
Retour d’expérience : déployer et gérer une infrastructure Kubernetes on premise

Dans le cadre d’une mission client, nous avons accompagné l’équipe chargée de développer des services d’enrichissement de données. Dans ce contexte où les applications sont déployées et administrées par une équipe d’exploitation sur des VMs (machines virtuelles), le client avait deux besoins principaux. Faire adopter la méthodologie DevOps à cette équipe afin de lui faire gagner en agilité, et migrer sur une architecture résiliente, automatisée avec capacité de passer à l’échelle. Après une première phase durant laquelle nous avons étudié l’environnement et précisé les besoins du client, nous avons fait le choix de partir sur une infrastructure basée sur Kubernetes on-premise.
Dans cet article, nous allons présenter les motivations qui nous ont poussés à faire ce choix et présenter les problématiques intéressantes rencontrées lors de sa mise en place sur un environnement de type on-premise.
Motivations de la solution Kubernetes on-premise
Avant de partir sur le choix Kubernetes, nous avons d’abord étudié cette solution. A quels besoins permet-elle de répondre et quelles contraintes pose-t-elle dans un environnement on-premise?
Kubernetes c’est tout d’abord une plateforme open source initiée par Google, qui est un orchestrateur d’applications conteneurisées et qui est par la suite devenu une plateforme cloud-native. La communauté est très active, et la fréquence de sortie d’une version est de l’ordre de quelques mois. Elle met à disposition un ensemble d’outils permettant l’automatisation et la mise à l’échelle. Un cluster Kubernetes peut contenir des hôtes qui peuvent à la fois être sur des environnements on-premise, cloud publics, privés ou encore hybrides.
L’ensemble des mécanismes d’automatisation mis à disposition par Kubernetes, s’ils sont bien utilisés en respectant la démarche DevOps permettent de tirer profit des bénéfices de ce paradigme.
Les principaux avantages qui répondent aux besoins du client sont les suivants:
- Accélérer la transition entre le développement et la mise en production de nouvelles fonctionnalités sur les services d’enrichissement (réduire le fameux time to market), grâce notamment à la capacité d’intégrer le déploiement via des pipelines CI/CD
- Gagner en réactivité avec la capacité de passer à l’échelle les services en utilisant le mécanisme de HPA (horizontal pod autoscaler) , faciliter les phases de troubleshooting grâce à la mise en place d’une stack d’observabilité
- Garantir la résilience des services grâce à divers mécanismes tels que self-healing, service discovery, liveness et readiness pour ne citer qu’eux.
Depuis quelques années maintenant, Kubernetes est devenu une référence sur le marché des solutions d’orchestration conteneurisées. Pour mieux s’en rendre compte, il suffit de jeter un œil du côté des principaux fournisseurs Cloud. Elastic Kubernetes Service (EKS) chez AWS, Azure Kubernetes Service (AKS) chez Microsoft Azure et Google Kubernetes Engine (GKE) chez Google, tous ont fini par développer une solution adaptée à leur écosystème. Les compétences sur le marché suivent également cette tendance. Le client a aussi le besoin de s’assurer qu’il pourra facilement trouver des profils compétents sur cette solution pour assurer son maintien futur.
Déployer et gérer un cluster Kubernetes sur un environnement on-premise est différent de l’usage d’un service managé par un fournisseur Cloud. Si l’on prend par exemple la solution d’AWS, Elastic Kubernetes Service (EKS), le déploiement est simple et rapide et le client n’a pas la main sur les nœuds et les composants connexes constituant le control plane. Ils sont sous la responsabilité du fournisseur Cloud AWS.
Sur du on-premise, au contraire, les administrateurs gèrent l’installation de zéro du cluster et ont la main libre sur le control plane. Ils sont donc responsables de la bonne gestion des composants. À titre de rappel, quelques composants essentiels aux bon fonctionnement d’un cluster Kubernetes :
- Etcd : Base clé/valeur qui maintient des données d’état sur le cluster, elle est généralement déployée en mode cluster sur les nœuds du control plane.
- Kube-scheduler : Composant dont le rôle est d’assigner des pods à des nœuds du data plane en se basant sur des données contenues dans l’Etcd.
- Kube-controller-manager : Daemon qui observe en continu l’état du cluster, c’est un composant au cœur du fameux mécanisme de boucle de régulation.
