
AWS Backup : comment gérer et sécuriser ses sauvegardes sur le Cloud

1989: la première attaque par ransomware documentée, connue sous le nom “attaque PC Cyborg”, fait son apparition et est distribuée via des disquettes. A l’époque, elle masquait les noms des fichiers de l’ordinateur et demandait quelques dollars pour les afficher. Trente années plus tard, ce même type d’attaques s’est développé de façon exponentielle et provoque désormais des dégâts bien plus importants, allant jusqu’à la perte totale de son système d’informations et des pertes financières énormes.
Une étude réalisée par le cabinet Sophos sur l’année 2022, touchant 31 pays et environ 5600 professionnels de l’IT a montré qu’environ 66 % ont été atteints par un ransomware, et 65% des attaques ont abouti à un chiffrement des données, ce qui les rend inutilisables si des mécanismes de sécurité n’ont pas été mis en place.
La question légitime à se poser est alors : quel serait un moyen efficace de se prémunir des conséquences d’une attaque par ransomware ? Une réponse à cette question est la gestion optimale des sauvegardes. Le service AWS Backup, sujet de cet article, adresse cette problématique.
La vie avant AWS Backup
Avant le 16 janvier 2019, date d’introduction du service AWS Backup, les sauvegardes dans l’environnement AWS se faisaient de façon décentralisée. Il fallait configurer les sauvegardes de chaque service dans son interface, ce qui est assez évident pour des petites/moyennes infrastructures mais à une échelle plus grande devient très compliqué. À titre d’exemple, pour une architecture stockant des données dans les services AWS S3, RDS et EBS, il fallait :
- Aller dans le service RDS et créer des sauvegardes automatiques ou instantanées (snapshots) pour y enregistrer les données ;
- Aller dans le service EBS et y créer des snapshots pour sauvegarder les données qu’il contient dans un bucket s3 idéalement ;
- Aller dans le service S3 et répliquer les données dans un bucket d’un autre compte ou d’une autre région.
Comme vous le constatez, à plus grande échelle (avec plusieurs services mis en jeu) il devient très complexe de bien gérer les sauvegardes, et même la restauration ne se fait pas de manière optimale, ce qui handicape clairement l’exécution complète de la politique de sauvegarde mise en place.
D’où l’intérêt d’une solution centralisée, pour pallier ces problèmes et optimiser les processus de préservation des données.
Présentation du service AWS Backup
AWS Backup rend possible la gestion et le contrôle centralisé des sauvegardes via son interface et les différentes features disponibles. Il s’agit d’un service régional, qui est donc configurable par région, peu importe le nombre de comptes AWS.
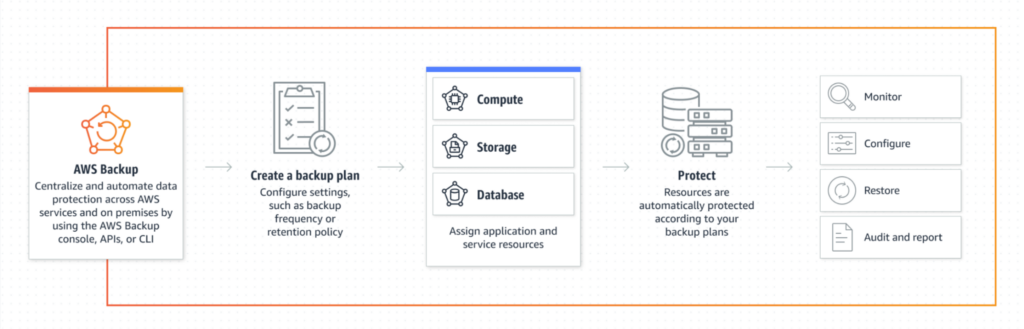
Figure 1: Le service AWS Backup
Lorsqu’on parle de sauvegarde, plusieurs éléments sont généralement à prendre en compte :
- La fréquence des sauvegardes : en corrélation avec la notion de RPO, elle est à déterminer en fonction des différents cas d’utilisation et est automatiquement gérée par le service (à condition qu’une valeur soit entrée) ;
- La durée de détention des sauvegardes : celle-ci dépend de différents aspects légaux et réglementaires, et est aussi gérée par le service. De plus, AWS Backup offre la possibilité d’avoir un cycle de vie pour les sauvegardes avant de les supprimer ;
- Le moyen d’atteindre les données à sauvegarder : pour le faire, le service utilise des tags. Ainsi, seules les ressources possédant les bons tags déterminés lors de la configuration sont “backupées” ;
