
Retour d’expérience sur l’industrialisation des modèles Data Science avec une approche MLOPS: Dataiku

L’industrialisation de la data science est un sujet qui intéresse beaucoup d’entreprises de nos jours. Il ne s’agit pas seulement d’un sujet technique : IT, métier et organisation doivent être adressés en même temps. Dans cet article, nous vous présenterons des retours d’expérience client afin d’exposer les solutions apportées aux problématiques rencontrées, et nous ferons un focus sur la solution Data Science de Dataiku.
Introduction
Il y a quelques dizaines d’années, la data science était une discipline purement théorique développée principalement dans les universités et les laboratoires de recherche. Aujourd’hui, le monde de l’entreprise investit dans des projets Data Science dans le but de créer de la valeur. Ceci nécessite une maturité importante des process opérationnels, qui sont plus adaptés aux exigences des systèmes IT traditionnels mais malheureusement pas aux modèles de Machine Learning.
Une étude réalisée par Algorithmia montre que 50% des entreprises passent entre 8 et 90 jours à déployer un seul modèle d’IA en production. Ce temps non négligeable est du aux contraintes qui ralentissent le process de mise en production. L’approche MLOPS permet de répondre à ces enjeux.

Pain Points des systèmes ML
MLOPS?
Le MLOps est une discipline récente qui vise à la collaboration et à la communication entre les data scientistes et les professionnels de IT (Data Engineers, Infrastructure Engineers, IT Operations…) afin d’automatiser les tâches récurrentes dans le cycle de vie Machine Learning.
Grâce aux outils et pratiques, le MLOps établit une culture et un environnement dans lesquels les technologies ML peuvent générer la plus value. Cette approche considère que le modèle n’est pas le produit final à livrer aux Ops, mais il sera encapsulé avec d’autres composantes indispensables à l’inférence (Data pipeline, Code pipeline).