- Kube API-server : Serveur exposant une API REST, valide et applique les changements sur des ressources du cluster.
Nous avons également étudié la question de l’espace disque présent sur chaque nœud. Lorsque l’on déploie un pod, on télécharge et cache l’image conteneur associée. Il faut donc veiller à ce que le cache ne prenne pas trop de place sur le stockage auquel cas surviendrait un risque de dysfonctionnement du cluster. Pour certaines applications, il peut y avoir un besoin d’assurer la persistance des données, on peut prendre le simple exemple d’une base de données MySQL déployée en tant que pod. Il fallait prévoir également la gestion du stockage distribué de ce type d’application dans l’architecture cible.
Sur la question de l’installation, plusieurs solutions existent pour automatiser cette phase. L’automatisation de cette phase présente deux avantages majeurs :
- Réduire drastiquement la durée de réinstallation d’un cluster dans le cas d’une panne majeure sur son infrastructure.
- Pouvoir déployer très rapidement un nouveau cluster directement prêt à l’usage si le besoin se présente (et il s’est présenté !).
Automatisation de l’installation, le choix Kubespray
L’installation d’un cluster Kubernetes est considérée comme une tâche le plus souvent fastidieuse par les opérateurs et DevOps, c’est pourquoi et comme évoqué précédemment nous avons cherché à automatiser au maximum cette tâche. Il existe actuellement plusieurs solutions pour déployer des clusters Kubernetes sur un environnement on-premise, ci-dessous les solutions que nous avons étudié en particulier:
- Kubeadm : Installateur officiel de Kubernetes
- RKE (Rancher Kubernetes Engine): Installateur développé par Rancher, écrit en Golang
- Kubespray : Un outil combinant à la fois Kubeadm et Ansible
Après étude, nous avons choisi de partir sur Kubespray car cet outil répondait à plusieurs de nos besoins.
C’est d’abord un outil open-source qui est maintenu par une communauté très active. Il nous permet de gérer facilement les montées de versions Kubernetes. L’inconvénient est que l’on dépend désormais du cycle de développement de l’outil pour passer sur des versions plus récentes.
Il est compatible avec une distribution Linux mise à disposition par le client. L’outil offre également une bonne modularité sur le type d’architecture Kubernetes que l’on souhaite déployer.
Enfin, il utilise une combinaison de Kubeadm et de l’outil de gestion de configuration Ansible, sur lequel l’équipe Ops du client possède des compétences.
En amont de l’installation d’un cluster Kubernetes dédié pour les environnements de test et de certification des services d’enrichissement du client, nous avons effectué un travail de préparation sur les VMs qui allaient le constituer.
Tout d’abord, il a fallu déterminer le nombre de VMs et leurs caractéristiques respectives à dédier au cluster. Nous sommes partis sur huit machines.
Pour le control plane qui, comme évoqué précédemment, contient des composants essentiels au bon fonctionnement du cluster, nous avons choisi de dédier trois VMs pour garantir un minimum de haute disponibilité.
Pour le data plane, deux VMs avec un plus de ressources mémoire ont été provisionné à notre demande car les services à héberger en sont particulièrement consommateurs.
La cinquième machine provisionnée joue le rôle d’hôte bastion. Elle permet d’exécuter des playbooks Ansible pour préconfigurer les futurs nœuds du cluster et ensuite d’exécuter Kubespray. Les deux dernières sont dédiées à la répartition de charge des serveurs API Kubernetes présents sur les trois nœuds composant le control plane, avec l’installation préalable d’HAProxy.
Pour les premières cinq machines constituant le cluster, nous avons automatisé leur pré-configuration avec Ansible, avec notamment :
- Copie de la clé publique d’un utilisateur créé à l’occasion autorisant la connexion SSH entre hôte bastion et nœuds et donc la bonne exécution des playbooks Ansible depuis par la suite.
- Montage d’un volume additionnel de 100 Gb pour stocker le chemin /var/lib/docker destiné à sauvegarder les images des conteneurs.
