
Step Functions array flattening

In this blog post, we will discuss a more or less undocumented way of flattening arrays in a State Machine without using a dedicated Lambda function. That is, transforming an array of arrays (of arrays, of..) into a plain simple flat array. It can be especially useful when handling Parallels or Maps state results.
A simple array as Map result…
If you are going heavy on Step Functions, you probably use Parallels or Maps somewhere. And you know that the output of those states is a JSON array containing the individual outputs of each sub-state machine.
For example, let us consider this simple State Machine :
{
"Comment": "Demonstration of the flattening of an array",
"StartAt": "CREATE_MAP_INPUT",
"States": {
"CREATE_MAP_INPUT": {
"Type": "Pass",
"Result": {
"some_key": "some_value",
"key_to_iterate": [
1,
2,
3
]
},
"Next": "MAP"
},
"MAP": {
"Type": "Map",
"ItemsPath": "$.key_to_iterate",
"Iterator": {
"StartAt": "DO_WORK",
"States": {
"DO_WORK": {
"Type": "Pass",
"Parameters": {
"res.$": "States.Format('Iteration #{}', $)"
},
"OutputPath": "$.res",
"End": true
}
}
},
"End": true
}
}
}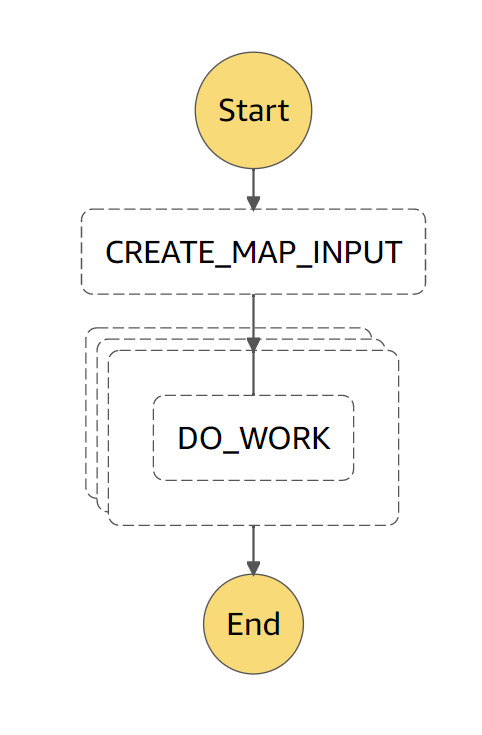
Figure 1: Our simple example State Machine graph.
We use a Map state, but the problem we will tackle and the solution are quite similar in a Parallel state.
Here we use a simple Pass state (DO_WORK) to yield a single value inside our Map. Of course in the real world it would probably be multiple Task states leading to the output of this value, but for the purpose of this demonstration a simple Pass is enough. We can look at the output of the Map and see that it is an array the same size of the input array used by the Map for its iteration :
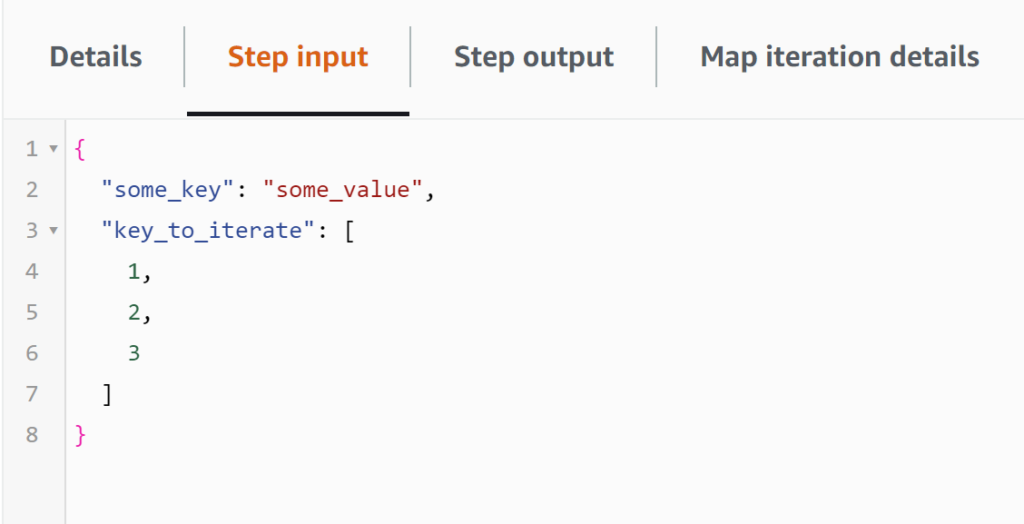
Screenshot 1: The Input of the Map state, with the “key_to_iterate”, an array of 3 elements.
