
MLOps : Cas pratique d’un cycle de vie Machine Learning, de l’expérimentation à la production

Article écrit en collaboration avec Habib Ghislain Diop.
Construire des modèles est une tâche ardue, les mettre en production est plus difficile encore. Reproduire votre pipeline et vos résultats, ou permettre à d’autres Data Scientists de le faire est tout aussi complexe. Combien de fois avez-vous dû abandonner des travaux antérieurs parce qu’ils n’étaient pas correctement documentés ou trop difficiles à reproduire ? Nous verrons dans cet article comment le MLOps répond à cette problématique, et comment intégrer cette démarche à un cycle de vie complet de Machine Learning.
Gérer des modèles sur le long terme
La mise à l’échelle des modèles est souvent une tâche suffisamment importante pour que la gestion à long terme soit négligée. Quelles sont les implications pratiques de cette gestion à long terme ? Essentiellement, cela consiste à comparer les résultats des différentes versions des modèles ML avec les artefacts correspondants – code, dépendances, visualisations, données intermédiaires et plus – pour suivre ce qui se passe, pour redéployer, restaurer ou mettre à jour les modèles selon les besoins. Chacune de ces tâches nécessite des outils spécifiques, et ce sont ces changements qui font la complexité du cycle de vie ML par rapport à la gestion traditionnelle du cycle de vie de développement logiciel.
Le MLOps en bref
Le MLOps, qui apporte une réponse à cette problématique, constitue un ensemble de pratiques qui garantissent l’évolutivité, l’agilité et la gouvernance dans les pipelines de développement et de déploiement de modèles. Le MLOps donne également une fiabilité accrue au process de développement et de déploiement des modèles.
Ce nouveau paradigme se concentre sur quatre domaines clés liés à l’entraînement, l’optimisation et le déploiement de modèles :
- Reproductibilité
L’un des défis auxquels les data scientists sont souvent confrontés est de reproduire un modèle qu’ils ont entraîné il y a quelque temps. Cela nécessite une traçabilité du code, des paramètres du modèle, des métriques, de la version des données et de l’algorithme de ML, etc…
- Collaboratif
La collaboration au sein de l’équipe data est la clé du succès du projet ML, qui nécessite un espace de travail collaboratif où toutes les activités sont répertoriées et partagées entre l’équipe. Cela comprend des exécutions d’entraînement, des notebooks, des recherches d’hyperparamètres, des visualisations, des mesures statistiques, des ensembles de données, des références de code et un référentiel d’artefacts de modèle (model registry) etc.
- Scalabilité
Les data scientists doivent avoir accès à des ressources de calcul et de stockage à la demande afin de pouvoir itérer plus rapidement pendant la phase d’entraînement et tuning. Avec les bonnes pratiques MLOps, l’ensemble du processus est agnostique de l’infrastructure, scalable et minimise la complexité pour les data scientists.
- Continuité
Le CI / CD est devenu une pratique standard dans l’industrie du logiciel au fil des années. Toutes les étapes y compris la compilation du code, les tests, la vérification de la qualité et le déploiement etc. sont orchestrées automatiquement dans un pipeline de CI / CD. Ceci rend les développeurs plus productifs en économisant beaucoup de leur temps.
De la même manière, les projets ML bénéficient également de cette automatisation, dès l’entraînement jusqu’au déploiement de modèles en production. Au fur et à mesure que les données changent dans le temps, cela influence les performances des modèles, qui peuvent se dégrader. Ainsi, un pipeline ML automatique sera certainement très utile pour re-entraîner une nouvelle version du modèle et le déployer en production.
Nous allons maintenant voir comment créer un cycle de vie ML de bout en bout en utilisant des frameworks comme Spark, Delta et MLflow.