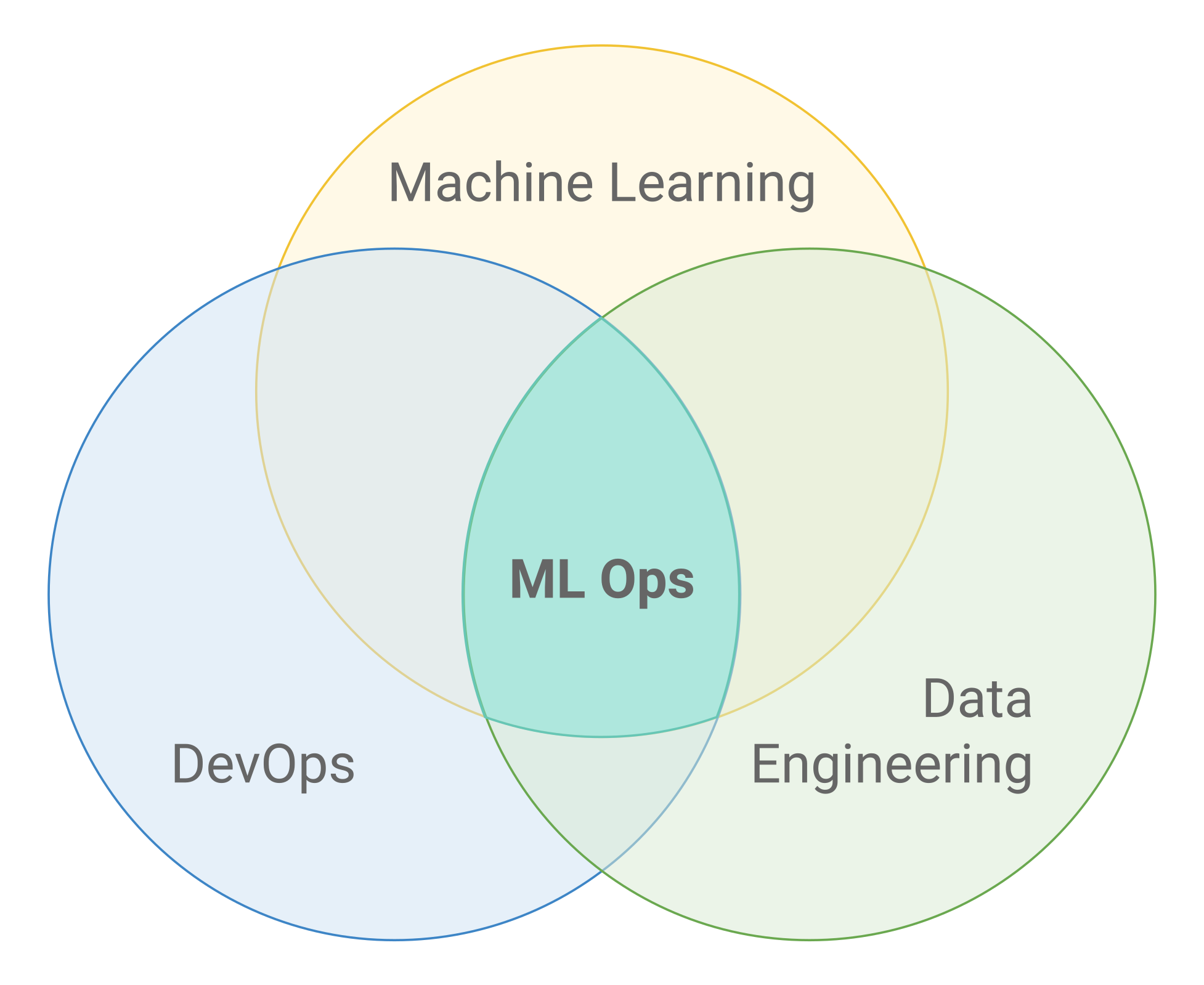
Le ML OPS à l’intersection de plusieurs domaines
Challenges
Les challenges de l’approche MLOPS ressemblent à ceux du DevOps certes, mais il existe des spécificités ML déclinées dans le tableau ci-dessous :
| Spécificités ML | Description |
| Versioning des Data/Modèle/Hyperparamètres | Versionner les données Versionner le modèle Versionner les hyperparamètres |
| Expérimentations | Feature Engineering Tracer les expérimentations |
| Testing | Tests de qualité de données Tests des prétraitements |
| Monitoring | Suivi en continu des métriques de santé et de performances du modèle en production. Consommation des ressources par modèle |
| Automatisation | Transformation des données Réentrainement des modèles Evaluation des modèles Sélection/Optimisation des modèles |
| Reproductibilité | Revenir sur une ancienne version du modèle et ses inputs ( training/test datasets, hyperparamètres) |
| Auditabilité | Assurer l’intégrité des données/modèles Persistance des logs d’audit Assurer la conformité avec les politiques entreprise et les réglementations associées |
| Scalabilité | Mise en échelle de l’infrastructure qui héberge le modèle pour garantir le niveau de service attendu |
Nous allons voir maintenant dans quelle mesure la solution Dataiku peut répondre à ces challenges.
Retour d’expérience client sur Dataiku
Définition
Dataiku une plateforme de collaboration dédiée aux Data Scientists, permettant d’explorer, construire, livrer et déployer des modèles de machine learning. Sa force réside dans la simplicité et l’accessibilité des fonctionnalités pour créer des workflows de préparation de données, d’entraînement et de déploiement des modèles. La solution se positionne parmi les leaders du marché.