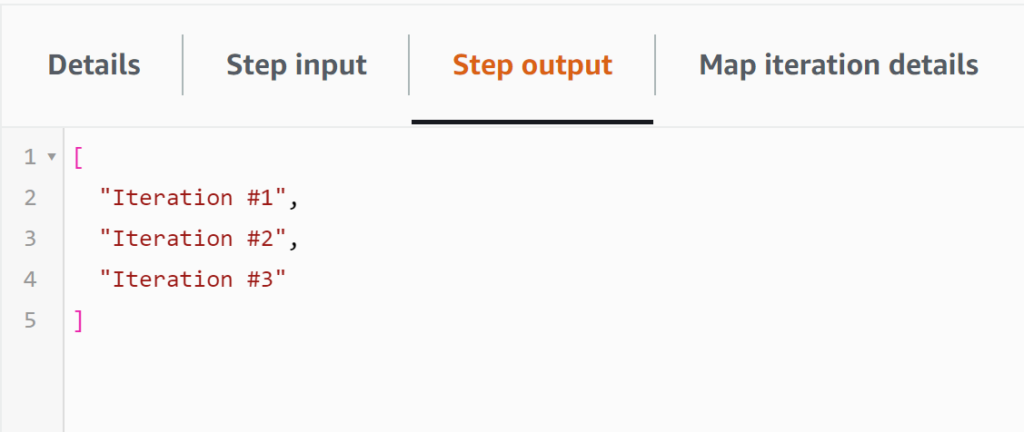
Screenshot 2: The Output of the Map state, an array of the 3 results of each independent iteration (the value returned by DO_WORK).
An ugly array of array…
All is well, but let us say that instead of yielding simple values like strings or numbers, each of your sub-state machine yield an array of values. And you would like your Parallel or Map to output a unique, flatten array of all those values.
We recently came across such a use-case where we had a Map state that iterates over a list of Instance IDs and creates snapshots of the EBS volumes of each instance. What we want that Map to output is simply the list of the snapshot IDs. But, as each instance can have multiple volumes, the sub-state machine doing the job returns an array of snapshot IDs. Then the Map state returns an array of arrays of snapshot IDs. How can we flatten that into a simple array of snapshot IDs?
To better illustrate the use-case, we can modify our previous example by making the “DO_WORK” Pass state yield an array of values instead of a single value:
"DO_WORK": {
"Type": "Pass",
"Parameters": {
"res.$": "States.Array(States.Format('Iteration #{}1', $), States.Format('Iteration #{}2', $))"
},
"OutputPath": "$.res",
"End": true
}
Then the Map result becomes:

Screenshot 3: The Output of the Map state, an array of the 3 arrays produced by each of the 3 independent iterations.
As expected, we got ourselves an array of arrays. Argh, ugly! Give me a flatten array with all the values!
The solution
When we searched the Internet for a solution with my colleague, we did not find anything (we may be bad at searching) neither in the AWS documentation nor in other resources. All the solutions point toward writing a simple Lambda function called by a Task state to do the job. But you don’t need to do that!
Basic
It turns out that you can use the JMESPath syntax [*] for the win 🙂 And it is quite trivial, though not explicitly documented in any example of the AWS documentation.
In the definition of your Map or Parallel state, you only need to do that little trick:
"MAP": {
"Type": "Map",
"ItemsPath": "$.key_to_iterate",
"Iterator": {
"StartAt": "DO_WORK",
"States": {...}
},
"ResultSelector": {
"flatten.$": "$[*][*]"
},
"OutputPath": "$.flatten",
"End": true
}
We add a ResultSelector and an OutputPath and… voilà:

Screenshot 4: The Output of the Map state, a flatten array of the values produced by the independent iterations.
