Dans ta science : la qualité de la donnée avec Daniel, Data Engineer

A la croisée de plusieurs disciplines, la Data Science s’appuie sur des méthodes et des algorithmes pour tirer des informations et de la connaissances à partir de données structurées et non structurées. Encore inconnus il y a quelques années, les métiers de la Data Science et du Machine Learning évoluent très vite. Compétences, méthodes, outils… dans cette série d’entretiens, nous confrontons notre expérience à celle du marché, avec la participation de Data Scientists et spécialistes de l’IA externes à Devoteam Revolve.
Nous recevons aujourd’hui Daniel Vu-Hao Nguyen, Data Engineer, pour discuter du rôle et des missions du Data Engineer, des enjeux de la qualité de la donnée et de la question de la gouvernance de la donnée.

Comment définirais-tu le métier de Data Engineer ?
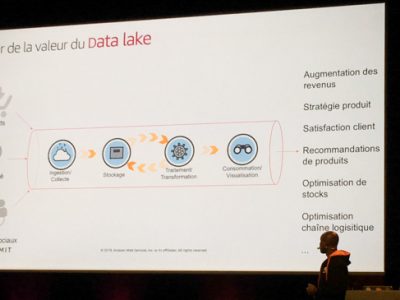
Le Data Engineering consiste à mettre en place des systèmes qui collectent la donnée à sa source, de façon à la rendre accessible à l’entreprise. Selon les entreprises, les sujets à traiter sont variés : nettoyage, transformation, manipulation, stockage, exposition de la donnée…
Pour résumer, la mission du Data Engineer est de gérer le cycle de vie de la donnée. Pour cela, on utilise des techniques de modélisation de données, on réfléchit à comment l’organiser dans différentes structures, des tables. Le plus souvent, on utilise SQL pour requêter la donnée et l’analyser, et une bonne partie de programmation, essentiellement en Python.
Pendant longtemps, le métier de Data Engineer consistait à mettre en place des flux de données. Aujourd’hui on tend plus à une construction collaborative avec les équipes métiers. Le Data Engineer les accompagne pour comprendre la donnée à la source, ce qui est attendu, et en fonction déterminer si en effet on collecte la bonne donnée, si elle génère des résultats pertinents.
Comment se répartit ton activité ?
Ce qui est bien avec le Data Engineering, c’est que les activités sont variées. La partie fondation, celle que je connais le mieux, consiste à la mise en place des systèmes, de l’infrastructure, des outils et environnements pour gérer le cycle de vie de la data. Base de données, cloud provider, orchestrations des outils, architecture… autant de choix qui sont déterminants pour la suite du projet.
Ces choix sont structurants, mais on les challenge à mesure de l’avancée dans la vie du projet, en fonction des nouveaux cas d’usage qui se présentent. Parmi les questions auxquelles on doit répondre : sur quels types de fichiers stocker les données ? Comment mettre à jour les données ? Comment les croiser avec d’autres sources ? Le traitement des fichiers doit-il se faire en batch ou en temps réel ? Plus généralement, comment stocker ces référentiels de données et les rendre interopérables ?
La mission du Data Engineering implique aussi de travailler avec les équipes de delivery pour mettre en place les flux de données qui vont répondre aux cas d’usages concrets, issus des partenaires métier (marketing, finance, service client…). Les partenaires métier ont des besoins de visibilité sur la donnée, des retours sur la performance de leurs applications… bref, tout type d’activité qui génère de la donnée au sein de l’entreprise.
Nous travaillons aussi avec les product owners, qui font le pont entre les métiers et leurs besoins, pour déterminer la valeur ajoutée d’une potentielle fonctionnalité. Beaucoup d’échanges aussi avec les experts cloud, sécurité, réseau… Le Data Engineer doit savoir quelles sont les ressources à sa disposition, et les conditions d’usage de ces ressources. Enfin, le Data Engineer travaille en étroite collaboration avec les Data Scientists, pour mettre à disposition les données avec lesquelles développer les modèles.
