
Dataiku Data Science Studio : focus sur les fonctionnalités et l’intégration dans un environnement AWS

Cet article a été co-rédigé par Olivier Randavel et David Dupin.
Dans le cadre de l’accompagnement d’un client dans sa migration vers le cloud d’AWS, nous avons mis en place un datalake complexe répondant aux défis imposés par le caractère sensible des données de santé. Après les phases de préparation, d’anonymisation et d’exposition, les Data Scientists utilisent Dataiku pour tirer profit de la donnée.
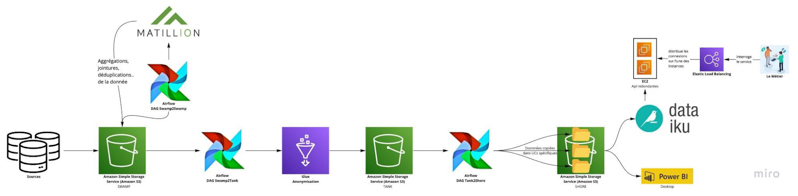
Notre pipeline déployé sur AWS se découpe en trois buckets S3 :
- Swamp : les données brutes sont acheminées depuis des sources diverses vers ce premier bucket
- Tank : ce bucket héberge les données anonymisées
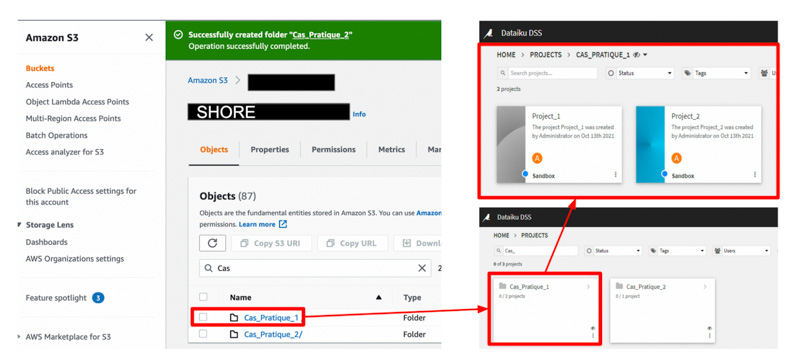
- Shore : les données sont réparties dans des dossiers pour chaque étude de cas. Chaque dossier possède un accès défini par un rôle.
Ce pipeline est orchestré par Airflow à l’aide de DAG (Direct Acyclic Graph). Chaque dag est composé de tasks, une task est un job python ou une requête bash.
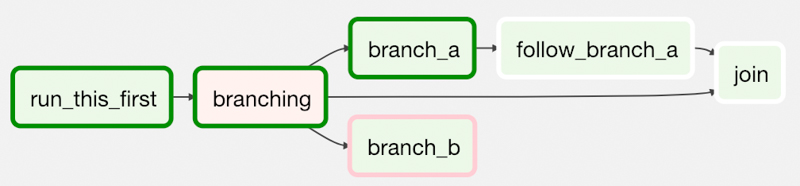
Crédit : https://airflow.apache.org/docs/apache-airflow/2.3.2/concepts/dags.html
Airflow nous permet de gérer trois types d’orchestration :
- Swamp2Swamp : les données sont préparées avant anonymisation (agrégations, jointures, déduplications..) à l’aide de Matillion (logiciel SaaS)
- Swamp2Tank : les données sont anonymisées à l’aide d’un job scala générique exécuté par Glue
- Tank2Shore : les données sont copiées dans des dossiers. Chaque dossier répond à une étude de cas spécifique et est exploité par les data scientists.
Dataiku possède un accès aux données contenues dans le shore. Ces données sont croisées pour répondre à des besoins métiers, au travers de dashboards et REST APIs.
A l’intersection de la data analyse, de la data science et de la data ingénierie, Dataiku permet à ces trois métiers de s’épanouir dans l’élaboration d’un cas pratique. Cet outil polyvalent permet d’analyser, d’explorer et de préparer la donnée. Ensuite, les data scientists conçoivent ou exploitent des modèles de machine learning prédictifs, qu’ils peuvent industrialiser pour être déployés sur des REST APIs.
Cet article aura pour objectif de présenter les multiples fonctionnalités présentes dans l’outil. Puis de développer l’aspect logiciel en détaillant l’infrastructure. Enfin, le but sera de préciser les services AWS utiles pour tirer le meilleur du potentiel de Dataiku.