No need to have an additional State, no need to have another Lambda function! And it will also work to flatten arrays on 3 or 4 or more levels: just keep adding [*] in the ResultSelector! The only thing that is important is that the depth (number of levels) must be fixed and the same everywhere.
Keeping the input
Of course, if you write exactly what I propose, you will lose the Input of your Map/Parallel and it may not be what you want. But you can keep the idea and apply it another way with a ResultSelector and a ResultPath:
"MAP": {
"Type": "Map",
"ItemsPath": "$.key_to_iterate",
"Iterator": {
"StartAt": "DO_WORK",
"States": {...}
},
"ResultSelector": {
"flatten.$": "$[*][*]"
},
"ResultPath": "$.map_result",
"End": true
}
In that case you will keep all your original Input and will be able to access the result in $.map_result.flatten
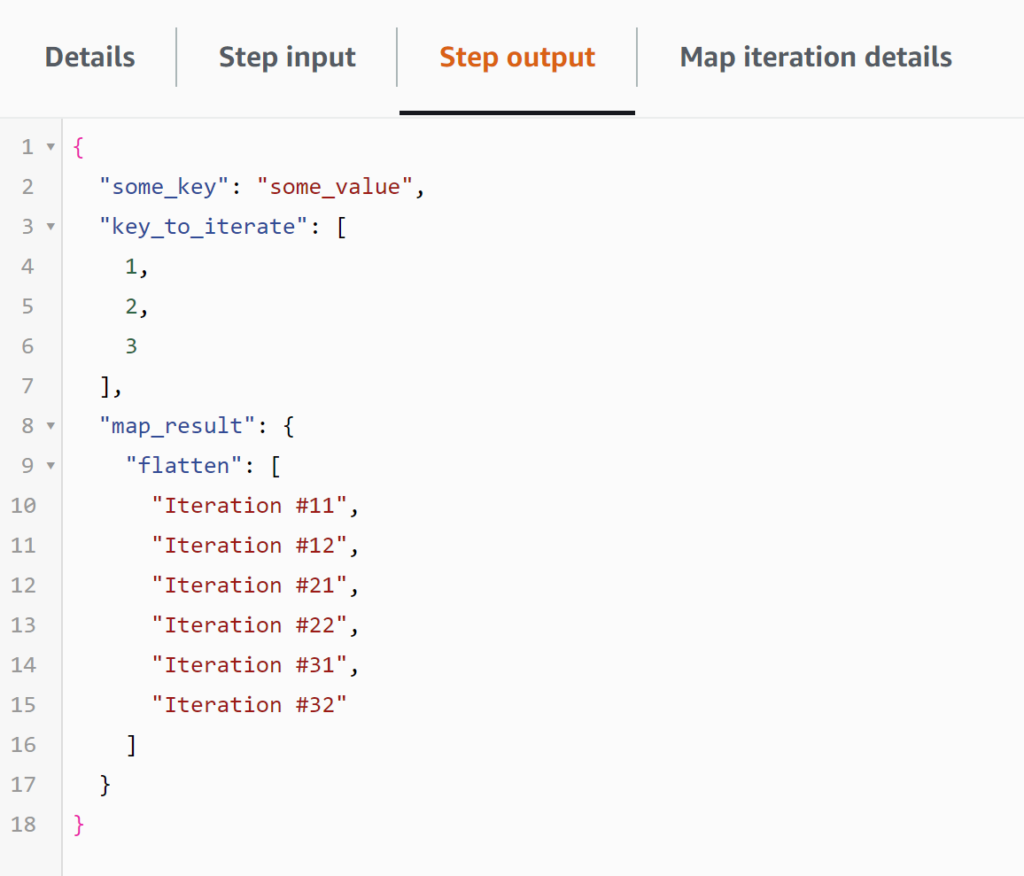
Screenshot 5: The Output of the Map state, containing all the original Input in addition to a flatten array of the values produced by the independent iterations.
