
Cette astuce Step Functions que vous ne connaissez peut-être pas

L’autre jour, j’étais en formation et je délivrais la “Developing on AWS”. Peu de personnes le réalisent, mais on apprend jamais autant qu’en essayant d’apprendre aux autres. Cela devient rapidement évident pour n’importe qui se plaçant dans la position de transmettre des connaissances. Chaque fois qu’on dit quelque chose, qu’on transmet un fait ou une explication, il y a toujours cette petite voix au fond de notre tête : “Est-ce que je suis en train de dire une bêtise ? ?” Et cette voix nous pousse à aller vérifier et tester plein de trucs, à remettre en cause ce qu’on pensait acquis et, à la fin, il y a toujours des détails supplémentaires ou des subtilités qui nous manquaient. Et puis parfois, c’est un des étudiants qui pointe directement quelque chose qu’on n’avait pas vu jusqu’à maintenant.
Mise à jour du 15/11/2021 : Précision d’un effet de bord potentiel sur CloudWatch. Merci Antoine !
Et donc j’étais en train de leur parler de AWS Step Functions. Vous savez, c’est le service qui permet d’orchestrer des fonctions Lambda au sein de workflow plus ou moins complexes (en gros). On peut définir des exécutions séquentielles, parallèles ou conditionnées, des mécanismes d’attentes, de retry ou de gestion des erreurs, et même implémenter des mécanismes d’approbation. Le but de l’article n’est pas de faire une introduction générale au service Step Functions, donc si vous ne connaissez pas vous pouvez rapidement avoir une petite idée des possibilités avec cette page de la doc AWS. Revenons à mon histoire.
J’étais en train d’expliquer un cas d’utilisation possible de Step Functions : celui de gérer des opérations trop longues pour une lambda (ou simplement éviter de faire des “sleep” dans la Lambda). Un exemple concret de ce cas d’utilisation peut-être trouvé dans mon 3eme article sur l’automatisation de Transit Gateway : j’utilise une Step Function (techniquement on appelle ça une State Machine, mais tout le monde fait l’abus de langage et dit Step Function) pour gérer le déploiement de deux templates CloudFormation dans deux comptes différents. Ces templates doivent être déployés séquentiellement et il est donc nécessaire d’attendre que le premier se termine avant de lancer le second.
Un extrait de schéma tiré de l’article pour mieux visualiser :
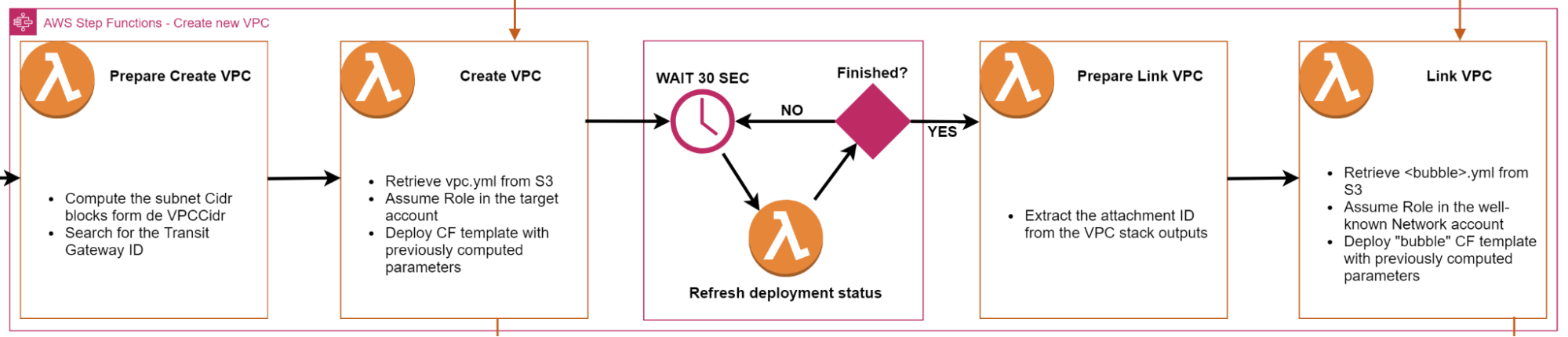
La “boucle d’attente” est en plein centre : attendre 30 secondes, rafraîchir le statut du déploiement, si c’est fini on avance, sinon on repart pour un tour.
Au delà de cet exemple d’application concrète, le principe peut-être conceptualisé comme suit :
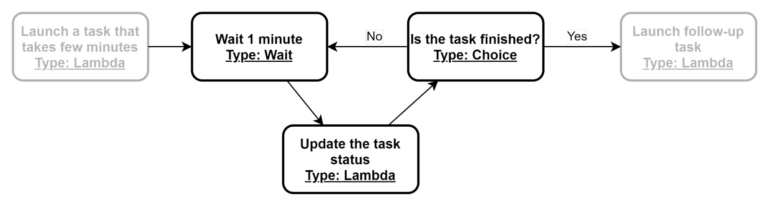
On combine trois types d’état de Step Functions : le Wait, le Choice et la Task (une Lambda).
