environment (Python)
For this example, it was created a Python 3.9 local environment called venv. The pySpark and (pip install pyspark) jupyterlab (pip install jupyterlab) were also installed. The idea is to use jupyter notebooks to run our pySpark code.
To handle the AWS Access key Credentials, a library called dotenv was installed (python -m pip install python-dotenv) and the .env file was created/configured into our local context to store the AWS Credentials. This process allow us to access the information from .env inside of our jupyter notebook without ‘hard-code’ that inside of our code (Don’t forget to double check if your .gitignore file is up-to-date to not include the .env into your commits). For more details of how to use it, please check here.
The code
Now, it’s time to code!
In your Python environment (or .py file):
1. Import the necessary libraries
from dotenv import load_dotenv
import os
from pyspark import SparkConf
from pyspark.sql import SparkSession2. Load the .env to the jupyter notebook
load_dotenv()3. Create the custom Spark configuration
This configuration will allow Spark to access the AWS S3 service.
(Note that the os.environ['aws_access_key_id'] and os.environ['aws_secret_access_key'] go the local .env file to grab the AWS Access Key ID and Secret Access Key respectively).
conf = SparkConf()
conf.set('spark.hadoop.fs.s3a.access.key', os.environ['aws_access_key_id'])
conf.set('spark.hadoop.fs.s3a.secret.key', os.environ['aws_secret_access_key'])
conf.set('spark.hadoop.fs.s3a.aws.credentials.provider', 'org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider')4. Create the Spark session with our custom configuration
spark = SparkSession.builder.config(conf=conf).getOrCreate()Note: As you create this pySpark session, the necessary packages will be stored in a temporary folder:
:: loading settings :: url = jar:file:/XXX/XXX/XXX/XXX/XXX/XXX/venv/lib/python3.9/site-packages/pyspark/jars/ivy-2.5.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
Ivy Default Cache set to: /XXX/XXX/.ivy2/cache
The jars for the packages stored in: /XXX/XXX/.ivy2/jars
org.apache.hadoop#hadoop-aws added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-fbd04e0b-1d2c-4591-a09f-a68708c38466;1.0
confs: [default]
found org.apache.hadoop#hadoop-aws;3.2.0 in central
found com.amazonaws#aws-java-sdk-bundle;1.11.375 in central
:: resolution report :: resolve 324ms :: artifacts dl 4ms
:: modules in use:
com.amazonaws#aws-java-sdk-bundle;1.11.375 from central in [default]
org.apache.hadoop#hadoop-aws;3.2.0 from central in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 2 | 0 | 0 | 0 || 2 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-fbd04e0b-1d2c-4591-a09f-a68708c38466
confs: [default]
0 artifacts copied, 2 already retrieved (0kB/6ms)5. Read the data from S3 to local pySpark dataframe
It’s time to get our .json data! Note that our .json file is a multiline type. So the read method bellow is adapted to grab that properly. More info about different spark.read methods for .json format could be find here.
multiline_df = spark.read.option("multiline","true").json("s3a://hand-on-from-s3-to-local-pyspark/example2.json")
multiline_df.show() Output:
+-------------------+------------+-----+-----------+-------+
| City|RecordNumber|State|ZipCodeType|Zipcode|
+-------------------+------------+-----+-----------+-------+
|PASEO COSTA DEL SUR| 2| PR| STANDARD| 704|
| BDA SAN LUIS| 10| PR| STANDARD| 709|
+-------------------+------------+-----+-----------+-------+
On that way, we had access our S3 data into our local pySpark environment!
Commentaires :
A lire également sur le sujet :