If you are really bothered by the “useless” flatten node, you will (unfortunately) need to add an additional Pass state to correct that:
{
"Comment": "Demonstration of the flattening of an array",
"StartAt": "CREATE_MAP_INPUT",
"States": {
"CREATE_MAP_INPUT": {
"Type": "Pass",
"Result": {
"some_key": "some_value",
"key_to_iterate": [
1,
2,
3
]
},
"Next": "MAP"
},
"MAP": {
"Type": "Map",
"ItemsPath": "$.key_to_iterate",
"Iterator": {
"StartAt": "DO_WORK",
"States": {
"DO_WORK": {
"Type": "Pass",
"Parameters": {
"res.$": "States.Array(States.Format('Iteration #{}1', $), States.Format('Iteration #{}2', $))"
},
"OutputPath": "$.res",
"End": true
}
}
},
"ResultSelector": {
"flatten.$": "$[*][*]"
},
"ResultPath": "$.map_result",
"Next": "REMOVE_USELESS_FLATTEN"
},
"REMOVE_USELESS_FLATTEN": {
"Type": "Pass",
"InputPath": "$.map_result.flatten",
"ResultPath": "$.map_result",
"End": true
}
}
}
Note the addition of a new Pass state at the end, after the “MAP”.
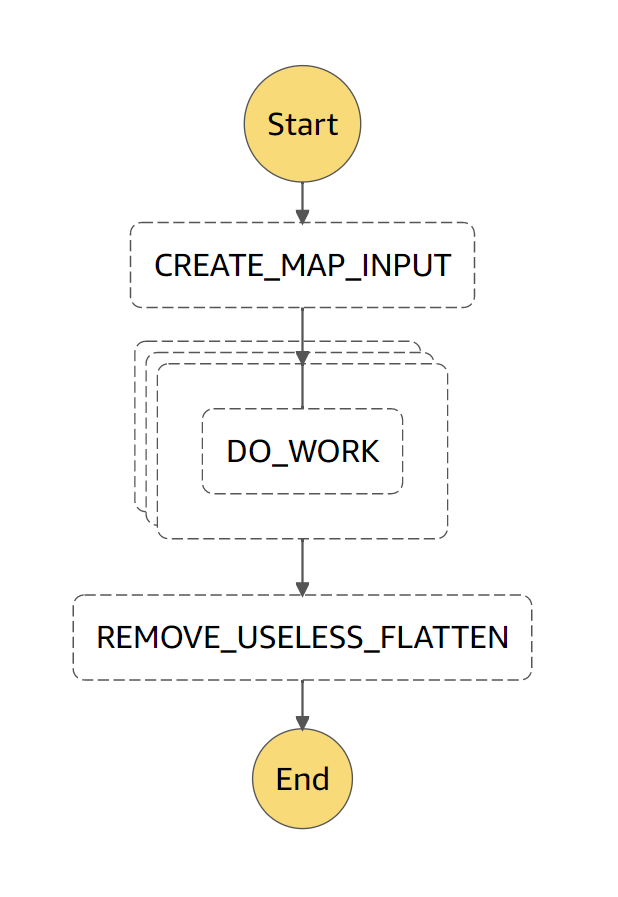
Figure 2: State Machine graph after adding the REMOVE_USELESS_FLATTEN state.