- Le type de sauvegarde : il en existe plusieurs, entre autres full, incrémental et reverse incremental. AWS Backup a un comportement par défaut et non modifiable à ce sujet, à savoir que les premières sauvegardes sont toujours des full (les données sont enregistrées dans leur entièreté) et les suivantes des incrémentales (uniquement les modifications sont sauvegardées) – À noter que certains services ne prennent pas cette fonctionnalité en charge – . Ceci permet d’optimiser le temps de sauvegarde et de réduire les coûts liés au stockage des informations. Cependant, la sauvegarde incrémentale soulève un gros problème, car en cas d’erreur ou de destruction d’une des sauvegardes précédentes, la restauration complète du système devient impossible. AWS Backup permet de pallier ce défaut en conservant durant chaque enregistrement les données de référence nécessaires pour permettre une restauration complète. Ainsi, si la dernière sauvegarde complète est détruite, ou même une sauvegarde incrémentale intermédiaire, il est toujours possible d’effectuer une restauration complète ;
- Les droits à utiliser pour sauvegarder les données (et uniquement ceux-là) : un rôle managé directement par AWS est utilisé pour le service en général, à savoir AWSBackupDefaultServiceRole.
- L’accès aux différents vaults de sauvegarde : celui-ci est contrôlé à travers des politiques (backup vault policy) à mettre en place.
Features intéressantes
En plus de son fonctionnement basique déjà très intéressant, AWS Backup offre des fonctionnalités encore plus alléchantes :
Backup vault lock
Comment mettre en place une politique de WORM (Write-once,read-many) sur les sauvegardes?
La réponse est simple, en configurant un lock sur ses vaults . En choisissant un des modes compliance ou governance. Dans le premier cas, les vaults – et donc les sauvegardes – sont sécurisés et ne peuvent être altérés même par un administrateur. Dans le second, des droits spécifiques sont à utiliser pour pouvoir retirer le lock.
Backup audit Manager
Les rapports sont très importants, car ils peuvent être utilisés pour générer des dashboards permettant d’avoir une meilleure visibilité sur l’ensemble des jobs de sauvegarde, restauration ou copie effectués sur l’infrastructure.
AWS Backup audit manager permet d’une part d’effectuer cette tâche, mais aussi de vérifier la conformité des ressources aux différents contrôles définis, tels que le chiffrement des backups, la fréquence de ces derniers, et les ressources sauvegardées.
Point In Time Recovery
Avec cette fonctionnalité, il est possible de restaurer des données de son infrastructure en remontant à un moment défini jusqu’à 35 jours, avec une seconde de précision. Pour le faire, AWS Backup utilise des sauvegardes continues, qui ne sont disponibles que pour les services S3 et RDS actuellement. Ces sauvegardes fonctionnent de la manière suivante: la première est toujours une full, et les secondes sont effectuées de façon constante, en enregistrant les logs de transaction des ressources. Pour restaurer, le service remonte alors à la dernière sauvegarde complète et rejoue les différents logs jusqu’au moment choisi.
Copies cross account/cross region
Pour une meilleure sécurité, il est possible d’externaliser les sauvegardes, c’est-à-dire les copier dans un compte ou dans une région extérieure. Ceci permet alors de se prémunir contre des potentielles pertes de compte ou de région, et de s’assurer qu’on a toujours des sauvegardes à un endroit sécurisé pouvant être restaurées.