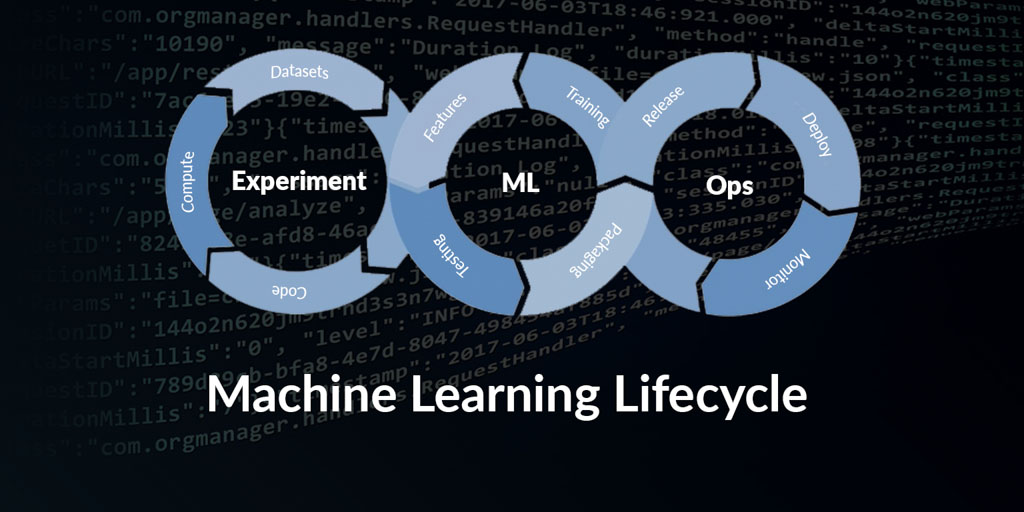
Préparation des données
La première étape de tout projet ML est l’acquisition des données. Nous pouvons utiliser des frameworks comme Spark et Delta pour accéder à nos données, les nettoyer et les transformer. Ces frameworks/librairies sont disponibles dans la plateforme Databricks mais aussi en format open source.
Spark est un moteur de calcul distribué et un choix defacto pour les projets data. Delta lake nous garantit les transactions ACID et la vérification de schéma (le type et la forme des données). Par conséquent, les données utilisées pour l’entraînement des modèles sont fiables, elles sont de bonne qualité avec le schéma souhaité.
Delta nous permet également de voyager dans le passé (time travel) pour accéder aux versions précédentes des données. Cette fonctionnalité est primordiale pour la reproductibilité des modèles.
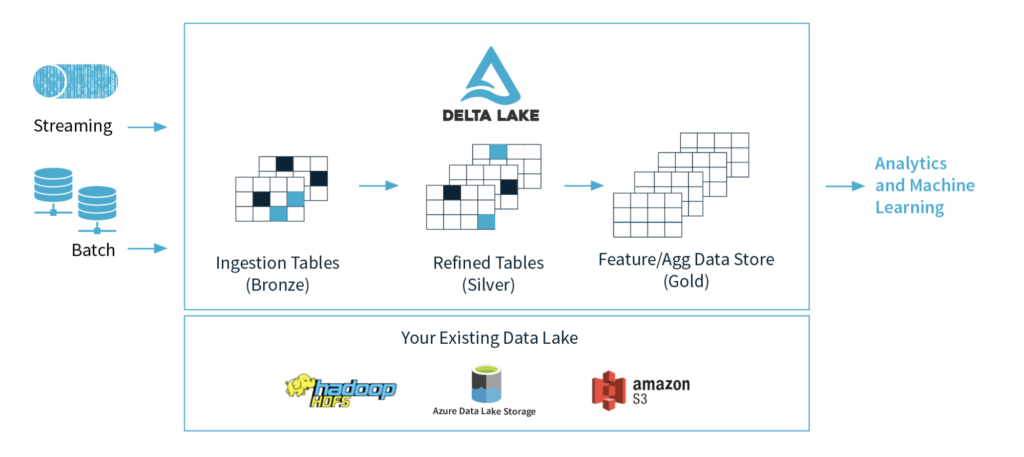
Dans cet article, nous allons prendre l’exemple d’un problème de classification des produits pour une entreprise d’e-commerce, qui doit classer les produits en différentes catégories pour améliorer l’expérience de recherche et de recommandation pour leurs clients finaux. La première étape consistera à lire et à transformer le dataset des produits.
datapath = "..."