And the REMOVE_USELESS_FLATTEN state will do that:
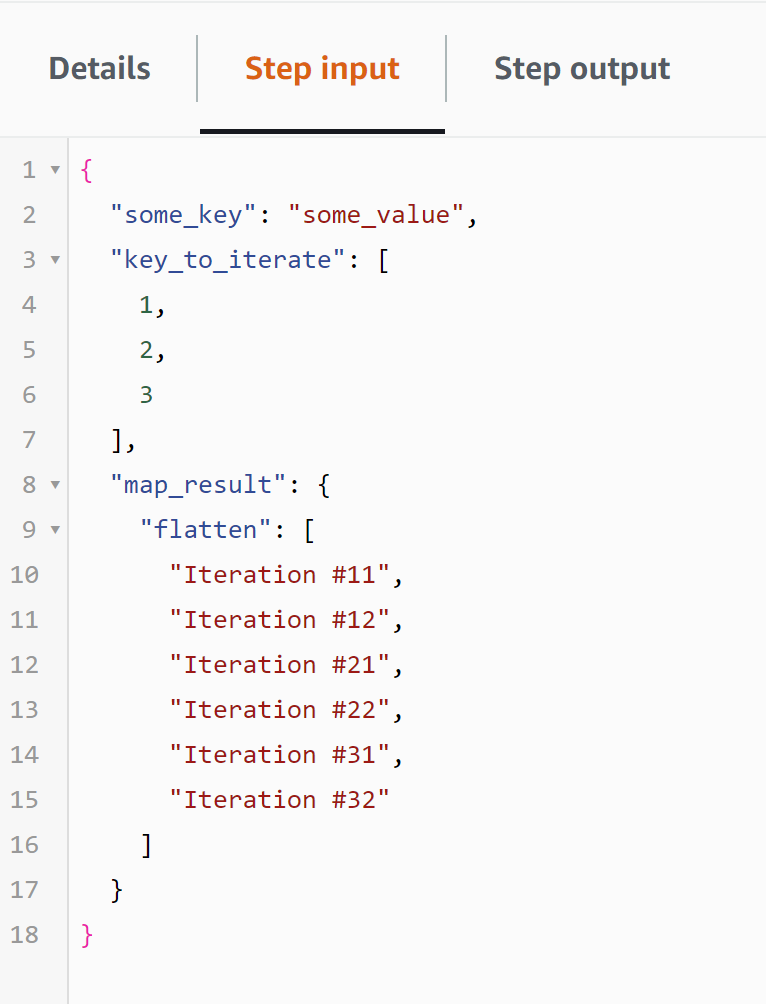
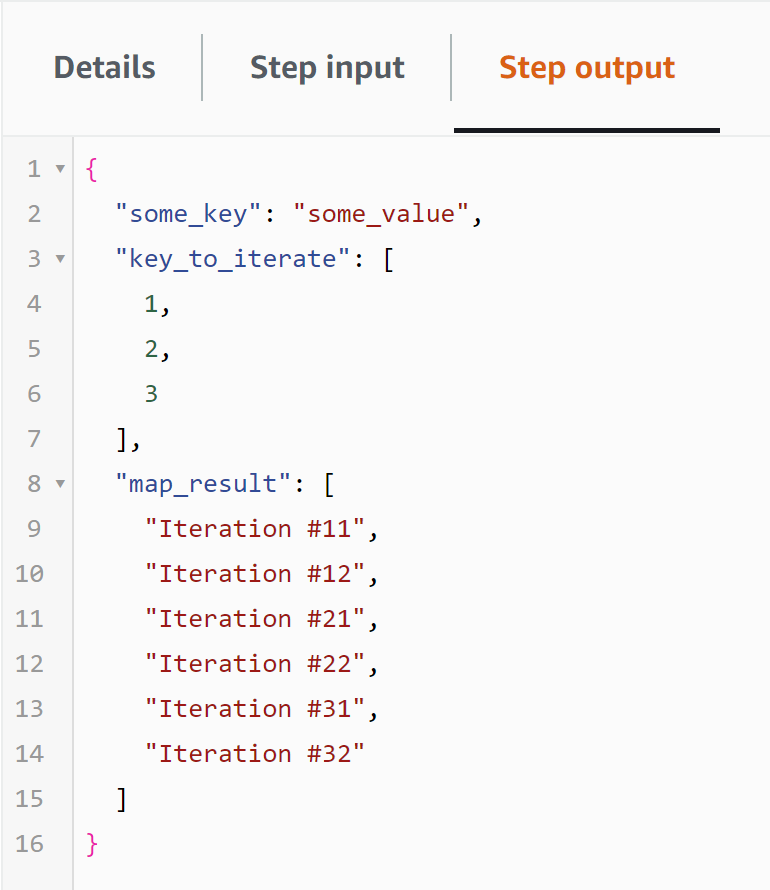
Screenshots 6&7: The Input and Output of the REMOVE_USELESS_FLATTEN Pass state.
It costs an additional State-transition, but it is really only necessary if you are as irritable as I can be in front of an useless node in a JSON ^^
Here it is. I hope you learned something from this. It is not much, but as I was not able to find this solution on the web, I thought it could be useful for someone to lay it out in a post 🙂
Commentaires :
A lire également sur le sujet :





