
Retour d’expérience sur AWS Glue et son écosystème

Lorsqu’on souhaite construire un pipeline d’ingestion de données sur AWS, outre le pattern d’architecture (event-driven, serverless, ou un mixte des deux, etc), le choix des services à utiliser est à prendre en considération. Dans le cadre d’un projet, nous avons opté pour un pipeline Serverless avec comme service central AWS Glue. Nous partageons dans les lignes qui suivent notre retour d’expérience sur cet outil et son écosystème, Glue Crawler, Glue Datacatalog et Glue Job.
AWS Glue, service managé
Glue est un service AWS totalement géré et sans serveur. Il permet de découvrir la donnée présente, la cataloguer, la transformer et la stocker selon les standards voulus par notre besoin. Pour ce faire, il se base sur trois composants principaux : Glue Crawler, Glue Data Catalog et Glue Job :
- Glue Crawler est le service qui permet de découvrir les données dont nous disposons et de créer un catalogue unique les décrivant via Glue Data Catalog.
- Glue Job (ou Glue ETL) quant à lui, se base sur le catalogue pour extraire les données avant de les transformer (via Spark) et les stocker à nouveau selon notre besoin.
Notre besoin
Le besoin auquel nous devions répondre était de collecter des données provenant de diverses sources on-premise, puis de les harmoniser, les stocker et les mettre à disposition d’entités qui valoriseraient ces données.
Pour y répondre nous avons convenu qu’il nous fallait un outil d’ETL (Extract Transform and Load). Nous avons donc choisi le composant Glue Job comme outil ETL. Cependant, avant de réellement utiliser Glue Job, nous avons dû explorer les données qui nous seraient fournies. Cela nous a amené à utiliser également Glue Crawler et Glue Data Catalog.
A travers ce cas client, nous allons voir comment nous en sommes venus à choisir Glue Job comme outil ETL, ainsi que les bénéfices apportés par Glue Crawler et Glue Data Catalog, malgré les limitations auxquelles nous dûmes faire face.
Choix de Glue comme service ETL dans notre pipeline d’ingestion
Comme tout architecte Data sur le cloud, nous nous sommes posé les questions suivantes pour l’élaboration de notre pipeline d’ingestion et le choix de Glue comme outil ETL :
Quelles sont les architectures de référence sur AWS pour un pipeline d’ingestion ?
Pour répondre à cette question, le blog Big Data d’AWS propose plusieurs ressources abordées avec une approche pédagogique et pratique. Nous vous recommandons particulièrement les articles suivants comme point de départ d’une réflexion sur l’architecture à choisir en fonction de votre cas d’utilisation:
Quels services choisir pour la partie ETL ?
Sur AWS, pour nos pipelines ETL, nous pouvions utiliser au choix Glue Job, EMR, ou un outil du marché qui tournera sur EC2. Nous avions fait le choix de partir sur Glue Job.
Pourquoi avoir choisi Glue Job ?
Nous avons principalement choisir Glue Job parce qu’il est totalement géré et sans serveur. Cela nous a permis d’avancer rapidement sur la construction du pipeline et de nous concentrer sur l’harmonisation au format parquet et les transformations de la donnée. De plus, ces jobs Glue d’harmonisation et transformation peuvent être développés en Spark. Nous parlerons plus en détail des raisons de notre choix dans les paragraphes suivants.
Comment utiliser Glue Job?
La documentation du service, de même que le developer guide sont de bonnes ressources pour commencer à utiliser Glue Job. En plus de la documentation, nous avons simplement mis les mains sous le capot et expérimenté, afin de forger notre propre opinion sur ce service et comment en tirer partie. L’une des subtilités de Glue Job est le fait de passer par GlueContext et DynamicFrame à la place de SparkContext et DataFrame lorsqu’on veut développer en Spark. Plus de détails seront donnés sur l’utilisation de ce service dans les paragraphes suivants.
Architecture technique du pipeline
Voici, de façon très simplifiée, l’architecture que nous avons choisie :
- Réception dans un bucket S3 des données provenant de bases de données relationnelles on-premise (zone de collecte),
- Harmonisation et stockage au format parquet (zone d’harmonisation et de stockage),
- Catalogage des données afin d’être utilisables par les utilisateurs finaux sur des services tiers comme Athena (zone de mise à disposition).