bronze_products = spark.read.format("csv") \
.option("inferSchema", "true") \
.option("multiLine", "true") \
.option("escape", '"') \
.option("header", "true") \
.option("sep", ",") \
.load(datapath)
silver_products = bronze_products\
.withColumnRenamed("amazon_category_and_sub_category", "category") \
.withColumnRenamed("product_name", "name") \
.withColumnRenamed("uniq_id", "id") \
.withColumn("price", regexp_replace('price', '[^0-9-\.\,]+', '').cast(DoubleType())) \
.withColumn("price_10", col('price') / 10) \
.withColumn("number_available_in_stock", regexp_replace('number_available_in_stock', '[^0-9-\.\,]+', '').cast(IntegerType())) \
.withColumn("shop_id", (rand(0) * 5).cast(IntegerType())) \
.filter("category is not null and length(id) == 32 and description is not null") \
.sort(col("category").desc())Nous allons maintenant sauvegarder ce dataset transformé en format delta.
silver_delta_path = "..."
silver_products.write.format("delta").save(silver_delta_path) Nous avons aussi la possibilité de sauvegarder les données comme une table delta en s’appuyant sur du SQL.
CREATE TABLE products
USING DELTA
LOCATION '<siver_delta_path>'; Voici par exemple comment on peut retrouver une version des données antérieure (time travel) dans le but de reproduire un modèle.
DESCRIBE HISTORY products; 
SELECT * FROM products VERSION AS OF 0Hormis les features comme les transactions ACID, la vérification de schéma et le time travel, le format delta nous permet aussi d’effectuer les opérations des types update, delete et merge sur les tables delta. Avant l’invention du format delta ces opérations n’étaient pas si simples à implémenter dans un datalake.
Entraînement et tracking de modèle
L’exécution des modèles ML nécessite d’expérimenter, de construire, de régler et de tester en continu. Par conséquent, il est impératif de permettre aux équipes de Data Science de suivre tout ce qui se passe dans une exécution spécifique, ainsi que les résultats. Avec MLflow, les Data Scientists peuvent rapidement enregistrer des exécutions et suivre les paramètres et métriques du modèle, les résultats, le code et les données de chaque expérience, le tout de façon centralisée.
Avant d’entraîner notre modèle, on effectue une préparation de la donnée correspondant à la feature engineering. On utilise une feature de Scikit Learn Pipeline, qui permet d’appliquer de façon séquentielle une liste de transformation et un estimateur final. Cet estimateur est XGBoost qui va nous permettre d’effectuer notre classification des produits par catégorie.
def get_ml_pipeline(max_depth = 5, n_estimators = 70, use_idf = True, norm = 'l1', max_features = None):
return Pipeline([
('vect', CountVectorizer(stop_words='english', analyzer='word', strip_accents="ascii", max_features=max_features)),
('tfidf', TfidfTransformer(use_idf=use_idf, norm=norm)),
('classifier', XGBClassifier(max_depth=max_depth, n_estimators=n_estimators, objective='multi:softmax'))
])On peut donc lancer notre entraînement, où nous utiliserons MLflow pour tracer les métriques (notamment la métrique de performance de notre modèle ici le f1-score), les paramètres, la version de la donnée et les artifacts de notre modèle, et aussi le packager.
# Start mlflow run
with mlflow.start_run(run_name="Product Classification Experiment") as run:
num_trees = 250
max_trees_depth = 5
# Let's train our ML Pipeline:
pipeline = get_ml_pipeline(max_depth = max_trees_depth, n_estimators = num_trees, use_idf = True, norm = 'l1')
pipeline.fit(X_train, y_train)
predictions = pipeline.predict(X_test)
f1 = metrics.f1_score(y_test, predictions, average='micro')
# Logging parameters and model to MLFlow
mlflow.log_param("num_trees", num_trees)
mlflow.log_param("max_trees_depth", max_trees_depth)
mlflow.log_param("delta_version", delta_version)
mlflow.log_metric("f1", f1)
mlflow.sklearn.log_model(pipeline, "model")
run_info = run.info A la fin du job d’entraînement, on peut visualiser les expérimentations avec l’interface utilisateur de MLflow.

Déploiement de modèle
Pendant le processus d’entraînement des modèles, nous avons normalement plusieurs versions de modèles à différents stades ou environnements (dev ou sandbox et prod par exemple, etc.)
Par conséquent, nous avons besoin d’un hub central pour gérer le cycle de vie des modèles de façon collaborative. MLflow registry répond exactement à ce besoin.
