
Salon Big Data et AI : des sujets systémiques qui impactent toute l’entreprise

7500 participants sur place et 4500 à distance, 150 exposants et 280 conférences, le salon Big Data & AI a fait le plein après une édition 2020 annulée pour cause de pandémie. S’il est impossible d’en faire un compte-rendu exhaustif, j’essaierai tout de même dans cet article de faire le point sur ce que j’ai retenu de ces deux journées très denses. Les problématiques soulevées sont un reflet assez fidèle de celles rencontrées chez nos clients : la data est un sujet global, qui concerne l’ensemble de l’entreprise et s’apparente à la transformation digitale par son impact à l’échelle de toute l’entreprise.
Data et IA, des sujets systémiques
On pense souvent la Data et l’IA sous le prisme technologique uniquement, là où le domaine soulève également de très forts enjeux au niveau de l’humain et de l’organisation.
Les démarches Data-driven réussies sont celles qui traitent tous les aspects de la données de façon End-to-End : de la saisie des données jusqu’à son exploitation sous forme de cas d’usage analytics ou data science. La qualité des données (la matière première) est essentielle, et dans nombre d’entreprises le début de la chaîne de production est une saisie manuelle par des opérateurs.
Cette saisie alimente tous les pipelines de données qui raffinent, transforment, structurent les données pour en extraire toute la valeur et améliorer les prises de décisions de l’organisation. On comprend que la qualité de la donnée ne peut être traitée uniquement par une équipe ad-hoc, qui soit doit mettre beaucoup d’énergie pour rétro-engineerer les données, ou qui peut se trouver dans l’impossibilité de retrouver des données mal saisies initialement. En transposant le modèle de Jones Capsers dans son livre Applied Software Measurement: Global Analysis of Productivity and Quality sur le coût d’un bug logiciel en fonction de sa découverte, si on remplace le coding par la saisie de la donnée, on a un ordre de grandeur de l’impact d’une donnée de qualité insuffisante :
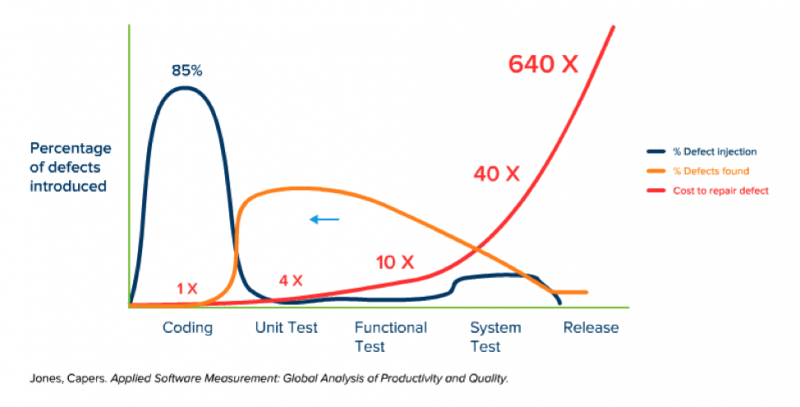
On prend conscience que le besoin d’acculturation, au travers de formations, de sensibilisation dès l’onboarding, est très fort pour améliorer la donnée dès la source. On l’englobe sous le terme de Data Literacy, et j’ai beaucoup aimé l’anecdote de Jennifer Belissent, Principal Data Strategist chez Snowflake, qui illustre bien le concept.
Quand les ventes de saucisses au petit-déjeuner d’un hôtel ont bondi plusieurs jours d’affilée, le responsable a décidé d’aller constater la situation par lui-même avant de commander automatiquement des stocks supplémentaires. Après analyse de la situation, il s’est avéré que les chargés de caisse, qui n’avaient pas été formés, saisissaient par défaut toutes les petites commandes de petit déjeuner avec la touche « Saucisse » faisant exploser les statistiques de consommation de saucisses. Ils étaient loin de se douter que leurs saisies étaient le point de départ de toute une chaîne de décision.
La Data Gouvernance et le Data Management ont également été au centre de nombreux talks; ces sujets étant assez vastes pour faire l’objet d’un article à part entière, ils ne seront donc pas traités ici.
Une stratégie business Data driven : le retour d’expérience de Unique Heritage Media
Une des promesses (une arlésienne?) des projets Data/IA est de permettre de driver de meilleures décisions business pour augmenter ses ventes, optimiser sa marge… Chez des acteurs majeurs (de taille Cac 40) le ROI s’avère difficile à chiffrer, et les apports d’une stratégie Dava-driven ne se mesurent pas immédiatement de façon tangible. Le niveau de complexité structurelle, comptable, organisationnelle, et business font que les acteurs pressentent que la balance bénéfice/coût est positive, mais peu sont capables de chiffrer précisément les bénéfices de tel projet, cas d‘usage ou démarche Data.