Alors quel est le problème pointé par mon étudiant ? Hé bien, Step Functions est facturé à la transition d’état : chaque fois que la State Machine passe d’un état à l’autre, ça nous coûte $0.000025 (soit $0.025/1000 transitions, au-delà du Free Tier de 4000 transitions).
Et il me fait remarquer que cette façon d’attendre est jolie sur papier, mais quand on est dans une situation où la Step Fonction est exécutée plusieurs fois par seconde, ça douille. Chaque “tour de boucle” coûte 3 transitions, or on peut faire mieux. On peut faire en sorte que chaque “tour” ne coûte qu’une seule transition. Ce qui est 3 fois moins. Et donc à l’échelle, ça peut faire une économie substantielle. On en vient donc à la fameuse astuce, qu’il me révèle : je peux obtenir exactement le même comportement en utilisant le mécanisme de Retry natif à Step Functions !
Ça a tout de suite fait “clic” dans ma tête et je me suis dit “Bon sang, mais c’est bien sûr”. Et je me suis dit qu’il fallait en faire un article au cas où, comme moi, d’autres personnes étaient passées à côté de cette possibilité.
Optimiser une boucle d’attente Step Functions
Pour illustrer la transformation, je vais simplement prendre des exemples de code simples (mais fonctionnels), afin que chacun puisse apprécier la transformation à appliquer.
Version “naïve” de la boucle d’attente
Premièrement, la Lambda “Update the task Status”. Le principe de ce genre de Lambda, c’est qu’elle répond à la question “est-ce que c’est fini ?”, généralement en faisant un call à l’API AWS sur le service approprié en fonction du cas. Pour les besoins de la démo, je vais juste faire une fonction qui répond aléatoirement “True” ou “False” à cette question.
De fait, le code de notre Lambda de démo est trivial :
import random
def is_finished():
# Will return True 10% of times, False 90% of times
return random.random() > 0.9
def lambda_handler(event, context):
# Return a boolean that tells the calling
# Step Function whether or not the task is finished
return is_finished()
Ensuite la Step Function, gardons la simple aussi : je ne vais modéliser que la boucle et l’état qui suit la boucle. Seule la boucle elle-même est importante pour la démonstration de toute façon :
{
"Comment": "Demo state machine",
"StartAt": "UpdateStatus",
"States": {
"UpdateStatus": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:123456789012:function:demo-update-status",
"ResultPath": "$.task_finished",
"Next": "IsFinished?"
},
"IsFinished?": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.task_finished",
"BooleanEquals": true,
"Next": "Success"
}
],
"Default": "Wait"
},
"Wait": {
"Type": "Wait",
"Seconds": 5,
"Next": "UpdateStatus"
},
"Success": {
"Type": "Succeed"
}
}
}
Notez que dans UpdateStatus, je place le résultat de la lambda dans un nœud “task_finished” de mon payload, et je teste ce même nœud à l’étape de “Choice” qui suit.
Si vous déclarez cette State Machine dans Step Functions, vous obtenez cette visualisation :
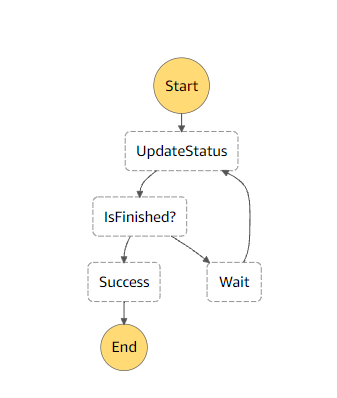
Bien sûr, adaptez l’état “UpdateStatus” avec l’ARN de votre propre Lambda de démo. Vous pourrez constater que ça fonctionne bien. Et comme le faisait remarquer mon étudiant, chaque tour de la boucle d’attente consomme 3 transitions d’état. Voyons comment faire mieux en utilisant le Retry.
Version optimisée de la boucle d’attente
L’idée centrale consiste à faire exprès de jeter une exception lorsque la tâche n’est pas terminée et ainsi de profiter du mécanisme de Retry fourni par Step Functions. On peut adapter assez facilement n’importe quelle boucle d’attente pour faire ça. Voyons avec notre exemple.