Notifications
Il est possible grâce au service SNS d’envoyer des notifications (sms, e-mail,…) suite à un job de sauvegarde, de copie ou de restauration, en cas de succès ou d’échec.
Limites du service
AWS Backup possède néanmoins certaines limites, principalement liées aux ressources avec lesquelles il s’intègre. En effet, les différentes features ne sont pas disponibles pour tout le monde, notamment :
- Le PITR (Point In Time Recovery) qui, comme dit précédemment, n’est disponible que pour les services S3 et RDS ;
- Les copies cross account et cross region : il n’est pas possible pour les services RDS, Aurora, DocumentDB et Neptune d’effectuer ces deux copies dans un même job unique. Ainsi, il faudrait copier dans un premier temps cross account, et ensuite automatiser la copie cross region via le service AWS Lambda par exemple ;
Concernant la restauration, il n’est pas possible de l’effectuer en cross account, c’est-à-dire, restaurer des sauvegardes d’un compte X dans un compte Y. Pour le faire, il faudrait d’abord copier lesdites sauvegardes dans le compte de destination, avant d’y restaurer les données.
Le lien suivant illustre bien les différentes fonctionnalités disponibles en fonction des ressources.
Tarification
Comme la plupart des services AWS, Backup est facturé en mode pay as you go. Ainsi, le client ne paie que le stockage, le transfert entre régions, la restauration et les évaluations des sauvegardes. Le tarif dépend alors des régions, des opérations effectuées et des types de ressources enregistrées.
Pour avoir plus de détails sur la tarification, consultez ce lien.
Implémentation
Le service Backup peut être mis en place de deux manières différentes : de façon centralisée ou par compte.
Centralisation
Ce mode de déploiement permet d’administrer le service à un unique emplacement dans une organisation AWS, un compte désigné comme “delegated administrator”. Tous les comptes auront alors une politique de sauvegarde uniforme, définie dans ledit delegated administrator. Il est aussi possible de centraliser les rapports, les sauvegardes, et même les clés de chiffrement utilisées dans le but d’avoir une mise en place complètement évolutive de la solution finale. Cependant, dans le cas de la centralisation des clés utilisées pour chiffrer les vaults de sauvegarde, il faudrait bien s’assurer qu’elles soient partagées entre tous les comptes concernés.
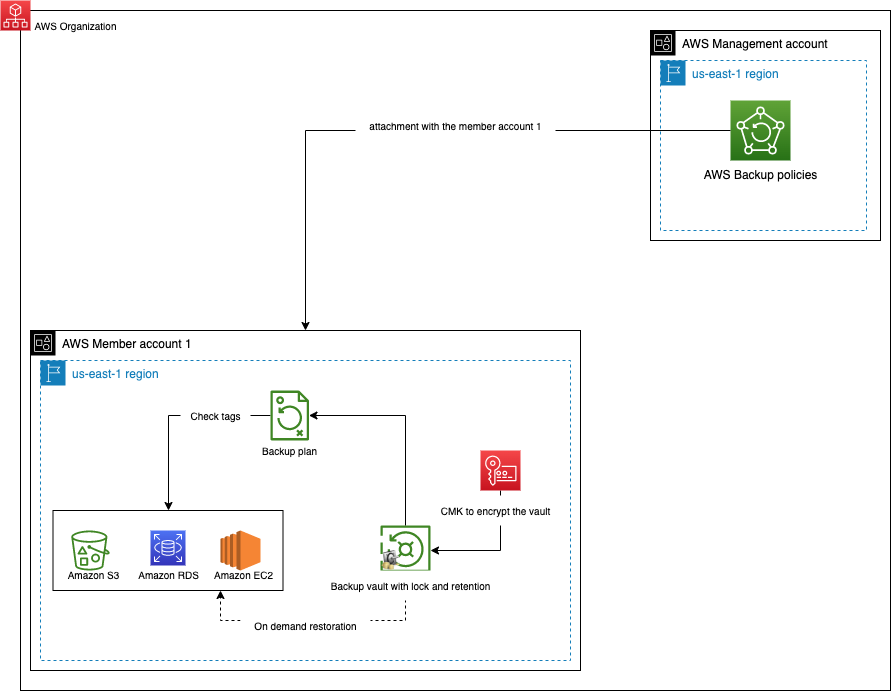
Figure 2: Architecture centralisée AWS Backup
Par compte
Contrairement au déploiement centralisé, cette méthode crée les configurations par compte. Les ressources y sont donc manipulées localement. L’intérêt pourrait ici résider dans la personnalisation des sauvegardes pour chaque compte, ou dans le cas particulier d’une organisation contenant plusieurs processus/Organizational Units avec des fonctionnements différents.