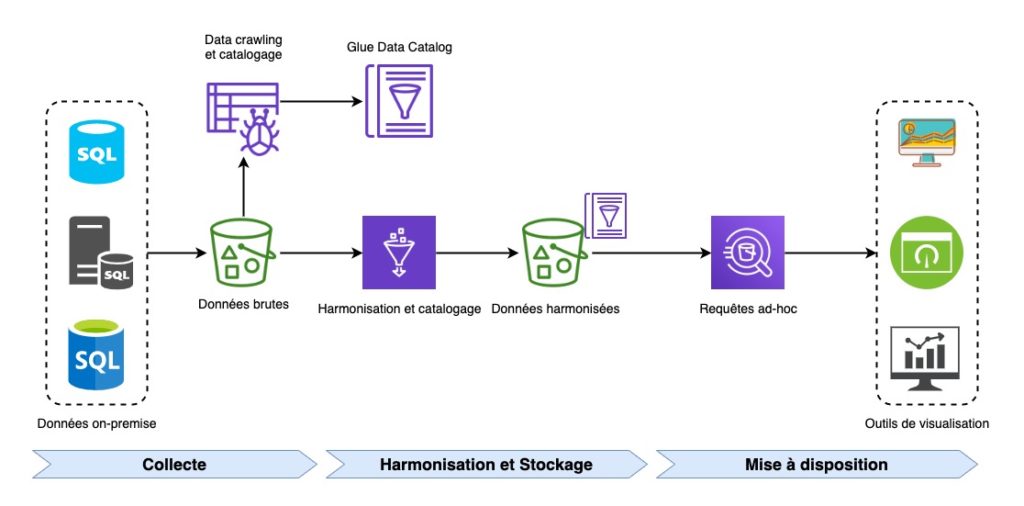
Dans ce schéma vous constaterez que les données sont fournies (de manière brute, sans aucune transformation) depuis des bases de données relationnelles dans un bucket S3 (données brutes). Un Crawler Glue est ensuite exécuté pour découvrir ces données et enrichir un Data Catalog. Un Glue Job est alors lancé pour transformer ces données, les cataloguer à nouveau et les stocker sur S3 (données harmonisées).
A partir des catalogues des données brutes et harmonisées, on peut ainsi requêter les données via Athena.
Nous allons maintenant analyser chaque étape de ce pipeline afin d’en tirer les leçons apprises lors de l’utilisation de Glue.
Data crawler
Ce service permet de créer un ou des “crawler”. Un “crawler” est un outil qui ira inspecter les données contenues dans une source (S3 pour notre cas), déterminer certaines metadata telles que le format, le schéma et les éventuelles partitions.
Avantages de Glue Crawler :
- Dans notre scénario, nous avons trouvé ce mécanisme de crawler très pratique surtout au début du projet afin de découvrir rapidement à quoi ressembleraient les données qui nous étaient soumises en entrée du pipeline.
- Pas besoin de configuration complexe pour mettre en place le crawler, tout est serverless et on ne paye qu’à l’exécution en fonction de la taille des données inspectées.
- Le crawler crée ou met à jour le catalogue selon que la donnée soit déjà cataloguée ou pas.
Limitations de Glue Crawler :
- Le crawler ne détecte pas les changements de donnée de manière native. Il faut régulièrement faire tourner le crawler via une tâche planifiée ou bien l’intégrer à un workflow détectant les changements sur les données pour que les mises à jour soient prises en compte.
- Le crawler n’est pas très optimal avec du CSV de type string. Lorsque toutes les colonnes du CSV sont de type string, alors la première ligne n’est pas considérée comme le header. Pour remédier à ce problème il faut utiliser un custom classifier.
- Il faut utiliser un custom classifier pour les cas complexes, ce qui retire tout l’avantage du service managé.
- Le fait d’utiliser des données en .parquet ou .avro en entrée nous évite les deux limitations précédentes. Cependant, fournir des fichiers au format parquet en entrée n’est pas évident pour tous les fournisseurs de données.
Data Catalog
Une fois le crawler exécuté, les metadata (emplacement de la donnée, format, schema, etc.) des données sont répertoriés dans un catalogue via Glue Data Catalog. Glue Data Catalog est le service AWS compatible Apache Hive metastore.