Nous aborderons les points suivants :
- Dataiku DSS
- Qu’est-ce que Dataiku
- Noeud Dataiku
- Authentification et sécurité
- Fonctionnalités Dataiku
- Projet
- Formats de fichiers supportés
- Langages de développement supportés
- Notebook
- Recipy
- Scénario
- Calcul distribué/déporté
- Machine Learning & AI
Dataiku DSS
Qu’est ce que Dataiku ?
Dataiku est un logiciel SaaS permettant aux Data Scientists de transformer des données, de les visualiser et d’appliquer des modèles de machine learning, et ce via un navigateur Internet.
Son approche clic-bouton permet d’élaborer facilement des flow de traitements de la donnée au sein de projets (voir le détail d’un flow dans le paragraphe suivant). Chez notre client, nous avons choisi de créer un dossier par étude de cas, correspondant à un dossier du bucket shore. Les shore sont étanches les uns des autres afin d’assurer la sécurité des données. Dans notre configuration, nous utilisons la version 9 de Dataiku.
Authentification et sécurité
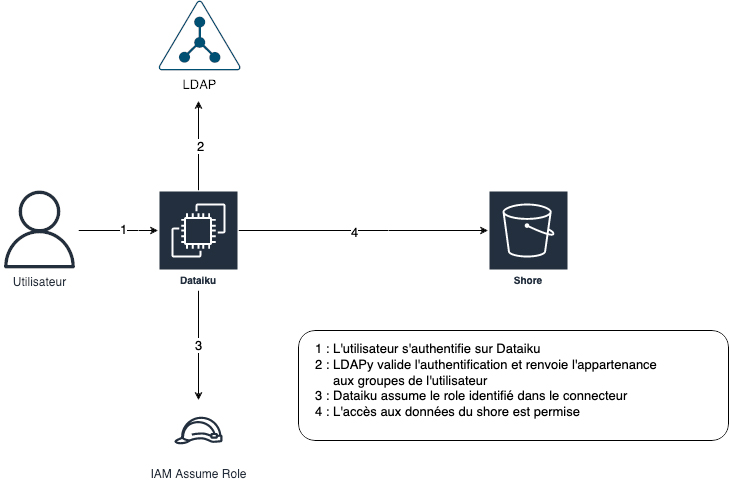
Dataiku supporte le protocole LDAP, ce qui permet une authentification centralisée (comme par exemple la base utilisateurs Microsoft). Un connecteur s3 est créé sur la plateforme Dataiku pour toutes les études de cas. Chaque connecteur est restreint par un rôle qu’assume Dataiku pour accéder aux données du dossier du shore. Chaque utilisateur est habilité, via l’Active Directory, à utiliser un connecteur.
NB : Dataiku supporte également l’authentification SSO (SAML/SPNEGO) mais elle n’a pas été mise en place dans le contexte client.
Noeud Dataiku
Lors de l’installation de Dataiku, on distingue 4 types de noeuds Dataiku, ayant chacun un rôle spécifique :
- Noeud Design : C’est sur ce nœud que l’on va explorer et développer nos flux de traitements de la donnée. C’est l’installation minimale de Dataiku.
- Noeud Automation : Ce nœud a pour vocation d’héberger les releases des projets, qui auront été développés sur le nœud Design. On pourrait assimiler ce nœud à la notion d’environnement de production pour les projets Dataiku. Ce nœud n’est pas obligatoire mais recommandé.
- Noeud API : Ce nœud n’est pas pourvu d’une IHM et a pour seule vocation de répondre aux requêtes d’API. Ces REST APIs auront été au préalable développées sur le nœud Design et déployées par le service Deployer.
- Noeud Deployer : Ce nœud facilite le déploiement des bundles (release des projets Design vers le nœud Automation) ou les REST APIs vers les nœuds APIs. Ce noeud n’est pas obligatoire car ce rôle peut être assuré par un service présent sur Design/Automation
Fonctionnalités Dataiku
Projet
Dataiku demande à un utilisateur de créer un projet. Ce projet permet de séquencer, dans un flow, des traitements sur la donnée. Un flow est un orchestrateur, permettant d’effectuer plusieurs transformations successives sur sa donnée.