Pour commencer, la Lambda ne renvoie plus “True” ou “False”. Elle jette une exception spécifique si c’est “False” et ne fait rien sinon :
import random
# Define a specific exception
class NotFinished(Exception):
pass
def is_finished():
# Will return True 10% of times, False 90% of times
return random.random() > 0.9
def lambda_handler(event, context):
# Raise an exception if not finished
# Else do nothing
if not is_finished():
raise NotFinished()
Ensuite, il faut adapter la définition de la State Machine. Du côté code, on la simplifie :
{
"Comment": "Demo state machine",
"StartAt": "UpdateStatus",
"States": {
"UpdateStatus": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:123456789012:function:demo-update-status",
"Next": "Success",
"Retry": [
{
"ErrorEquals": [
"NotFinished"
],
"IntervalSeconds": 5,
"MaxAttempts": 99999999,
"BackoffRate": 1
}
]
},
"Success": {
"Type": "Succeed"
}
}
}
Par contre, la boucle n’est plus du tout visible sur la représentation de notre State Machine :
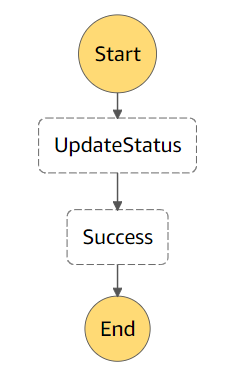
Pourtant, si vous testez, le comportement est exactement le même ! En utilisant un intervalle de retry de 5 secondes, on “simule” notre “Wait” tandis que le “Choice” est remplacé par l’échec ou non de la Lambda. Notez qu’il est important d’explicitement définir le BackoffRate à 1 pour que l’intervalle de retry reste fixe. De même, choisissez un MaxAttempts suffisamment élevé (le maximum est 99 999 999).
Chaque Retry consomme 1 seule transition d’état au lieu de 3 !
Avantages de la solution
J’espère que vous pouvez voir avec ce simple exemple qu’il est toujours possible de faire cette adaptation sans changer le moins du monde le comportement fonctionnel. On économise simplement 2 transitions par tour, sans contrepartie. Certains diront qu’on ne peut plus attendre indéfiniment puisqu’on est obligé de définir un MaxAttempts pour le Retry, mais :
- En réalité on ne veut jamais vraiment attendre pour l’éternité, on veut au contraire toujours avoir une limite, fusse-t-elle extrêmement élevée ;
- Avec 100 millions de Retry manimum, même à 1 seconde d’attente ça fait 3 ans ! Soit au-delà du temps d’exécution maximum d’une State Machine (1 an).
Donc vraiment : c’est un gain sans contrepartie (merci cher étudiant !)
Même si vous utilisez déjà le mécanisme de Retry pour autre chose, vous pouvez quand même utiliser cette astuce car la Step Function sait différencier les exceptions et traiter chacune différemment : il suffit donc d’utiliser une exception dédiée pour faire la « boucle d’attente », comme dans l’exemple.
Et en réalité, puisque vous avez à disposition un BackoffRate et un MaxAttempts, il est possible de définir des mécaniques plus complexes. Avec simplement un “Choice” et un “Wait”, on ne peut pas facilement gérer un “temps d’attente” maximum ou une augmentation du temps d’attente au fur et à mesure. Alors que le Retry propose nativement ces fonctionnalités.
On pourrait aussi parler du “Catch”, qui n’est pas vraiment dans le scope de notre article, mais qui permet lui aussi de faire de belles choses. Notamment, n’importe quel “Choice” qui teste le résultat d’une Lambda peut être optimisé avec un Catch. Tous ces concepts sont très bien expliqués par la documentation AWS.
Un bémol survient si vous avez l’habitude d’utiliser une alarme CloudWatch pour signaler les échecs de vos lambdas. En effet, CloudWatch ne saura pas que l’exception levée par votre lambda est volontaire et comptera cela comme un échec d’invocation de la lambda.
Un ch’tit calcul pour la route
Pour les FinOps, sachez ceci :
Une transition Step Functions est facturée $0.000025.
Une invocation lambda coûte $0.0000002.
Et une seconde d’exécution Lambda (128MB de RAM) coûte $0.0000020833375.
Si vous devez faire des “sleep” en boucle dans une Lambda, il devient rentable de les remplacer par une Step Function avec une mécanique d’attente si le prix combiné des transitions d’état et d’une invocation est inférieur à celui du “sleep”. Le seuil dépend donc de la durée du “sleep”.
Soit x la durée du sleep en seconde, la formule est donc:
x*(prix_par_seconde_execution_de_lambda) > prix_invocation_lambda + nbr_transitions*prix_transition_step_fonctions
La durée au-delà de laquelle il est rentable d’utiliser une Step Function “non optimisée” (3 transitions par boucle d’attente) est donc:
x*0.0000020833375 > 0.0000002 + 3*0.000025
Soit x > 36 secondes.
Avec une Step Function “optimisée” (1 transition par boucle d’attente):
x*0.0000020833375 > 0.0000002 + 0.000025
Soit x > 12 secondes.
Messieurs et mesdames les FinOps, bonne chasse au sleep ! (à ne pas confondre avec la fête du slip, c’est différent).
Commentaires :
A lire également sur le sujet :




