
Big Data Paris 2018 : architectures pour les données rapides, Datalake AWS, Cloud Datawarehouse…

Le 12 et 13 mars 2018, le Palais des Congrès de Paris a accueilli le salon Big Data Paris 2018. C’est un événement phare de la Big Data en France qui a rassemblé près de 250 marques, 100 conférenciers et a attiré plus de 15200 participants. Quelles sont les architectures spécialisées pour les données rapides ? Quels sont les possibilités offertes par le Cloud en matière de Datalake ou de Datawarehouse ? Pour répondre à ces questions, nous reviendrons dans cet article sur les ateliers organisés par Lightbend, Mind7, AWS et Snowflake.
Quelles architectures pour les données rapides ?
Ce sujet a été présenté conjointement par un consultant de Mind7 et Trevor Burton-McCreadie, Solutions Architect chez Lightbend. Pour rappel, Lightbend propose une plateforme open-source destinée à la mise en place d’applications réactives. Elle a été créée par Martin Odersky, créateur de Scala, Jonas Bonér, créateur de Akka, et Paul Phillips.
Les présentateurs ont commencé par une brève introduction du concept de Fast Data, qui concerne principalement le traitement des données en mouvement (rapide), alors que la Big Data fait souvent allusion à des traitement en batch sur des terabytes ou petabytes de données au repos.
Les approches du Big Data se reposant sur des Datawarehouse traditionnels posent souvent des problèmes de latence, ce qui n’est pas adapté aux nouveaux cas d’utilisation de la donnée. Parmi ces cas d’usages, on peut citer les systèmes de recommandation online, la personnalisation de services selon le pattern d’utilisation de l’utilisateur, la détection de fraude, etc. Cette émergence de nouveaux cas d’usage a engendré un changement radical de paradigme. Aujourd’hui, il est primordial de prendre en compte tout le flux (Stream) des événements entrants au lieu de ne garder que le résultat des ces événements. Dans un contexte d’application e-commerce par exemple, on va garder des informations sur les étapes par lesquelles le client est passé avant d’annuler sa commande, ce qui permet de détecter d’éventuels problèmes avec la procédure d’achat et améliorer la plateforme e-commerce.
La Fast Data repose sur les systèmes réactifs qui donnent beaucoup d’importance à la résilience et à la scalabilité et sont message-driven. La mise en place d’un tel système passe par plusieurs étapes importantes :
- Le choix de la technologie d’ingestion des données qui dépend des contraintes du projet en termes de durabilité, sémantiques de delivery (exactly-once, at-least-once, at-most-once), la prise en charge de plusieurs producteurs/consommateurs de messages…
- Le choix du moteur de traitement :
- Spark avec son modèle d’exécution en mini-batch et la possibilité d’exprimer ses pipelines en SQL
- Flink avec sa faible latence et sa compatibilité avec Apache BEAM
- Akka Streams qui permet de définir des pipelines en graphe complexes tout en étant léger et efficace
- Et Kafka Streams qui s’intègre nativement avec Kafka et qui est idéal pour des ETLs en streaming
- Le choix de la manière avec laquelle les microservices seront développés et déployés
- Le choix des outils de monitoring adéquats au cas d’utilisation en main
Face à ces choix, on peut opter pour des plateformes propriétaires qui ne sont pas forcément adaptables au client ou choisir une plateforme reposant sur des technologies open-source et qui est beaucoup plus personnalisable, comme Lightbend.
Trevor a conclu l’atelier par une présentation de la plateforme Lightbend dont les briques principales sont les suivantes :
- DC/OS comme système d’exploitation distribué open-source basé sur Apache Mesos. Il offre les services essentiels pour la vie d’un système réactif (Application discovery, déploiement de conteneurs …)
- Kafka comme broker de messages
- Spark, Flink, Akka ou Kafka Streams comme moteur de traitement en streaming
- OpsClarity pour le monitoring
Le Datalake par AWS
Cette présentation de Xavier Delacour, Solutions Architect chez AWS, visait à éclaircir l’approche d’AWS en ce qui concerne la mise en place d’un Datalake sur la plateforme et comment il s’intègre avec les autres briques de l’écosystème AWS.
Un Datalake est un dépôt de stockage contenant une grande quantité de données brutes sous un format natif, y compris des données structurées, semi structurées et non structurées. La structure des données n’est pas définie tant que les données ne sont pas utilisées. Quels sont les avantages d’une approche Datalake ? Souvent dans le cas de clusters Hadoop ou de Datawarehouse traditionnels, il y a de fortes chances qu’ils soient silotés. Cela est le plus souvent dû au fait que chaque business unit a ses propres données, ce qui rend difficile le dialogue entre les différents systèmes de l’entreprise. Un autre problème avec les clusters Hadoop traditionnels est la corrélation totale entre les ressources de stockage et les ressources de computing. En effet, pour ajouter de la puissance de calcul, il faut également ajouter du stockage même si ce n’est pas vraiment nécessaire. L’approche Datalake permet également de dissocier les capacités de scaling en termes de puissance de calcul et stockage.