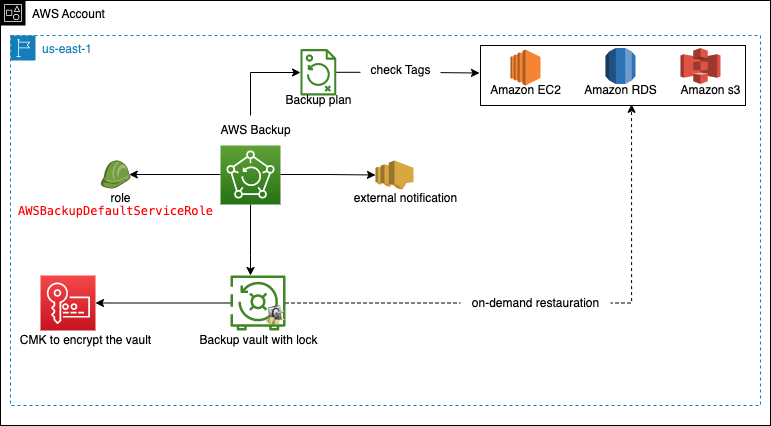
Figure 3: Architecture par compte AWS Backup
Conclusion
En définitive, il n’existe aucun moyen efficace à 100% de se protéger contre des cyberattaques, et en particulier les ransomwares. Le but est alors de solidifier son architecture au maximum dans l’objectif de complexifier le travail du hacker, qui prendra plus de temps et laissera une marge à l’entreprise cible de détecter la tentative d’intrusion.
Les sauvegardes étant les premières ressources détruites par les hackers en cas d’attaque, il est indispensable de les gérer et sécuriser de façon optimale. Dans un environnement AWS, le service Backup permet d’effectuer ces tâches de façon efficiente. Reste à le mettre en place et à l’utiliser de façon adaptée à son contexte !
Bibliographie
- P. Agnihotri, “Approches de sauvegarde, d’archivage et de restauration avec AWS,” 2014
- “Audit backups and create reports with AWS Backup Audit Manager – AWS Backup.”
- “AWS | Amazon SNS – Service d’envoi de SMS et notifications push”, Amazon Web Services, Inc.
- “Comment définir le RTO et le RPO de mon Plan de Reprise d’Activité ? » par Kévin Tabar
- “Creating a backup plan – AWS Backup.”
- “Création d’une sauvegarde – AWS Backup.”
- “Définition et exemples de sauvegarde des données informatiques”, appvizer.fr.
- J. Rodon, “Focus sur AWS Transit Gateway – partie 1 : les concepts”, Blog Devoteam Revolve, Oct. 06, 2020
- “Full backup Definitions and related FAQs | Druva.”
- “Getting started 7: Create an audit report – AWS Backup.”
- “Présentation d’AWS Backup,” Amazon Web Services, Inc.
- “Restoring to a specified time using Point-In-Time Recovery (PITR) – AWS Backup.”
- “Service Backup – Sauvegardes centralisées – AWS Backup – AWS” Amazon Web Services, Inc.
- “Tarification AWS Backup | Sauvegarde centralisée dans le cloud”, Amazon Web Services, Inc.
- “What is AWS Backup? – AWS Backup.”
- “What is WORM (write once, read many)”
- “Working with backup vaults – AWS Backup.”
Commentaires :
A lire également sur le sujet :