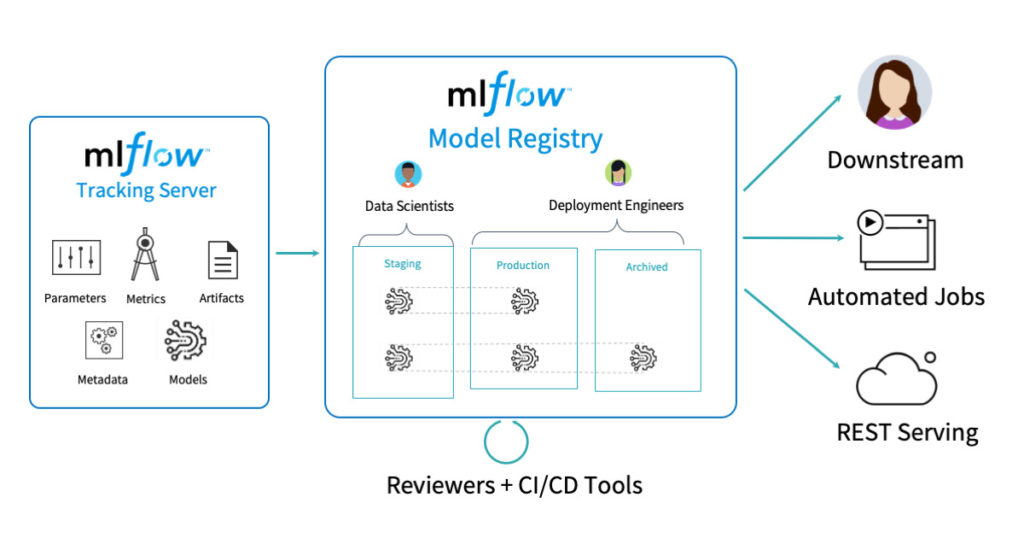
Voici un exemple d’une façon simple d’enregistrer notre modèle de classification des produits dans MLFlow registry, le passer au stade de la production et le récupérer ensuite depuis le registry :
model_name = "product-classification-model"
client = mlflow.tracking.MlflowClient()
# Create & register model in registry
client.create_registered_model(model_name)
result = client.create_model_version(
name=model_name,
source=f"{run_info.artifact_uri}/model",
run_id=run_info.run_uuid
)
# Transition model stage to production
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Production"
)
# Extract model from registry which is in production stage
production_model_uri = f"models:/{model_name}/production" MLflow registry propose également une interface utilisateur sur laquelle toutes les actions effectuées ci-dessus avec l’API peuvent également être réalisées. Nous allons maintenant vérifier sur l’interface utilisateur que notre modèle a été bien enregistré dans le registry et qu’il a été également transféré au stade de la production.
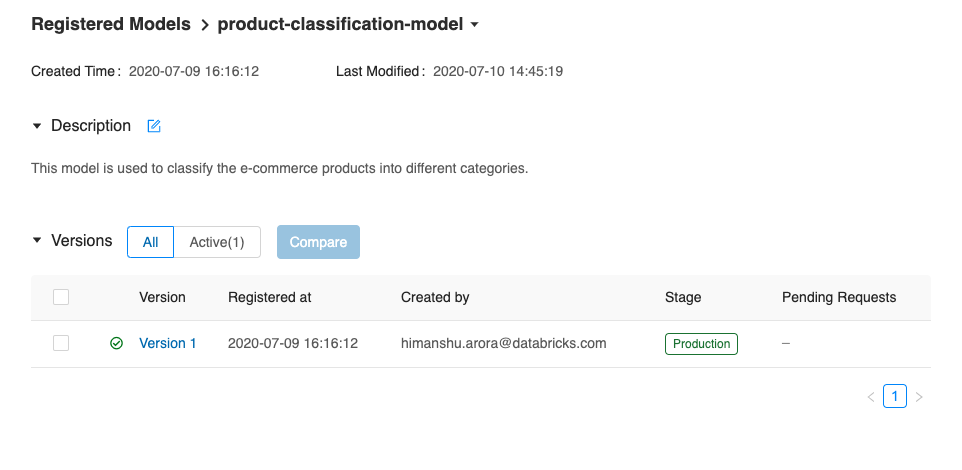
Il existe une multitude de possibilités pour déployer un modèle en production à l’aide de MLflow :
- déploiement dans un job spark (streaming ou batch)
- déploiement dans un conteneur docker
- déploiement en tant qu’API REST
- déploiement sur Amazon Sagemaker, etc.