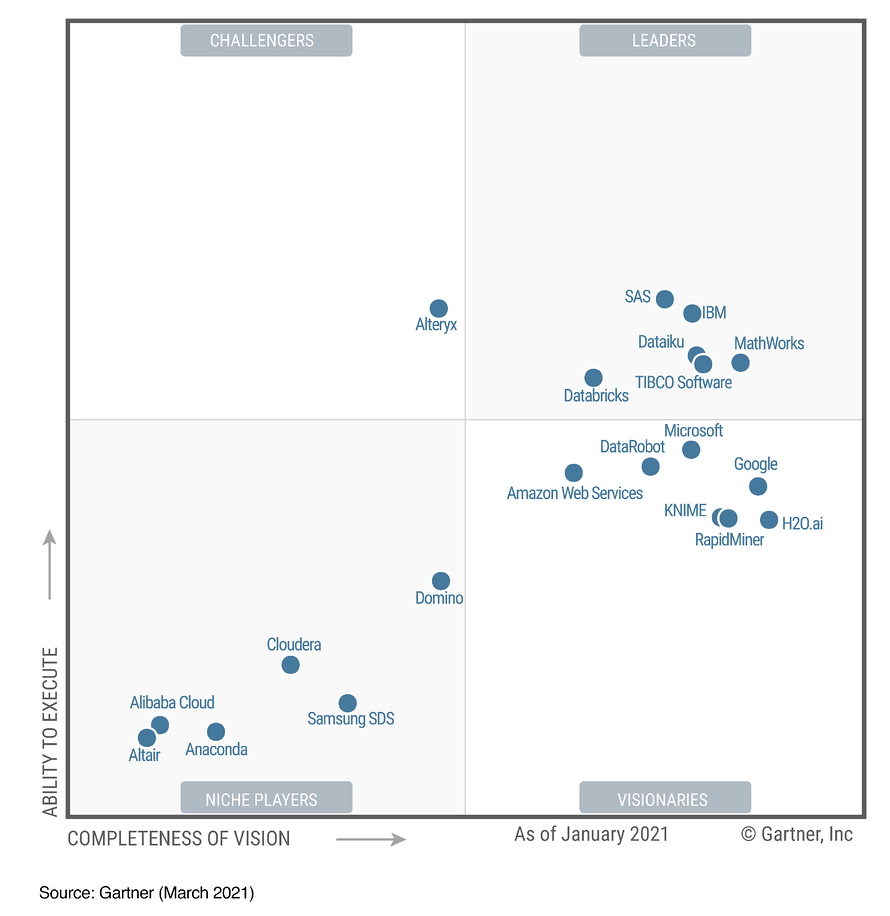
Magic Quadrant des solutions Machine Learning
Architecture
L’architecture se base sur 3 types d’instances. Une instance Dataiku DSS est une installation du produit qui répond aux besoins d’un environnement particulier :
- Le Design Node, dans l’environnement de développement, est utilisé pour créer les pipelines qui transforment les données en outputs, telles que les données transformées, les modèles, les tableaux de bord et les rapports.
- L’Automation Node, dans l’environnement de production, place les pipelines du Design Node en production.
- L’API Node, dans l’environnement de déploiement, rend les sorties de modèle du Design Node disponibles pour une consommation en mode API pour le scoring en temps réel.
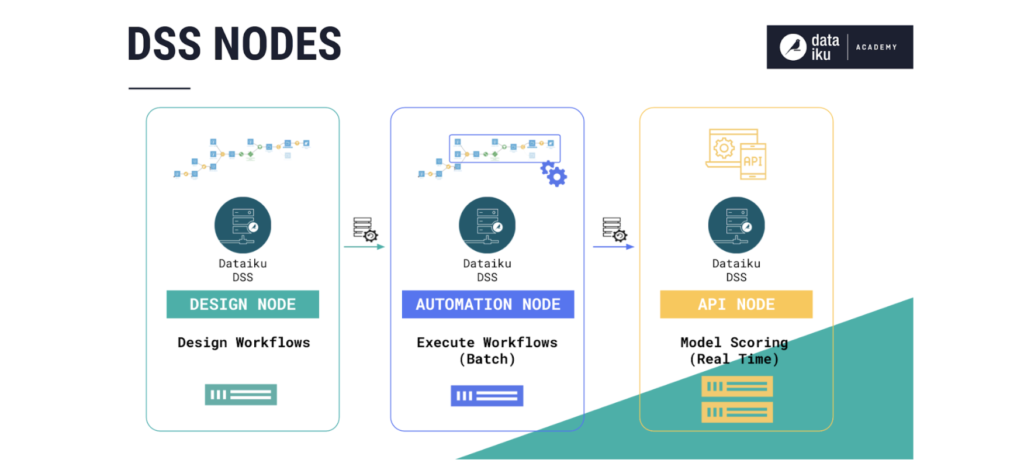
Types d’instances sur Dataiku
Retour d’expérience Client
Nous avons recueilli des témoignages de la part de nos clients acteurs des secteurs de transport, énergie, finance et luxe. Certains utilisent Dataiku pour des applications en production en intégrant la solution comme brique de leurs plateformes Data. D’autres utilisent la solution pour des usages ponctuels de PoC sans un fort impact sur l’activité de l’entreprise. Nous allons synthétiser ces retours d’expérience par domaine d’expertise: Machine Learning, Software Engineering, et Software Operations.
Machine Learning
Dataiku est une solution orientée machine learning, elle répond à la majorité des problématiques de data science telles que l’exploration et la préparation de données et aussi l’entrainement, l’évaluation et le tacking des modèles.

