
ML Design Patterns : Juggling Multiple Labels Like a Pro

In real world cases, the traditional approach of using a single output for a single input may not be sufficient. Sometimes we need multiple labels, or outputs, to be associated with each input, providing greater flexibility and functionality in complex applications. This is where the multi-label design pattern comes in.
In this article, we will explore the multi-label design pattern in depth, its benefits, and how it solves the problem of handling multiple outputs.

Multi-Label Principle
In machine learning, multi-label classification or multi-output classification is a variant of the classification problem, where multiple non-exclusive labels may be assigned to each instance.
Multi-label classification is a generalisation of multiclass classification, which is the single-label problem of categorising instances into precisely one of several (more than two) classes. In the multi-label problem, the labels are non-exclusive and there is no constraint on how many of the classes the instance can be assigned to.
Multi-label classification design pattern in action

Here are a few real-world examples of how the multi-label classification design pattern has been used in practice and the benefits it has brought to organisations:
Medical Diagnosis
In medical diagnosis, a patient’s symptoms may not be exclusive to a single disease or condition. A multi-label classification approach allows for multiple potential diagnoses to be considered simultaneously, leading to more accurate diagnoses and treatments.
In a study published in the Journal of Biomedical Informatics, a multi-label classification approach was used to diagnose five different types of thyroid diseases, therefore resulting in an accuracy rate of 98.48%.
Social Media Analysis
Social media platforms generate vast amounts of data, and classifying content accurately is crucial for various tasks such as sentiment analysis, spam detection, and content moderation. In a study published in the Journal of Intelligent Information Systems, a multi-label classification approach was used to classify Twitter posts according to 17 different categories, resulting in an accuracy rate of 87%.
Image Classification
In image classification, multi-label classification is often used to identify multiple objects or features in an image simultaneously. For example, in a study published in the journal Remote Sensing, a multi-label classification approach was used to identify different land cover features in remote sensing imagery, resulting in an accuracy rate of 90%.
As shown above in each of these examples, the multi-label classification approach led to improved accuracy and efficiency compared to traditional single-label approaches. Furthermore, it allowed for more complex and nuanced classifications, enabling organisations to extract more value from their data.
Multi-label Implementations
Here is a code snippet in Python using Scikit-learn library to demonstrate the implementation of the multi-label classification design pattern:
pythonCopy code
from sklearn.multioutput import MultiOutputClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_multilabel_classification
from sklearn.metrics import hamming_loss, precision_score, recall_score, f1_score
# Create a synthetic dataset with 100 samples and 10 features
X, y = make_multilabel_classification(n_samples=100, n_features=10, n_classes=5)
# Train a Decision Tree classifier using MultiOutputClassifier
dtc = DecisionTreeClassifier()
clf = MultiOutputClassifier(dtc).fit(X, y)
# Evaluate the model
y_pred = clf.predict(X)
hl = hamming_loss(y, y_pred)
precision = precision_score(y, y_pred, average='macro')
recall = recall_score(y, y_pred, average='macro')
f1 = f1_score(y, y_pred, average='macro')
print('Hamming Loss: ', hl)
print('Precision: ', precision)
print('Recall: ', recall)
print('F1 Score: ', f1)In this example, we create a synthetic dataset with 100 samples and 10 features, and 5 output classes. We then train a Decision Tree classifier using MultiOutputClassifier, which allows for multi-label classification. Finally, we evaluate the performance of the model using Hamming Loss, Precision, Recall, and F1 Score.
Python packages:
The Scikit-learn Python package implements some multi-labels algorithms and metrics.
The scikit-multilearn Python package specifically caters to the multi-label classification. It provides multi-label implementation of several well-known techniques including SVM, kNN and many more. The package is built on top of Scikit-learn ecosystem.
Problem transformation methods
Several problem transformation methods exist for multi-label classification, and can be roughly broken down into:
Transformation into binary classification problems
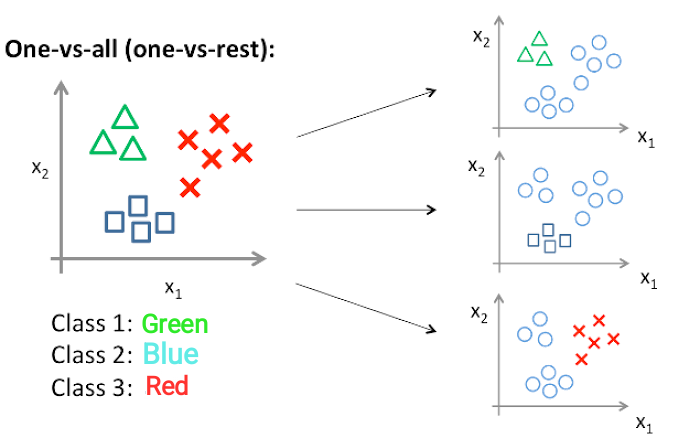
One-vs.-all (OvA) & one-vs.-rest (OvR) :
The default strategy, referred to as the binary relevance technique, entails separately training a binary classifier for each label. The integrated model then forecasts all the labels for an unseen sample for which the individual classifiers forecast a positive outcome.
Although this method of dividing the task into multiple binary tasks may resemble superficially the one-vs.-all (OvA) and one-vs.-rest (OvR) methods for multiclass classification, it is essentially different from both, because a single classifier under binary relevance deals with a single label, without any regard to other labels whatsoever.
Classifier chain:
An alternate approach for splitting up a multi-label classification problem into numerous binary classification problems is to use a classifier chain. In contrast to binary relevance, labels are predicted sequentially, and the output of all previous classifiers before it (positive or negative for a given label) are provided as features to the classifiers after it.
Transformation into multi-class classification problem
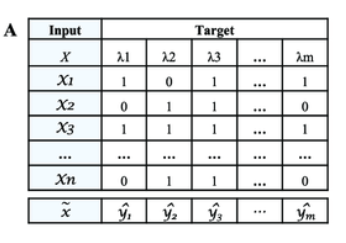
The label powerset (LP) transformation creates one binary classifier for every label combination present in the training set.
For example, if possible labels for an example were A, B, and C, the label powerset representation of this problem is a multi-class classification problem with the classes [0 0 0], [1 0 0], [0 1 0], [0 0 1], [1 1 0], [1 0 1], [0 1 1]. [1 1 1] where for example [0 0 1] denotes an example where labels A and B are present and label C is absent.
Conclusion
In conclusion, the multi-label design pattern is a powerful technique that can greatly simplify the complexity of data science tasks.
By organizing data into multiple labels, data scientists can efficiently classify and analyze large datasets, making it easier to identify patterns and insights.
Multi-label design patterns also allow for greater flexibility in modeling, as they can accommodate a variety of machine learning algorithms and techniques.
Additionally, multi-label design patterns can help improve the accuracy of predictions by ensuring that each label is assigned to the appropriate category.
Overall, mastering multi-label design patterns is an essential skill for any data scientist looking to improve the efficiency and accuracy of their work.
Further reading :
- Notebook community
- Machine learning in real life
- Machine Learning mastery
- Scikit-multilearn
- Scikit learn
- Wikipedia
Commentaires :
A lire également sur le sujet :