Dans cet article nous avons choisi de déployer le modèle de classification des produits sur Amazon Sagemaker d’un côté et de l’autre dans un job spark streaming. Veuillez consulter la section sur le monitoring pour voir le déploiement dans spark streaming. Concentrons-nous sur le déploiement sur Sagemaker ici.
Pendant le déploiement, MLflow utilisera un conteneur Docker spécial avec les ressources nécessaires pour charger et servir le modèle (conteneur standard pour tous les modèles). Vous pouvez vous-même créer et pousser ce conteneur sur ECR (amazon container registry) avec une seule ligne de commande.
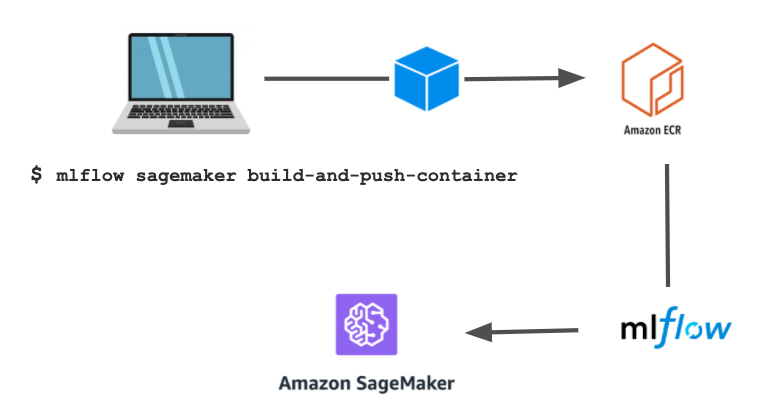
Et voici maintenant comment nous pouvons déployer le modèle sur Sagemaker avec MLflow et invoquer l’endpoint pour générer les prédictions
import mlflow.sagemaker as mfs
app_name = "ProductClassification" # Sagemaker endpoint
mfs.deploy(app_name=app_name, model_uri=production_model_uri, region_name="<aws-region>", mode="create", image_url="<ecr-image-url>")import json
# Query sagemaker endpoint
def query_endpoint(app_name, inputs):
client = boto3.session.Session().client("sagemaker-runtime", "<aws-region>")
response = client.invoke_endpoint(
EndpointName=app_name,
Body=inputs,
ContentType='application/json',
)
preds = response['Body'].read().decode("ascii")
preds = json.loads(preds)
return preds
prediction = query_endpoint(app_name="ProductClassification", inputs=<query_input>)Monitoring de modèle (model drift)
Une dérive du modèle peut se produire en cas de modification des données (features) ou des dépendances cibles. Par exemple le concept même de ce que vous essayez de prédire change, les données évoluent en raison de la saisonnalité ou de la tendance ou il y a un changement dans le pipeline de données en amont qui prépare les features etc.
Cela est préjudiciable pour la société d’e-commerce dans notre exemple : un impact négatif sur le système de recherche et de recommandation de produits se traduira par une perte de clients.
Nous avons donc besoin d’une boucle de feedback depuis un système de surveillance afin de rafraîchir les modèles au fil du temps.
Voici un exemple expliquant comment nous pouvons détecter la dérive du modèle et agir en conséquence. Dans cet exemple, nous lirons les produits et effectuons la prédiction en temps réel grâce à Spark streaming.
Nous calculons le taux de prédiction correct en analysant la table réelle (silver delta table) et la table de prédiction (gold delta table) sur la fenêtre d’un jour. Ce taux sert d’indicateur de performance clé pour alerter lorsqu’il commence à décroître en dessous d’un seuil prédéfini par le business.