- Installation de divers paquets nécessaires à la bonne exécution de Kubespray
- Ouvertures de ports réseaux
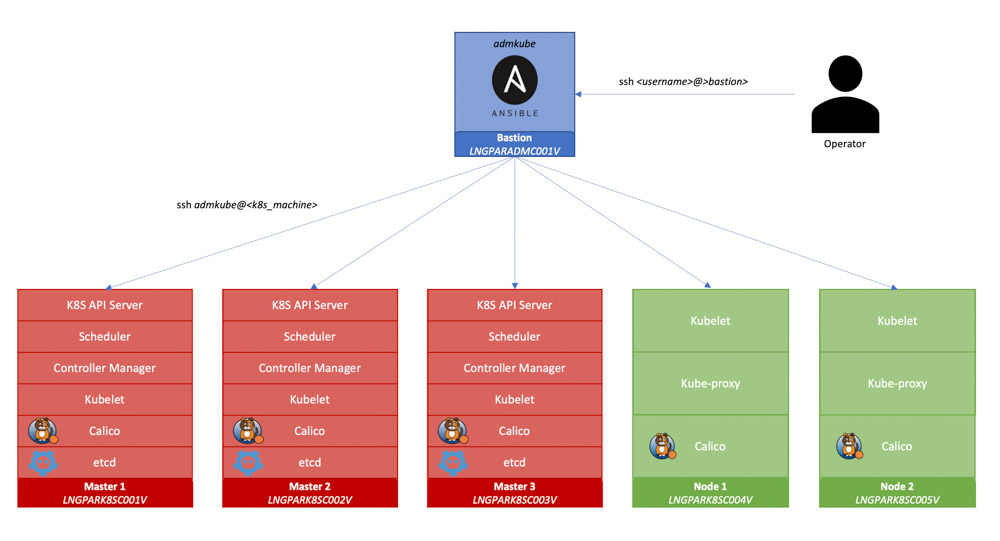
Schéma de configuration et de déploiement via Kubespray
Une fois cette étape achevée, nous avons procédé à des ajustements sur la manière dont Kubespray allait déployer le cluster sur les VMs. Un choix majeur pour l’architecture finale a été de dédier la répartition de charge sur des serveurs HAProxy installés sur des VMs commandées à l’occasion.
Haute disponibilité du cluster avec HAProxy et KeepAlived
HAProxy est un logiciel outil open source reconnu pour la répartition de charge. Nous l’utilisons ici pour répartir la charge à la fois sur l’API Kubernetes (hébergée sur les nœuds du control plane) et sur les services déployés sur le cluster (hébergé sur les nœuds du data plane).
Afin d’éviter que la VM sur laquelle est installé HAProxy ne soit un point de défaillance unique (SPOF, single point of failure), nous avons fait le choix après discussion avec le client d’avoir une seconde instance d’HAProxy. Le but recherché est d’avoir une instance de secours (backup) et donc de bénéficier d’une haute disponibilité sur le service de répartition de charge. Ce choix amène avec lui deux contraintes : comment s’assurer que la configuration des deux instances HAProxy reste cohérente sur les deux instances? Et comment basculer de manière transparente sur l’instance de secours si la première venait à tomber?
Synchronisation de configuration
Pour la première problématique, nous avons cherché un moyen de synchroniser la configuration présente sur chacune des machines. Elle est définie par défaut, à l’installation d’HAProxy, dans un fichier haproxy.cfg. La solution que nous avons trouvée a été de créer un point de montage via NFS sur l’hôte bastion. Cela permet au final d’avoir une seule et même configuration partagée entre les deux serveurs.
Pour la seconde, nous sommes partis sur un mécanisme de FailOver (basculement). Nous avons choisi pour cela le service KeepAlived. Cette solution nous permet d’associer un IP virtuelle, c’est-à-dire une adresse associée à aucun serveur, à plusieurs IPs cette fois associées. Dans notre cas, la configuration est assez simple avec seulement deux serveurs.
On définit principalement trois éléments dans la configuration :
- Une adresse IP virtuelle associée au deux instances HAProxy
- L’adresse IP de l’instance principale
- Et l’adresse IP de l’instance de secours
Pour résumer, pour joindre notre cluster (que cela soit pour solliciter l’API Kubernetes ou les services exposés du client) nous ne passerons plus que par cette adresse virtuelle. Si l’instance principale HAProxy est défaillante, l’ip virtuelle sera montée sur l’instance de secours jusqu’à que l’instance principale soit de nouveau rétablie. La reprise sera alors totalement transparente.