Un des objectifs majeurs des Datalakes est de permettre le stockage de très grands volumes de données hétérogènes; l’approche Datalake permet de stocker et d’analyser nos données dans le même endroit, contrairement aux approches traditionnelles. Cette source unique de données constitue une vue globale et uniforme de toutes nos données. Le Datalake permet également d’ingérer des données avec des débits beaucoup plus importants puisque cette approche privilégie le traitement des données a posteriori. Le fait d’avoir stocké les données brutes donne également la flexibilité d’appliquer des schémas différents à nos données au moment de la la lecture (Schema on read).
AWS recommande comme bonne pratique du Datalake de séparer la partie Compute de la partie Stockage. Chez AWS, le point central du Datalake est S3. Toutes les contraintes de durabilité, de redondance et de performance sont donc déléguées à ce service de stockage. S3 peut être utilisé directement avec d’autres technologies grâce à des connecteurs spécifiques par exemple et s’intègre parfaitement avec les autres services de la plateforme (EMR, DynamoDB, Redshift …) tout en proposant une faible latence et des débits importants allant jusqu’à 25 Gbit/s.
Un Datalake sur AWS ressemble donc à ça :
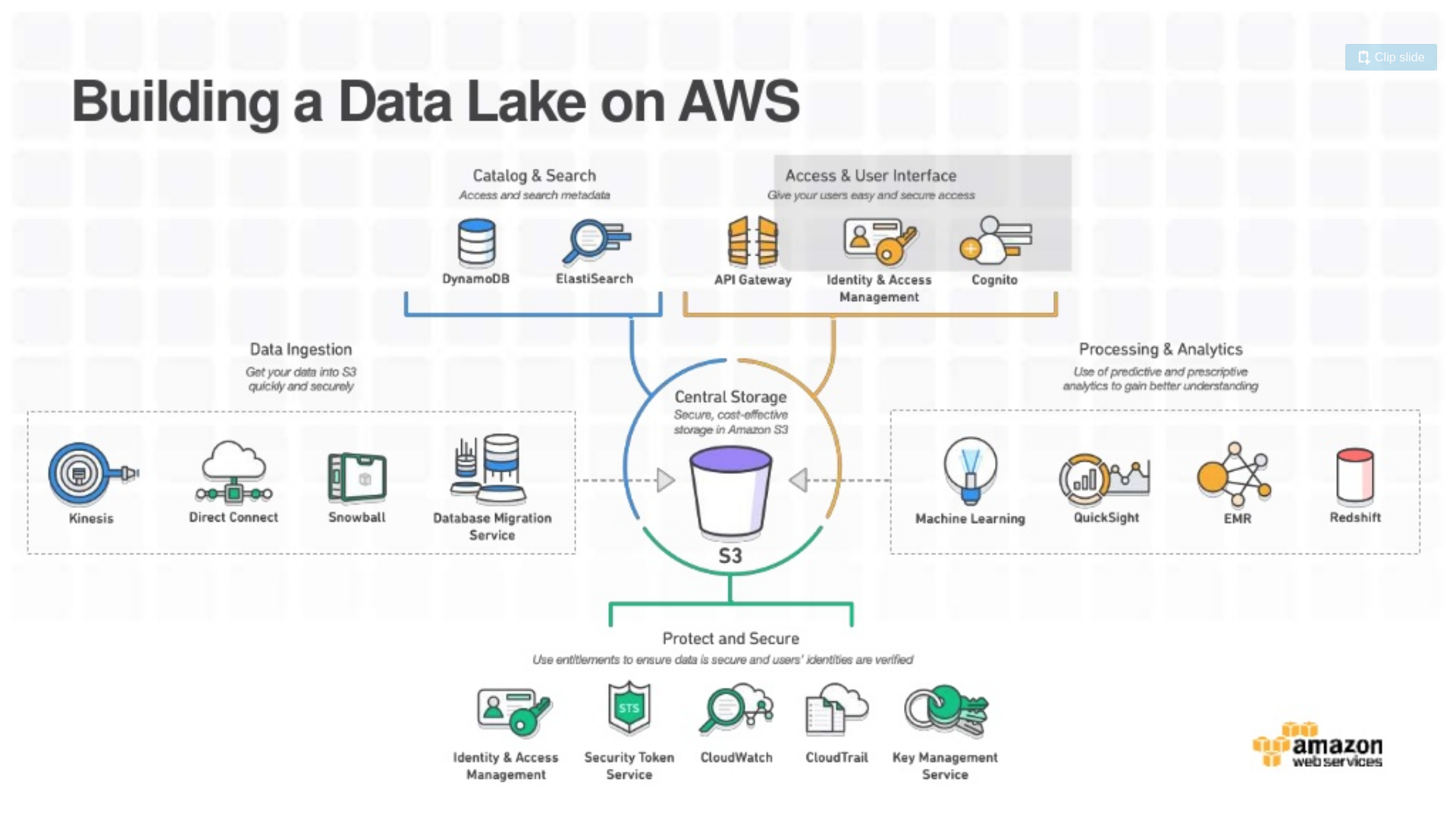
Si on prend l’exemple de Kinesis Firehose, ce service permet d’ingérer des Teraoctets de données par seconde et de faire des archives régulières sur S3, ce qui le rend parfait pour les cas d’utilisation de streaming et d’archivage à haute vélocité. Un autre exemple est Data Migration Service qui rend possible le transfert de base de données entières se trouvant on-premise vers S3.