Avantages de Glue Data Catalog :
- Dans notre cas d’usage, le Data Catalog était la continuité du crawler. Une fois la donnée brute cataloguée, on pouvait la requêter et la visualiser via Athena. Notre première tâche de défrichage de la donnée se trouvait ainsi facilitée.
- Le Data Catalog est la source unique de vérité (single source of truth). Tout outil de requêtage de la donnée (Athena par exemple), n’a pas à se soucier du format ou de l’emplacement de la donnée. Il se base juste sur les infos renvoyées par le Data Catalog. Cela implique cependant que le catalogue soit continuellement mis à jour vis à vis de la donnée stockée.
- La construction des dashboards est simplifiée même pour des outils externes à AWS. On peut par exemple utiliser le driver odbc d’Athena pour permettre à un outil tiers d’utiliser Athena et le catalogue Glue pour requêter les données et construire des dashboards.
- Glue Data Catalog supporte les données partitionnées. Elles doivent être dans un même répertoire S3.
Points d’attention lors de l’utilisation de Glue Data Catalog :
Il est à noter que Glue Data Catalog est pour nous le meilleur service de l’écosystème Glue. Cependant il demande une attention particulière sur les points suivants.
- Pour supporter les données partitionnées, il est nécessaire (pour le cas de données stockées sur S3) de placer les différentes partitions, dans un même chemin (ou dossier) S3. Cela implique que même si le fichier source n’a qu’une seule partition, il doit être placé dans un dossier S3. Sinon, on risque de se retrouver avec le message “Zero record returned” lors de la query via Athena. Ce message trompeur tend à faire penser que la donnée ne contient aucune ligne. Mais la vraie raison se situe dans le fait que dans le catalogue, l’emplacement de la donnée pointe sur un fichier et pas un répertoire.
- Dans les paramètres de la table Glue, “SerDe serialization lib” (librairie utilisée pour la sérialisation/désérialisation) est un paramètre auquel il faut prêter attention. Un SerDe mal renseigné empêchera des outils de requêtage comme Athena de lire les données cataloguées dans Glue Data Catalog. Si les données ont été cataloguées via un crawler Glue, la librairie appropriée sera indiquée. Si le catalogage est fait via un code custom, il est important de s’assurer de renseigner la librairie qui convient au format de la donnée. Par exemple la librairie SerDe pour du .parquet est org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe.
- Le Data Catalog étant la source unique de vérité, il est nécessaire qu’il soit constamment synchronisé avec la donnée cataloguée. Tout changement de metadata de la donnée doit être immédiatement reporté dans le catalogue. Sinon les résultats renvoyés lors des requêtes Athena ne représenteront pas ce qui est réellement stocké. Une des solutions pour cela est d’utiliser un pipeline event-driven qui met à jour le catalogue chaque fois qu’une donnée est chargée dans S3.
- L’API Glue Data Catalog comporte un certain nombre de “soft limit” qui ne sont renseignées dans aucune documentation officielle. Il nous est parfois arrivé que nos actions Data Catalog soit “throttled” sans qu’on ne sache trop pourquoi, et ce de façon presque aléatoire. Le fait que ces limites ne soient pas renseignées dans les documentations nous empêchait de l’anticiper. Cependant, pour comprendre le problème et avoir des moyens de contournement, le support Premium d’AWS est d’une grande utilité.
Glue job
Une fois que nos données brutes étaient cataloguées et que nous avions une bonne connaissance de leur contenu et leur metadata, il nous a fallu les transformer et les harmoniser selon les standards voulus par le projet. Un des standards était de stocker toutes ces données au format .parquet afin d’optimiser le stockage et les temps de réponse lors des requêtes via Athena. Pour faire la transformation de .csv à .parquet, nous avons utilisé Glue Job. Il permet de créer des jobs Spark écrits soit en scala, soit en python.
Avantages de Glue Job:
- Glue Job est serverless. Il permet rapidement de créer des jobs Spark pour effectuer les transformations désirées dans notre pipeline. On n’a pas besoin de monter et configurer un cluster EMR pour cela.
- Les jobs peuvent être écrits soit en Scala, soit en Python, ce qui offre une certaine flexibilité de développement.