Enfin, il y a un autre poste important dans le cycle de vie de la donnée : le testeur qualité. La qualité de donnée est un enjeu majeur et largement sous-estimé dans les projets data. Il est nécessaire de prendre en compte la nature changeante de la data au travers du temps et des environnements (développement, production, etc.), et d’itérer au fur et à mesure qu’on découvre la donnée.
Assurer la qualité de la donnée est un effort en continu, tout au long du projet ?
Comme pour les choix d’infrastructures, c’est un travail qui se fait au début pour délimiter le cadre du projet des flux de données. Il y a beaucoup de travail à faire en amont sur l’identification de la source de données, la particularité des données étant que chaque source a son historique, avec un format particulier, et donc de nombreuses possibilités pour l’acquérir, que ça soit par API ou autrement.
Au fil du temps, la data va changer car le système source va évoluer. On va y incorporer de nouvelles données, en déprécier d’autres, donc le travail sur la qualité de la donnée dure tout au long du projet. De la même manière, on ne travaillera pas avec la même donnée selon qu’on soit sur un environnement de développement ou de production. Par exemple, dans le cas où on traite des données personnelles. Ou bien, on a un certain format de données sur l’environnement de développement, et en production les données sont issues d’un autre référentiel. On tombe alors dans le piège de devoir tester en production. En tant que Data Engineer, je m’efforce donc aussi de mettre à disposition des environnements qui soient au maximum iso production, afin de limiter ce type de surprises.
Le Data Engineer, plutôt Dev, Ops ou quelque part entre les deux ?
Il y a de nombreuses compétences sous la casquette du Data Engineer, mais en effet il y a une partie Ops et une partie Infrastructure. Mais comment identifier les sous spécialisations du Data Engineer ? Pour ma part, je suis plutôt côté infrastructure, mais je suis amené à discuter avec d’autres Data Engineers qui sont plutôt côté Ops et mise en place des flux. Cela dépend beaucoup de l’entreprise et de la taille de l’équipe Data. Cela pose d’ailleurs la question de la taille idéale d’une équipe data.
Sur quels sujets travailles-tu ?
Mes expériences les plus récentes ont porté sur la construction de plateforme de données : la mise en place d’un socle commun, des outils et des méthodes pour exploiter les flux et répondre aux cas d’usage actuels et futurs. La particularité de ce domaine, c’est que plus on dispose de données, plus il y a de demandes pour les corréler, et donc il faut passer à l’échelle la plateforme de données.
Je travaille sur ce type de cas d’usage depuis 5 ans, et le plus souvent j’utilise des outils AWS pour répondre au besoin, et faire évoluer la plateforme brique par brique en fonction des usages. C’est un travail incrémental avec un socle de base, qu’on fait évoluer et sur lequel on ajoute des fonctionnalités.
Quels sont les points de vigilance ?
On parle assez peu de ce que j’appelle l’expérience développeur. Un projet de plateforme passe par une phase de développement et une phase de déploiement, et notre travail doit aussi inclure la mise en place d’outils de CI/CD pour optimiser ces déploiements, assurer des tests automatisés, dans le but de réduire les temps de déploiement, et le temps de validation d’un livrable.
Quel est le ratio entre les cas d’usage en développement et ceux en production ?
C’est compliqué de donner un chiffre précis, mais je pense que le ratio est assez faible. Pour ma part, je suis assez exigeant sur ce qu’on considère comme un cas d’usage en production. On peut faire des livrables de flux de données, les mettre dans un environnement de production, mais tant que le cas d’usage n’est pas exploitable de façon autonome, je ne considère pas qu’il est vraiment en production. S’il reste des interventions humaines, comme un fichier à déposer, une configuration à changer ou un notebook à mettre à jour, alors le cas d’usage n’est pas réellement exploitable au quotidien. Pour être considéré comme étant en production, il faut qu’il y ait une logique d’automatisation de bout en bout. Je suis exigeant sur ce point car le Data Engineer a tout intérêt à ne pas avoir à intervenir sur un système en production pour le faire vivre.
Qu’en est-il du ML Ops ? Est-ce déjà une réalité ?