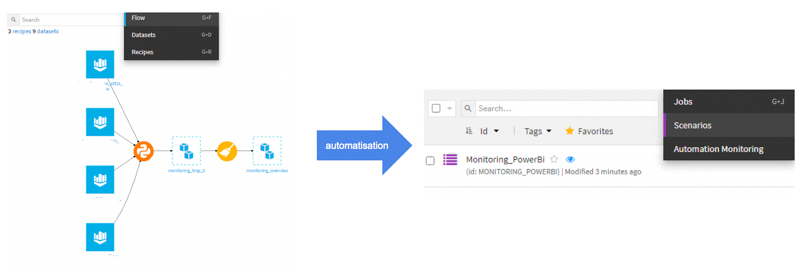
Il est composé de différents objets tels que :
- Dataset : une table de données
- Recipy : algorithme de traitement de la donnée
- Wiki
Formats de fichiers supportés
De multiples formats et fournisseurs cloud sont gérés par Dataiku.
D’une part, les fichiers CSV, Excel, Avro, Parquet sont supportés nativement. D’autres formats peuvent être exploités à l’aide de plugins disponibles sur la marketplace de Dataiku (pdf, jpeg, mp3..). D’autre part, l’accès aux données se fait à l’aide de connecteurs tels que AWS, Azure, GCP et Snowflake.
Langages de développement supportés
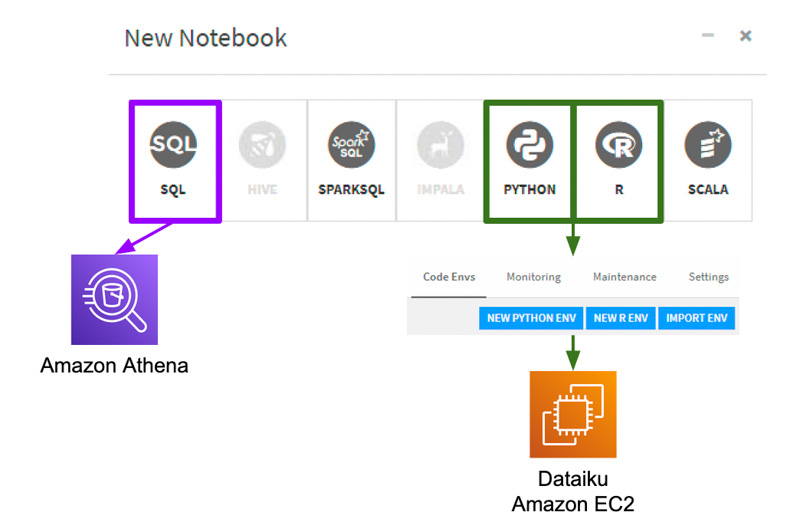
Dataiku supporte les langages courants de la Data Science tels que Python, SQL, R ainsi que leur équivalent spark pour le calcul distribué. Cela permet aux Data Scientists de trouver un langage auquel ils sont habitués, ou d’exploiter le langage le plus opportun pour un cas particulier. Un utilisateur a l’opportunité de créer son environnement virtuel (code env) et d’y installer ses librairies et versions souhaitées.
Notebook
Le data scientist peut expérimenter des transformations à l’aide de notebook. Jupyter notebook est intégré dans Dataiku.
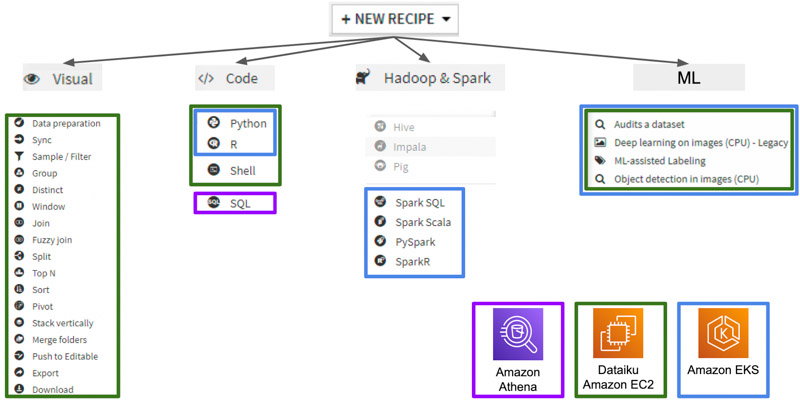
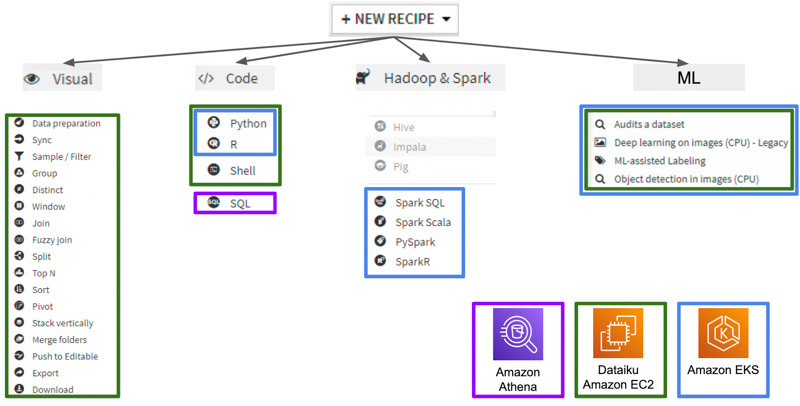
Recipy
Une recipy est une transformation que l’on va appliquer à la donnée. L’utilisateur peut choisir parmi plusieurs “recipies” :
- Visual : traitement prédéfini par Dataiku (que l’on peut toutefois paramétrer)
- Code : permet d’appliquer un algorithme de traitement de la donnée. Plusieurs langages sont possibles ainsi que le calcul distribué à l’aide de Spark
- ML : appliquer du machine learning sur un Dataset
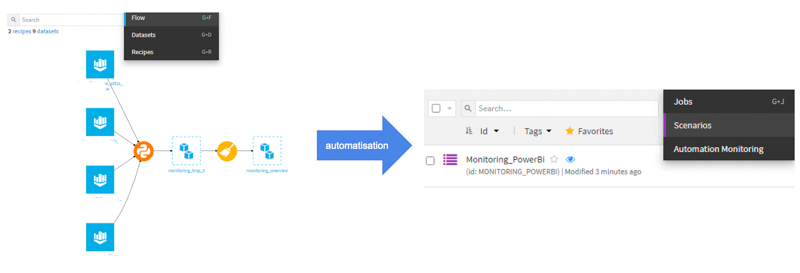
Scénario
Une fois notre flow développé, celui-ci peut alors être automatisé et exécuté de façon planifiée. Dataiku prévoit un alerting au niveau de ces scénarios et permet d’effectuer des actions, suivant l’état d’une étape précédente. Il est donc possible d’envoyer une alerte par mail si une étape du scénario échoue.
Calcul distribué/déporté