- Tout comme pour AWS Lambda, le code peut être écrit via la console Cloud9, ou uploadé sur S3. De plus, il peut même être généré lorsqu’il s’agit de transformations basiques (comme le “csv to parquet”)
Limitations de Glue Job:
Bien que Glue soit serverless et qu’on puisse facilement générer son code, il comporte un bon nombre de limitations qui se sont révélées handicapantes dans notre cas d’utilisation :
- Pour faire du Spark dans un Glue Job, on est obligé d’utiliser GlueContext et DynamicFrame qui sont des abstractions des classes SparkContext et DataFrame de Spark. Cependant les binaires de ces librairies ne sont pas disponibles sur maven ou pyPi, ce qui empêche de lancer ou tester localement son code Glue Job. Si l’on est un ayatollah du TDD (Test Driven Development), cela est inconcevable.
- Pour palier cela, AWS a mis à disposition le service Glue Dev Endpoint. Il suffit de créer un endpoint de développement, puis de le connecter à son IDE, afin de pouvoir développer en local et exécuter sur le endpoint son code. On peut aussi l’utiliser avec des notebooks Zeppelin. Bien que cela permette d’utiliser son IDE local pour développer des jobs Glue, on ne peut toujours pas faire du TDD, et il est à noter que les endpoints de développement Glue coûtent très chers.
- Chaque Glue Job a un cold start d’une dizaine de minutes. Cela dépend de ressources (DPU) demandées et de la disponibilité des ressources chez AWS. Nous n’avons jamais vu de documentation officielle là dessus, mais nous pensons que derrière chaque job Glue, se trouve un EMR géré par AWS. Dès que nous lançons un job Glue, AWS nous alloue une certaine capacité d’EMR. Si aucun EMR n’est disponible, il faut qu’AWS en provisionne pour exécuter notre job. Nous avons constaté que lorsque nous alignons plusieurs jobs Glue successifs, ce cold start diminue (3 à 5 minutes environ). Mais dès qu’on fait une dizaine de minutes sans exécuter de job Glue, on retombe dans des cold start de 10 minutes. Il faudrait donc lancer continuellement des jobs Glue pour ne pas avoir de cold start, ce qui est un peu à contre sens du serverless que l’on n’est sensé utiliser que lorsqu’on en a besoin. Ce cold start multiplié par le nombre de jobs à exécuter induit un temps considérable de retard dans les exécutions.
- Glue job étant serverless, on ne peut pas le configurer à sa guise comme on le ferait avec un cluster EMR. Pour des cas d’utilisation très pointus demandant du fine tuning, on se retrouve vite limité.
Conclusion
AWS Glue a différents composants dont les principaux pour un pipeline d’ingestion de données sont:
- Glue Crawler
- Glue Data Catalog
- Glue Job
Nous avons vu, à partir de notre expérience personnelle les avantages et les limitations de chacun d’eux. Ils présentent tous beaucoup d’avantages, en particulier lorsqu’on souhaite construire un pipeline totalement serverless dans un délai très court.
Pour des projets exploratoires, Glue et son écosystème (Glue Crawler, Glue Data Catalog, Glue Job) conviennent très bien. En effet, ils permettent de rapidement explorer la donnée, la transformer et la mettre à disposition, et ce, sans avoir à monter ni configurer de serveurs. Si l’on est novice en développement Spark, Glue Job nous génère le code pour des cas simples.
Cependant dès que l’on veut passer à l’échelle ou que notre projet a des exigences fortes en termes de temps de delivery de la donnée de bout en bout, notre expérience nous révèle qu’il vaut mieux éviter d’utiliser Glue Job. Ses “colds start”, sa non flexibilité en terme de “fine tuning” et son intégration complexe dans un environnement de développement risquent d’handicaper lourdement le projet. Glue Crawler et Glue Data Catalog quant eux s’adaptent toujours bien aux contraintes de passage à l’échelle et de “Time To Market”. Il faudrait passer sur AWS EMR pour les jobs ETL. Celui-ci est plus flexible et s’interface très bien avec Glue Data Catalog et Glue Crawler.
De notre point de vue, Glue Job n’est pas encore robuste et suffisamment developper-friendly pour être utilisé dans un environnement de production. Il a souvent été présenté comme un concurrent d’EMR, mais cela n’est pas du tout le cas.
Glue Data Catalog quant à lui, est de loin le meilleur composant d’AWS Glue. Il s’interface très bien avec beaucoup d’autres services AWS (Athena, EMR, Lake Formation), ce qui en fait un élément incontournable des pipelines d’ingestion.
Commentaires :
A lire également sur le sujet :