Pour quelques chanceux, oui. C’est le maillon manquant entre le POC de Data Science et le projet en production. Le ML Ops se situe tout en haut de la pyramide des besoins de la data : en bas, on a les sources de données et la qualité des données, puis des utilisateurs de données, puis la Data Science, et tout en haut, l’industrialisation. Le ML Ops est intéressant car il va permettre de suivre la performance des modèles au fil du temps, faciliter leur déploiement et l’automatisation, gérer le versioning, identifier la dérive… d’où la notion d’entraînement continu.
Quels services Cloud utilises-tu ?
Selon moi le principal bénéfice du cloud, dans mon cas le Cloud AWS, ce sont les services managés. Pour le Data Engineer, le suivi de l’outil en production est déterminant sur la charge de travail au quotidien. Dans cette optique, pouvoir mettre en place du monitoring pour savoir si le système est disponible, avoir des upgrades automatiques, des alertes, et le tout avec des outils interopérables car issus du même écosystème, c’est un vrai avantage.
En complément, on utilise aussi des outils externes comme Terraform pour l’IaC, Github/gitlab pour décorréler le lieu d’exécution du code. Également Jira et Confluence pour le ticketing et la documentation, ou Notion, alternative que j’apprécie beaucoup en ce moment.
J’ai aussi pas mal travaillé avec Snowflake, qui est une alternative intéressante à Amazon Redshift. Ça peut être pertinent dans le cas d’entreprises qui ont trouvé leur cas d’usage, et des volumes de données assez élevés pour passer à l’échelle. Dans ce cas, il sera intéressant d’utiliser Snowflake pour décorréler la puissance de calcul de la capacité de stockage, mais aussi d’avoir une gouvernance des accès, du partage de données, qui est plus modulaire avec Snowflake. C’est un point sur lequel Snowflake se démarque.
Quels sont les enjeux de la gouvernance des données ?
C’est un concept dont on parle de plus en plus dans le cadre des entreprise data driven, c’est-à-dire les entreprises qui basent leurs décisions sur des faits, des données. Pour en arriver là, il y a une transformation à mener, mais elle ne s’applique pas uniquement à l’IT. C’est un changement qui s’opère au niveau de la culture d’entreprise : plutôt que de demander aux équipes Data de mettre en place des flux de données, l’ensemble des services de l’entreprise doit réfléchir ensemble à la construction du flux.
La question qui se pose en matière de gouvernance, est de savoir comment maintenir le référentiel de données au sein de l’entreprise. Ce n’est pas uniquement le travail de l’IT ou des équipes Data, le référentiel est la propriété des équipes métiers ou des services support, qui sont les plus à même de connaître le contenu. Le challenge est de réussir l’adoption des outils et processus par tous les acteurs, pour maintenir le catalogue de données à jour.
C’est le premier frein. Ensuite, se pose la question de l’intégration des outils et du référentiel de données avec le reste de l’écosystème technique : la synchronisation avec les données des systèmes de CRM, des outils financiers, etc. Synchroniser ces systèmes, et les maintenir à jour est un effort constant. Certes, les outils sont de plus en plus connectables, avec des API, mais ce n’est pas le cas de tous les outils du marché. Sur ce type de système, on peut donc très rapidement arriver à ajouter de la dette technique à mesure que le nombre d’outils à synchroniser augmente. Par exemple, en mettant en place des actions manuelles pour intégrer un outil supplémentaire.
D’autant plus que qu’il est assez inconfortable d’être en charge de la gouvernance des données : il faut gérer à la fois les demandes d’évolution, les mises à jour des schémas de données, la conformité de l’architecture et les régulations, tout en propageant les bonnes pratiques et les standards. D’ailleurs, le rôle dédié à la gouvernance des données n’est pas vraiment défini, on parle parfois de Data Steward, mais les responsabilités de ce poste ne sont pas encore clairement fixées.
Pour terminer, une recommandation ?
Oui, la newsletter hebdomadaire de blef.fr qui agrège les actualités, tendances et articles sur le Data Engineering. C’est Made in France et j’ai eu quelques occasions de le voir présenter en live.
Commentaires :
A lire également sur le sujet :