
AWS Summit 2019 : Comment enrichir son datalake
Le 4 avril 2019, le Palais des Congrès a accueilli l’AWS Summit auquel j’ai participé sous les couleurs de D2SI. Le summit est un lieu de rencontre et de partage avec des nombreuses conférences traitant un large panel de sujets (AI/ML, BDD, migration, serverless, IOT, securité, analytics…). J’ai pu assister à un total de 5 conférences lors de ce summit et j’ai particulièrement apprécié celle présentée par Amadou Merico, Solutions architect AWS, qui avait pour thème « Comment enrichir son datalake ».
Pour ceux qui n’ont pas eu la chance d’y participer, voici un condensé de ce qui nous a été transmis !
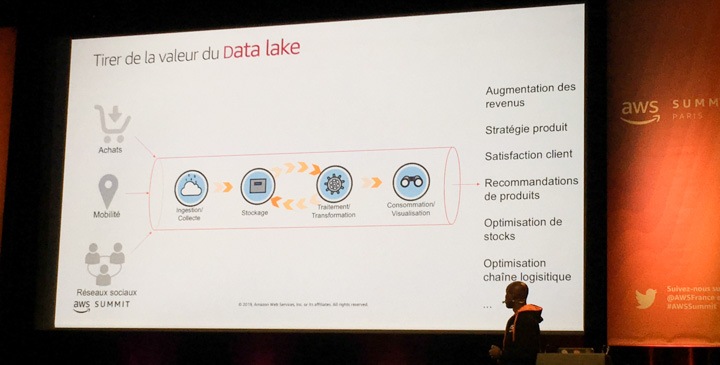
Par essence aucun datalake n’est semblable à un autre puisque leur architecture dépend du contexte et des besoins auxquels ils répondent. Ils partagent cependant des points communs :
- Les données y sont centralisées
- Ils facilitent l’ingestion et la consommation des données
- Ils permettent de séparer le stockage et les ressources de calcul
- Le stockage y est durable et le coût maîtrisé
Un datalake est en réalité la combinaison de plusieurs services qui s’agrègent pour ingérer et mettre à disposition de la donnée. Le deuxième point est crucial car un datalake doit toujours avoir comme objectif de créer de la valeur à partir des données (recommandation de produits, optimisation des stocks etc…).
Pour mettre en place un datalake le plus efficacement possible il faut définir au mieux ses besoins. Pour ça il faut se poser 5 questions incontournables :
- A quelle fréquence la donnée sera sollicitée ? Doit-on la protéger par du chiffrement ? Au final, comment stocker la donnée ?
- Comment la donnée sera collectée ? (batch ou temps réel)
- Comment rendre visible la donnée stockée ?
- Comment nettoyer la donnée ? (doublons, fausses valeurs, donnée incomplète etc..)
- Comment orchestrer la gouvernance de la donnée et les règles de sécurité ?
Dans la pratique il existe des services d’AWS qui permettent de répondre à ces besoins.
Par exemple, AWS recommande comme bonne pratique de stocker les données sur S3 car ce service est scalable, hautement disponible, le chiffrement est possible et plusieurs systèmes partagent les mêmes données.
Pour de la collecte de donnée en temps réel, Amazon Kinesis Data Firehose est tout indiqué puisque ce service permet de charger de manière fiable des données dans S3, Redshift ou encore Elasticsearch Service.
AWS Athena permet de lancer des requêtes SQL pour analyser et visualiser les données contenues dans S3.
Amadou, le speaker de la conférence, propose AWS Glue comme outil de data preparation car c’est un service serverless qui permet d’extraire, de transformer et de charger des données. Il existe cependant une multitude d’autres outils comme Spark ou Talend, et la data preparation peut également se faire au travers d’une Lambda (attention aux coûts engendrés par Lambda dans les cas de très gros volumes).
La conférence s’est clôturée par un rappel de quelques bonnes pratiques à garder en tête lorsque l’on cherche à créer un datalake sur AWS :
- Avoir un pipeline de données aussi flexible que possible pour permettre une évolution au fil du temps.
- Bien penser à toutes les contraintes techniques de l’environnement de travail et baser ses choix en fonction de celles-ci.
- Toujours privilégier les services managés d’AWS.
- Chiffrer les données au repos et en transit si possible.
Commentaires :
A lire également sur le sujet :