Software Engineering
Vu que Dataiku est une solution propriétaire, elle n’est pas vraiment ouverte aux outils de CI/CD (Référentiels Git, Package Management, automation tools, artifact management…). Nos clients ont remarqué qu’il existe une grande complexité pour intégrer leurs usines logicielles d’outillage CI/CD avec DSS Dataiku.

Software Operations
Dataiku DSS peut héberger des modèles en production mais avec quelques limites techniques. Nos clients ont remarqué que la solution gère mal les projets DSS qui comprennent un grand nombre de modèles. Le produit reste limité en terme de logging, d’automatisation de Delivery entre les noeuds (export et import manuels des bundles).

Autres retours
Enfin, nous avons aussi recensé d’autres retours par rapport à la qualité du support, la documentation officielle, les moyens de collaboration sur la plateforme, la sécurité et le modèle de licensing.

Recommandations
Niveaux de maturité MLOPS
Avant de passer aux recommandations, il est important de décrire les différents niveaux de maturité MLOPS possibles pour une entreprise, et de s’y positionner en se basant principalement sur le contexte organisationnel.
Niveau 0
Un niveau basique où le ML ne fait pas partie des priorités de l’organisation. Le management est généralement sceptique quant à la valeur du ML. D’un côté, certains PoCs peuvent être lancés mais vu que l’organisation ne suit pas, les pratiques MLOPS ne peuvent pas être mises en place. D’un autre côté, l’architecture et la gouvernance sont absentes vu qu’il n’y a pas de run critique.
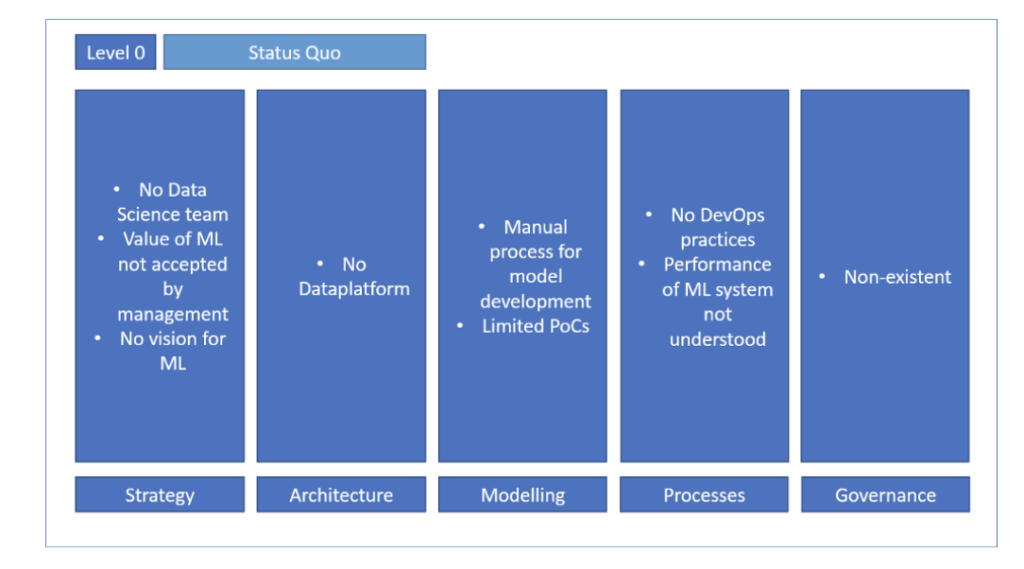
Niveau de maturité 0
Niveau 1
À ce niveau, le modèle ML produit déjà un retour sur investissement. Sur le plan technique, le développement se fait généralement en local ou dans des plateformes de collaborations dédiées pour l’expérimentation. De plus, les pratiques DevOps telles que le contrôle de version et le CI/CD existent mais elles ne sont pas utilisées pour les systèmes ML.

Niveau de maturité 1
Niveau 2
Les organisations de ce niveau ont progressé dans la structuration de leur workflow ML. Cependant, elles ont encore du mal à fournir de la valeur de manière mesurable en raison d’un manque de coordination dans la phase de déploiement et de run . L’organisation acquiert l’expérience pour le management du cycle de vie des modèles.