La sécurité est un volet très important de notre Datalake. IAM nous permet par exemple de définir quels utilisateurs pourront faire quoi sur notre Datalake et KMS qui nous permet de chiffrer nos données sans overhead en termes de performances ou de coûts.
Différentes typologies nous permettent d’utiliser la puissance du Datalake:
- Processing en temps réel : on utilise Kinesis pour ingérer les données au lieu de S3
- Processing en batch :
- EMR (Hadoop, Spark … managés). Toute la partie HDFS des clusters sera stockée sur S3
- Athena: permet de requêter ses données directement sur S3. C’est un service serverless
- Redshift: service de datawarehousing sur S3. Souvent utilisé comme data mart spécialisé
- Amazon Glue: Service d’ETL managé
- Intelligence artificielle :
- Amazon Lex : qui est un service AWS de création d’interfaces conversationnelles au sein des applications, utilisant la voix et le texte
- Sagemaker : espace managé pour la génération de modèles de machine learning. Il met à disposition tout un ensemble de modèles de machine learning open source qu’on pourra entraîner avec nos propres données
Snowflake, Cloud Datawarehouse
Cette présentation a été faite par Nicolas Baret, directeur des avant-ventes EMEA chez Snowflake. Snowflake est un Datawarehouse développé spécifiquement pour le cloud. Il est basé sur une architecture multi-cluster avec données partagées qui sépare le traitement du stockage. Cela permet d’éliminer la non flexibilité et la complexité des Datawarehouses traditionnels. Snowflake est fourni comme service managé, permettant donc de diminuer radicalement l’effort de gestion et de maintenance du Datawarehouse et de bénéficier d’un paiement à l’usage.
La première question qui vient à l’esprit est : que doit attendre d’un tel Datawarehouse et comment est il différent du Datawarehouse traditionnel? Un cloud DW a une bonne capacité de scaling à plusieurs niveaux. En effet, il doit être capable d’héberger des quantités massives de données en croissance continue et de satisfaire un grand nombre de requêtes analytiques concurrentes. De plus, il permet une gestion de schémas de données flexible en permettant l’analyse de données avec du schema-on-read. Ceci nous garantit la compatibilité de nos analyses avec des données dont la structure a évolué dans le temps.
Un autre aspect important d’un cloud DW est la sécurité. Ce dernier doit assurer un accès granulaire aux données, un chiffrement continu des données stockées et une protection contre la suppression involontaire des données. Et enfin, un cloud DW doit être résilient pour éviter la perte d’analyses.
Snowflake assure ces qualités et propose des fonctionnalités supplémentaires intéressantes :
- Historique des résultats des requêtes : le résultat des requêtes des utilisateurs est mis en cache pour une durée de 24h et ce quelque soit la taille de ce résultat. Ceci permet aux utilisateurs d’accéder aux résultats des requêtes antérieures sans relancer les relancer et donc économiser du temps et de la puissance de calcul.
- UNDROP : Cette commande permet de rétablir la dernière version d’une table supprimée pour une période de rétention de 24h par défaut. Cette commande est moins complexe et plus rapide qu’une restauration de backup.
- Zero copy clone : permet la création de copies du Datawarehouse actuel sans répliquer les données. Il est aussi possible de créer des copies à des instants passés. Cette fonctionnalité permet de créer des environnements de tests et de développement sans aucun overhead et de rendre les données accessibles à différents groupes d’utilisateurs.
- Compatibilité entre JSON et SQL : Snowflake propose une version étendue de SQL qui permet d’accéder à des données non structurées de type JSON, Avro, Orc …
Conclusion
Les deux journées du salon Big Data Paris étaient riches en informations, et notamment pour développer une vue d’ensemble sur les manières novatrices de gérer les données aujourd’hui. La diversité des domaines d’activité des intervenants montre bien que la donnée est au cœur de tous les métiers. À l’issue du salon, on constate également la place occupée par le Cloud actuellement dans le monde du Big Data, et la vitesse à laquelle les entreprises transitent vers le Cloud. En effet, les services managés sont de plus en plus adoptés par les entreprises, parce que ces services permettent de transférer les efforts opérationnels à un Cloud provider qui assume la responsabilité permanente de la gestion des couches logicielles, la sauvegarde des données, etc. Dès lors, l’entreprise peut se focaliser sur son activité métier et sur l’utilisation des données pour apporter de la valeur à ses clients. Ceci dit, il ne faut pas ignorer l’évolution rapide des outils open-source qui donnent plus de flexibilité mais qui nécessitent toujours un effort opérationnel important.
Commentaires :
A lire également sur le sujet :