Pour se projeter plus facilement les ETI sont de parfaits candidats et j’ai beaucoup apprécié le talk d’Unique Heritage Media (UHM), entreprise de médias et d’édition dédiée à la jeunesse et son entourage avec notamment des titres comme le Journal de Mickey ou Picsou Magazine, qui ont rendu très palpable leur “Data journey”.
Dans un contexte difficile de forte baisse de l’édition papier depuis des années, leurs enjeux business étaient de réduire le taux d’invendu, d’améliorer la marge et de préserver le CA. Il ont adopté une démarche incrémentale et itérative avec du Machine Learning pour optimiser le nombre d’exemplaires envoyés en point de vente. Cette optimisation est faite en fonction des magazines, de leur saisonnalité, et se base sur un historique de 5 ans et 13 millions d’observations.
Les résultats sont significatifs : + 10 points de marge, + 6 points de vente annuel, -25% papier utilisé.
On prône généralement des processus automatisés pour limiter les erreurs, améliorer la résilience etc., mais empiriquement UHM a découvert que les résultats étaient bien meilleurs quand les modèles étaient agrémentés de retour terrains qualitatifs et d’insights des collaborateurs au contact direct avec les partenaires terrains. Ces retours ont une place prépondérante dans le processus et ont permis, par effet de bord, une meilleure adhésion des collaborateurs à la démarche.
De la place de l’IA dans la société… à sa régulation ?
Éthique, conformité, IA de confiance ou encore sobriété numérique : les enjeux sociétaux et environnementaux ont été omniprésents dans les débats. Les entreprises se préparent notamment à s’adapter au règlement européen sur l’IA, dont les impacts sont attendus comme majeurs, mais aux contours encore flous (ce sujet fera l’objet d’un article prochainement sur le blog).
Parmi les conséquences de cette réglementation, citons l’explicabilité des modèles: toute entreprise devra être en mesure de détailler le fonctionnement d’un algorithme à l’origine d’une prise de décision. Pourtant, peu d’acteurs ont aujourd’hui suffisamment de maîtrise et de maturité pour s’engager dans la démarche de rendre leurs modèles explicables. Le challenge actuel est d’arriver à mettre en production leurs modèles et de les industrialiser au sein du SI, l’explicabilité viendra ensuite.
A contrario, le Groupe La Poste s’est déjà engagé dans une démarche volontariste. Muriel Barnéoud, directrice de l’engagement sociétal du groupe, a ainsi présenté la mise en place de la charte Data et IA, largement inspirée du règlement européen avec l’ambition d’une approche éthique by design. Certains des principes de cette charte IA se traduisent concrètement par des obligations, comme d’avertir les clients quand ils interagissent avec une IA (chatbot…), de systématiquement proposer une alternative humaine. Le groupe prône également la transparence, avec l’explicabilité des modèles et l’interdiction de certains usages contrôlés par un comité d’éthique.
Au rang des enjeux sociétaux, on a aussi pu constater l’émergence d’initiatives autour de la sobriété numérique, et qui vont au-delà de la Data et de l’IA : mesure de l’empreinte carbone, migration vers le cloud pour n’utiliser que des ressources à la demande, développement frugal by design, limitation de l’usage aux date indispensables, limitation des duplications de données… Des réflexions sur une conception eco-score des services, sur le modèle du nutri-score, sont en cours et s’avèrent très prometteuses.
Tendances Cloud et no code
Ce salon était également l’occasion de prendre la mesure de l’évolution du marché de l’édition, et force est de constater la montée en puissance des solutions Cloud based. Si les trois principaux Cloud providers, AWS GCP et Azure étaient absents, l’immense majorité des solutions proposées sur le salon était basée sur le Cloud. On notera aussi de très nombreuses solutions low-code / no-code, qui ambitionnent de sortir la Data de “l’IT pour l’IT”, et d’armer les équipes métiers à exploiter eux-mêmes les données qui les intéressent. Et les incitent à mettre en production des nouveaux cas d’usages, avec peu voire aucune connaissance technique.
On terminera sur un talk un peu inclassable et ludique de Mathilde CARON, Research Assistant CIFRE, sur l’état de l’art avec les réussites, difficultés et promesses de l’apprentissage auto-supervisé en deep learning. Ce type de modèle va complexifier encore plus la mise en application des concepts d’explicabilité des modèles.
En effet, comment être mesure d’expliquer le processus décisionnel d’un modèle qui a lui-même supervisé son propre processus d’apprentissage sans aucune intervention humaine ?
Commentaires :
A lire également sur le sujet :