D’ailleurs, il n’est pas usuel de passer par une adresse IP pour solliciter un service. On préfère généralement passer par un nom d’hôte. Pour cela nous avons créé un enregistrement sur le serveur DNS du client spécifique au cluster afin de résoudre tous les noms d’hôtes associés aux services hébergés. Finalement, les noms d’hôtes de ces services seront résolus par l’adresse virtuelle associée à nos instances HAProxy.
Une dernière fonctionnalité que nous avons mis en place pour sécuriser les échanges avec les services du cluster depuis l’extérieur à été l’activation de TLS (Transport Layer Security). Pour cela il a fallu dans un premier temps générer un certificat validé par la PKI (Public Key Infrastructure) interne du client. Nous avons configuré un certificat de type wildcard de sorte qu’il valide l’enregistrement DNS associé au cluster. Dans un second temps, il ne restait plus qu’à configurer les HAProxy pour qu’ils autorisent les connexions HTTPS en associant ce certificat.
Pour finir voici un schéma global de cette infrastructure :
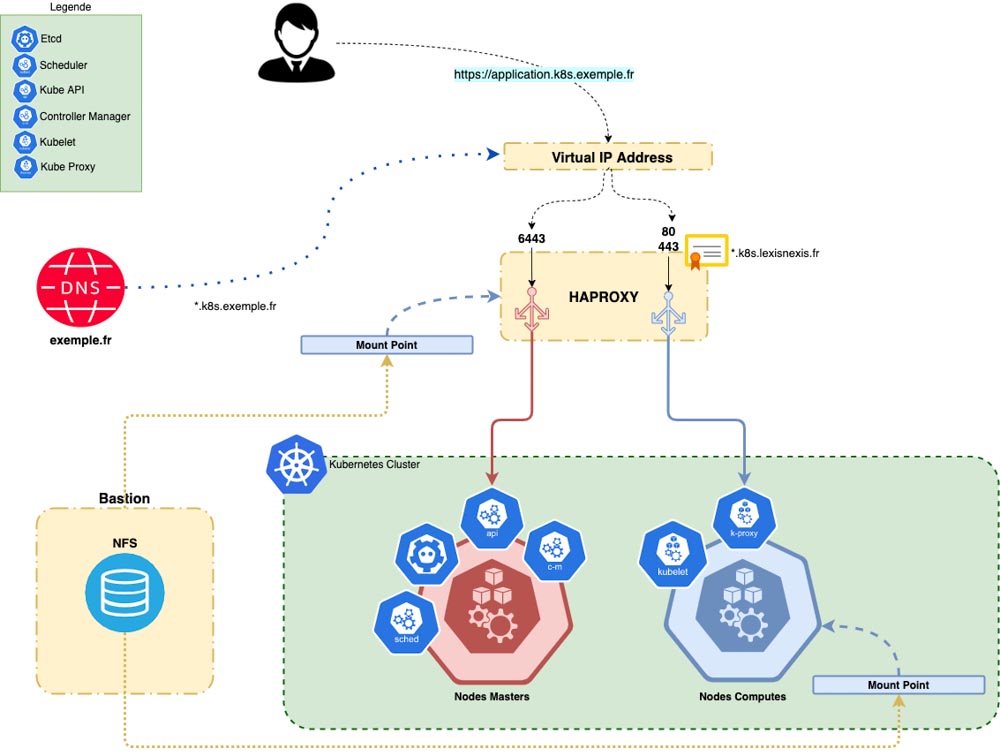
Schéma de l’infrastructure pour la haute disponibilité de l’accès au cluster Kubernetes
Gestion du stockage persistant des pods, avec nfs-provisionner
Lorsque l’on déploie des applications sur un cluster Kubernetes, par défaut les données sont stockées en local sur le nœud qui héberge le pod. La durée de vie des données est éphémère, c’est-à-dire que dès lors que le pod disparaît ses données aussi. Cependant, on peut avoir des cas où l’on souhaite que les données persistent.
Pour répondre à ce besoin, Kubernetes met à disposition un ensemble de ressources pour maintenir la persistance de ces données: Persistent Volume (PV), Persistent Volume Claim (PVC) et Storage Class. Pour faire simple, une storage class permet de décrire comment on va provisionner un persistent volume. Un persistent volume claim est une ressource que l’on lie à un namespace (cluster virtuel) et définit comment sera consommé un persistent volume.