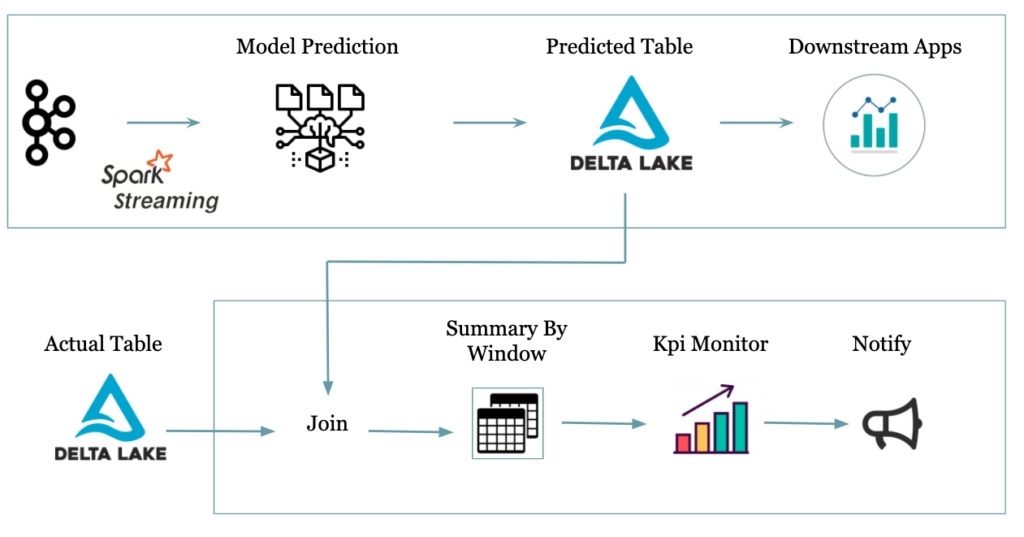
Voir l’extrait de code ci-dessous pour cet exemple
# Start by loading the model from registry
model = mlflow.pyfunc.load_model(production_model_uri)
# Define spark UDF for prediction
@pandas_udf('int')
def predict_category_udf(descriptions):
return pd.Series(model.predict(descriptions))
# Register spark UDF
spark.udf.register("predict_category", predict_category_udf)
# Stream for kafka
product_stream = spark.readStream.format("kafka") ....
# Prediction in real time and store as delta table
gold_delta_path = "..."
product_stream \
.withColumn("predicted_category", predict_category("description")) \ # Calling the UDF to predict
.writeStream \
.format("delta") \
.outputMode("append") \
.option("checkpointLocation", "/tmp/gold_products_chechpoint_") \
.start(gold_delta_path)
# Function to compute model accuracy KPI
def track_model_quality(real, predicted):
# Join actual and predicted dataframes
quality_compare = predicted.join(real, "id")
# Create a column indicating if the predicted label is accurate
quality_compare = quality_compare.withColumn(
'accurate_prediction',
when((col('category') == col('predicted_category')), 1)\
.otherwise(0)
)
# Summarize accurate labels over a time window to trend percent of accurate predictions
accurate_prediction_summary = (quality_compare.groupBy(window(col('timestamp'), '1 day').alias('window'), col('accurate_prediction'))
.count()
.withColumn('window_day', expr('to_date(window.start)'))
.withColumn('total', sum(col('count')).over(Window.partitionBy('window_day')))
.withColumn('ratio', col('count')*100 / col('total'))
.select('window_day','accurate_prediction', 'count', 'total', 'ratio')
.withColumn('accurate_prediction', when(col('accurate_prediction') == 1, 'Accurate').otherwise('Inaccurate'))
.orderBy('window_day')
)
return accurate_prediction_summary
# Call the model tracking function
kpi_df = track_model_quality(silver_products.select("id", "category"), gold_products.select("id", "predicted_category", "timestamp"))
Notez qu’il faut prévoir un certain délai pour que les points de données provenant de Kafka atteignent la table réelle (silver table) avec leurs valeurs de catégorie réelles en fonction du processus métier. Ce délai doit donc être pris en compte dans le calcul du KPI ci-dessus.
Conclusion
Dans cet article, nous avons vu comment exploiter Delta pour préparer un lac de données fiable et de qualité, ce qui est la toute première étape du cycle de vie ML.
MLflow était la deuxième pièce du jeu qui nous a permis d’entraîner et tracer facilement le modèle et ses paramètres. MLflow a également facilité la tâche du déploiement du modèle sur Amazon Sagemaker ou dans un job Spark. Enfin, nous avons utilisé Spark pour surveiller la dérive du modèle dans la dernière section de cet article. Cela résume le déroulement d’un cycle de vie ML complet.
Pour les aspects de collaboration, scalabilité et intégration continue, il est également possible de s’appuyer sur une plateforme comme Databricks. Cette plateforme fournit des notebooks collaboratifs qui peuvent facilement faire partie du workflow de production planifié automatiquement, et gère également la scalabilité automatique.
Commentaires :
A lire également sur le sujet :