Niveau de maturité 2
Niveau 3
À ce niveau, le MLOPS devient une méthode grâce à la réussite des projets. De plus, le ML est sponsorisé par le management et l’intégration du ML est envisagée pour chaque projet majeur. Sur le plan technique, les pipelines DevOps et ML convergent et partagent les même release pipeline. Le monitoring, lui, permet de mesurer et de rapporter les facteurs hygiéniques (par exemple: Data Drift) du système ML. La gouvernance mûrit et comprend la mise en œuvre de politiques de sécurité.
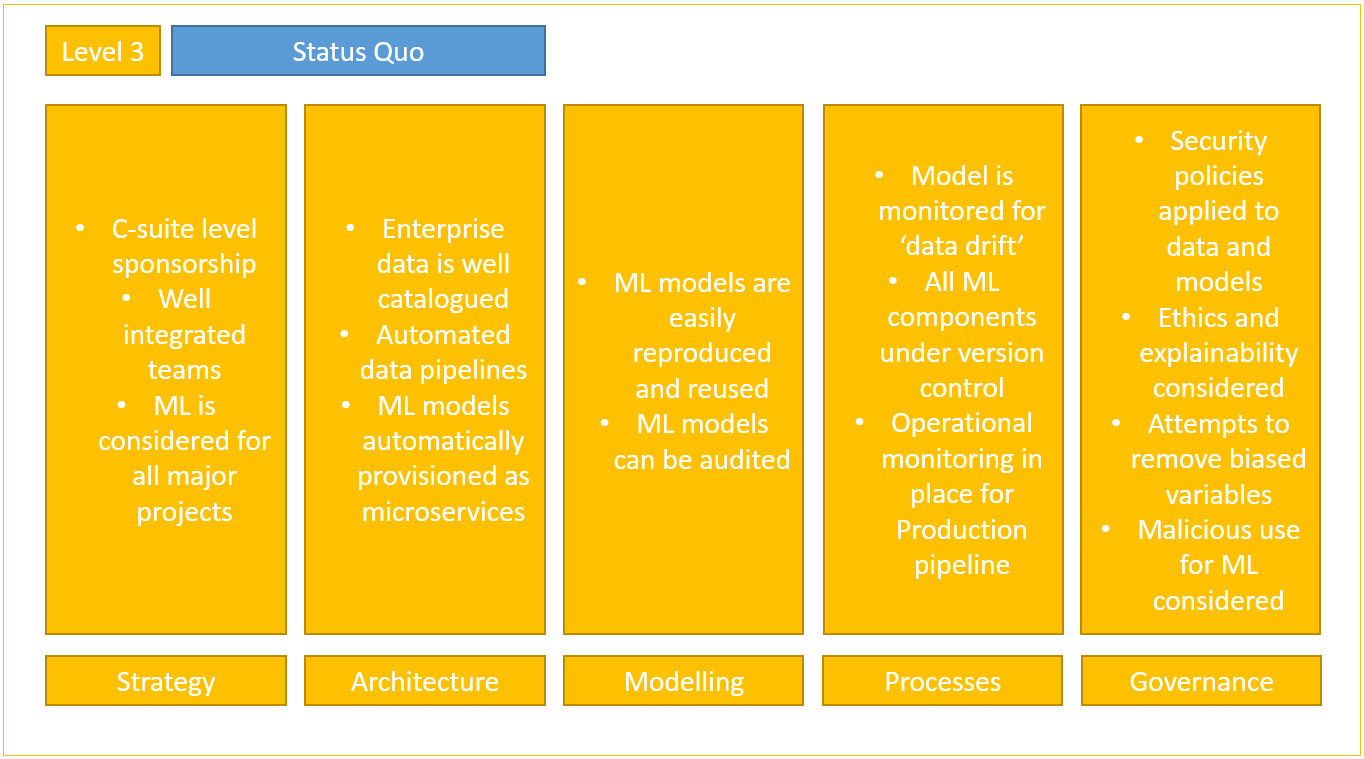
Niveau de maturité 3
Niveau 4
A ce niveau, on parle des organisations leaders en ML, qui considèrent le ML comme un atout stratégique. L’équipe ML possède un processus bien géré pour la livraison. L’impact des petits changements sur les modèles ML peut être mesuré et de nouvelles approches algorithmiques peuvent être testées à grande échelle, une propriété clé des organisations MLOps matures. De plus, elles commencent à partager leurs expériences avec des partenaires de l’industrie.