Un persistent volume claim est une ressource qui, lié à un namespace, permet de consommer un persistent volume selon plusieurs conditions. Si on souhaite qu’un pod ait accès à un persistent volume, alors on lui associe le persistent volume claim correspondant dans son namespace.
Ce besoin de persistance s’est matérialisé lorsque le client a exprimé son besoin d’avoir un stockage de configuration clé/valeur distribué au sein du cluster Kubernetes. En effet, les services à migrer sur le cluster sont codés nativement pour récupérer leurs configurations depuis un serveur Consul. Déployer un cluster Consul sur Kubernetes a donc comme pré-requis de configurer la persistance de son stockage clé/valeur.
Pour garder une cohérence avec ce que l’on avait précédemment mis en place, nous souhaitions que nos PVs soient hébergés sur l’hôte bastion, et donc connectés en NFS au cluster. Nous avons donc cherché à créer une storage class permettant de provisionner/déprovisionner des PVs dynamiquement via NFS. Nous avons finalement trouvé une solution nommée nfs-provisionner. Une fois configuré, dès qu’un pod présente un besoin de persistance, on lui spécifie une storage class nfs-provisionner . Ainsi à son initialisation, un PV et un PVC sont générés.
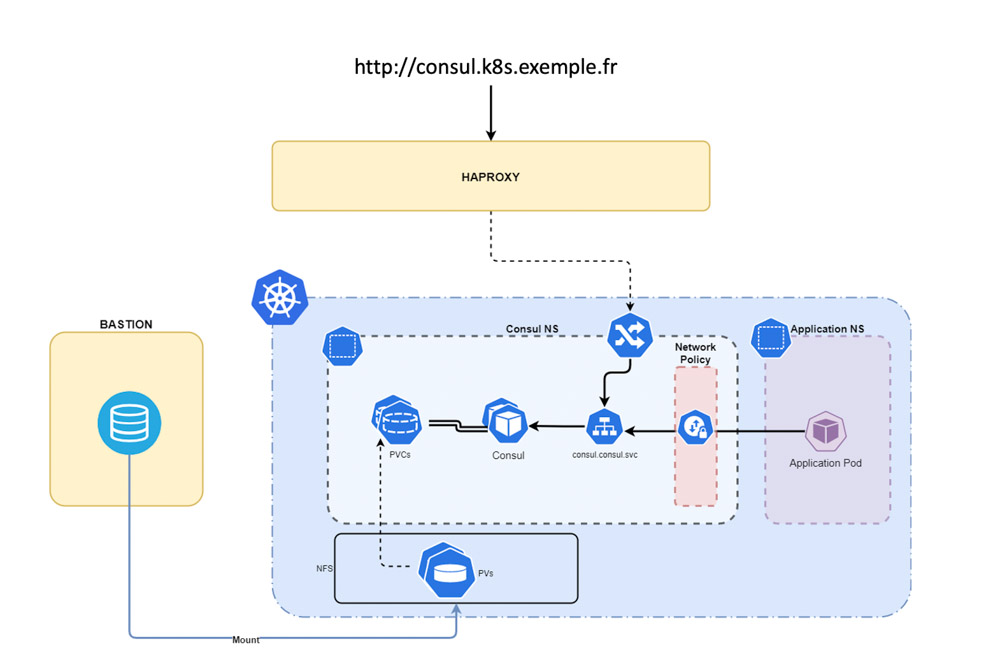
Schéma sur la persistance des données pour le service Consul
Conclusion
Pour conclure, on constate que l’installation d’un cluster Kubernetes sur un environnement on-premise cache une multitude de problématiques qu’il est important de soulever au maximum en amont. Pour cela une phase d’étude de l’écosystème du client s’impose pour en identifier les contraintes principales. Elles peuvent être diverses, ici nous en avons identifiées liées au réseau, au stockage, aux systèmes etc.
Dans un prochain article, nous parlerons de l’ensemble des outils que nous avons ensuite mis en place pour compléter le cluster Kubernetes :
- gestion des secrets applicatifs (Vault),
- observabilité (Prometheus, Istio, Kiali, Grafana, Loki),
- CI/CD (Jenkins),
- gestion des configurations applicatives (Consul)
Commentaires :
A lire également sur le sujet :