Qui dit big data dit forcément gros volume de données à traiter. Cela peut s’avérer particulièrement impactant si l’on souhaite exécuter un job sur notre nœud Design par exemple. Il faudrait prévoir une taille d’instance musclée pour pouvoir absorber la charge d’un tel calcul (surtout si on considère l’ensemble des projets).
Une des solutions est de déporter le calcul sur Kubernetes (EKS). Le calcul est alors distribué à l’aide de Spark ou réalisé sur un container CPU/GPU. Les instances (node au sens EKS) qui exécutent ces calculs sont provisionnées à la demande, et terminées une fois le calcul exécuté.
Machine Learning & IA
L’intelligence artificielle est au cœur de Dataiku, en effet, cet outil accompagne les data scientists dans l’élaboration de leurs modèles. Le data scientist dispose d’une interface de machine learning, offrant des dashboards sur les métriques d’entraînement de ces modèles. Il lui est alors possible de comparer la performance de plusieurs modèles et de choisir le meilleur. Une fois le modèle entraîné, il est possible de le publier sur une REST API.
Conclusion
Dataiku permet donc de visualiser, transformer, traiter les données avec facilité. Une grande partie de la complexité est masquée au travers de son API, mais également de ses multiples connecteurs (Database, stockage cloud, etc).
Ce projet fait partie d’un pipeline complexe développé entièrement par Devoteam Revolve. Cette plateforme met en relation différentes technologies open source (Airflow), services AWS (Glue, EKS, Redshift, etc.) et partenaires cloud (Matillion, Talend …).
Si un pan en particulier de Dataiku vous intéresse, n’hésitez pas à nous contacter, que ce soit par exemple comment a été mis en place l’isolation des droits s3 ou encore l’élaboration du calcul distribué/déporté sur EKS ou toute autre technologie qui pourrait faire l’objet d’un article.
Ainsi Dataiku conviendra à toute entreprise désireuse d’accélérer la mise en production de ses projets data, ou encore n’ayant pas les ressources internes pour maîtriser les technologies complexes, telles que Spark ou le machine learning. Dataiku peut être perçu comme une alternative à Sagemaker. Aujourd’hui, chez notre client, Dataiku gère plus de 50 études de cas permettant de servir les applications développées par les métiers, à travers des REST APIs ou des dashboards.
Commentaires :
A lire également sur le sujet :