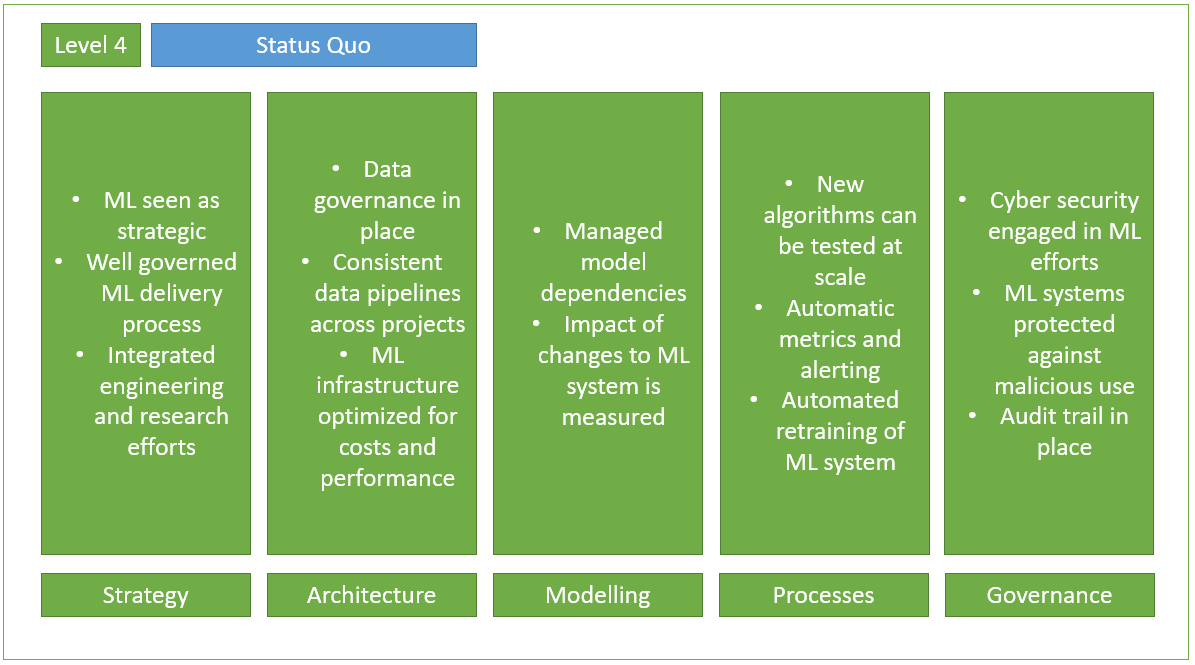
Niveau de maturité 4
Cas dans lesquels Dataiku est adaptée
La solution de Dataiku est bien adaptée aux niveaux de maturité 0 et 1 où le ML peut rapporter du ROI à l’entreprise. Des équipes à petite taille sont autonomes sur tout le cycle de vie des modèles du développement jusqu’à la production pour des applications non critiques.
Cas dans lesquels Dataiku n’est pas adaptée
Dataiku DSS ne sera pas adaptée pour les niveaux de maturité 2, 3 et 4 parce que la solution n’est pas encore prête pour répondre aux pratiques MLOPS (Data Versioning, Tracking des expérimentations, Testing, Feature Engineering…). D’un point de vue exploitation, la solution n’est pas conçue pour gérer les logs des modèles (activité, audit sécurité, exploitation…).
Conclusion
Le choix de la plateforme de Data Science ne dépendra pas seulement des besoins et contraintes liées à vos projets ML (volumes des modèles en production, fréquence des évolutions, ré-entraînement), mais il dépend notamment de la maturité MLOPS de l’organisation. A savoir, principalement la taille des équipes de développement ML, leur proximité avec les équipes OPS, les outils de Data Science déjà utilisés dans les projets, la criticité des modèles et aussi les stratégies d’adoption du Machine Learning dans une organisation. Avant de décider sur le choix d’une solution, il faut prendre en considération ces aspects.
Références
Hidden Technical Debt in Machine Learning Systems
MLOps – “Why is it required?” and “What it is”?
ML Ops: Machine Learning as an Engineering Discipline
Commentaires :
A lire également sur le sujet :






