
Google Cloud Summit Paris : retour sur la journée

Google Maps, GMail, Chrome, Android… fort de millions d’utilisateurs quotidiens, Google entend bien capitaliser sur ce succès pour porter son offre de Cloud public et ses services associés. Durant la keynote d’ouverture du Google Cloud Summit Paris, Sébastien Marotte, VP EMEA de Google a volontiers reconnu la position de challenger de Google Cloud Platform, et le travail de précurseur, ainsi que l’avance prise par AWS.
Mais la bataille du Cloud public ne fait que démarrer : selon Sébastien Marotte, aujourd’hui seulement 5% des workload d’entreprise sont sur le Cloud, et la croissance du marché va exploser dans les 3 à 5 prochaines années. Comment Google compte-il se différencier sur ce marché? Le vice-président de Google a comparé le marché du Cloud à celui des smarphones pour rappeler qu’en 2007, Nokia et Blackberry étaient les seuls acteurs du marché, suggérant qu’en dix ans il pouvait se passer beaucoup de choses. Et Google dispose de certains atouts dans le domaine de l’IA, du machine learning, des conteneurs et de l’orchestration pour se positionner autour de la transformation digitale et de l’innovation. Pour terminer, Sébastien Marotte a cité Larry Page pour qui la différence entre le succès et l’échec tient à la capacité à être tourné vers le futur. Et le futur selon Google, c’est la donnée.
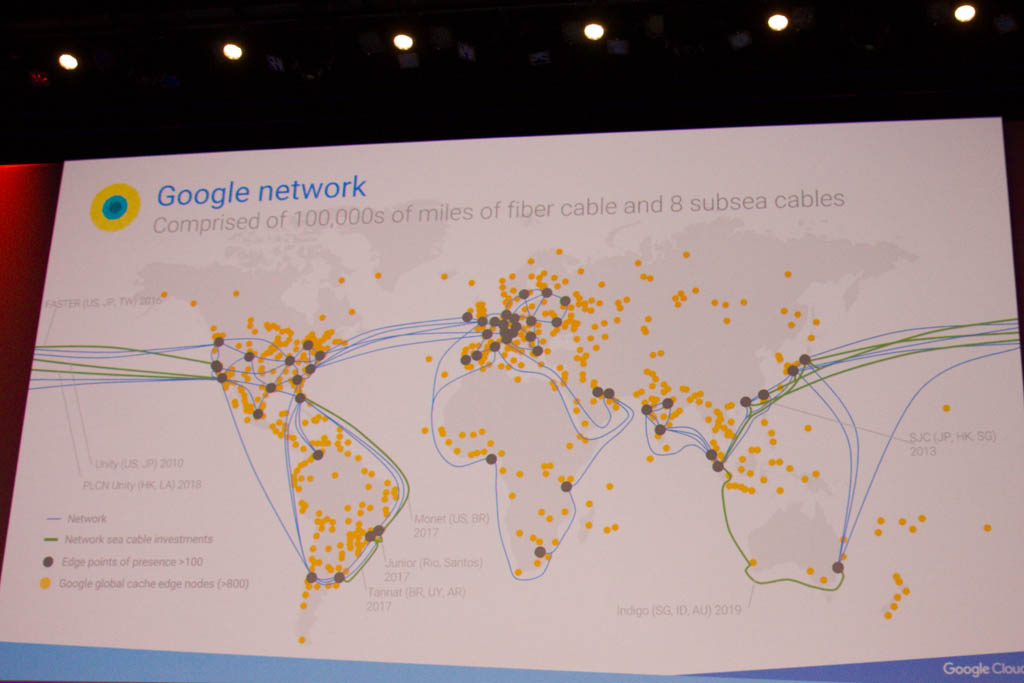
La sécurité, un des drivers du Cloud public
C’est ensuite Ulku Rowe, directrice technique et financière du bureau du CTO, qui a continué la keynote, organisée en 5 parties autour des principaux drivers la décision d’aller sur le Cloud : la fiabilité, la sécurité, le support, la performance et l’optimisation des coûts, avant de détailler les atouts de Google sur chacun de ces points. Pour rappel, le réseau de Google est soutenu par 100 000 miles de fibre optique et 8 câbles sous-marins. Parmi les innovations présentées en matière de sécurité, notons aussi le processeur Titan, spécifiquement conçu pour assurer la sécurité des serveurs. Francesco Campoy a également la fait la démo de l’API « Data Loss Prevention », qui permet de supprimer automatiquement certaines informations personnelles partagées sur Slack ou sur une page Web. Photos, documents d’identité, carte de crédit… l’API fait même la différence entre un numéro de carte de crédit fonctionnel et un faux numéro).
Machine learning et outils collaboratifs Google
David Thacker, VP Product Management, a ensuite présenté les dernières innovations de machine learning intégrées dans la suite d’outils collaboratifs de Google (Drive, Sheets, Docs, etc.). Smart Reply permet par exemple de générer des formules complexes dans Google Sheets grâce à une demande formulée très simplement, Gmail propose maintenant des réponses automatiques basées sur l’analyse du mail, et Drive propose une fonction prédictive pour mettre en avant les fichiers les plus susceptibles d’être utilisés.

La data, la data, la data…
On en vient ensuite à l’un des thèmes récurrents de la journée, la donnée. D’ici 2025 nous générerons un volume de 163 zettabytes par an, et Google propose une offre très complète autour de la donnée : Big Query comme Data warehouse dans le Cloud, Dataproc (Hadoop/Spark) pour le traitement, Pub/Sub, Big Query et Dataflow pour l’analyse en temps réel. Google peut aussi se prévaloir d’une certaine avance dans le domaine du machine learning, avec une offre proposant d’utiliser les modèles déjà existants de machine learning créés par Google, ou d’utiliser ses outils pour construire et entraîner ses propres IA. Google propose des modèles dans les domaines suivants : langage naturel, traduction, reconnaissance vidéo ou encore un outil de ML dédié à la recherche d’emploi. Pour conclure le sujet, rien de mieux qu’une démo : sur une vidéo de quelques minutes, l’IA de Google a identifié chacun des éléments présents dans la vidéo. Un militaire, une femme, des enfants, du football… tous les tags créés sont cliquables pour visionner chacun de ces éléments à la demande. Une innovation qui a de beaux jours devant elle au vu du nombre de vidéos uploadées quotidiennement sur YouTube, la plateforme vidéo de Google.
Des clients data driven : Dailymotion et La Redoute
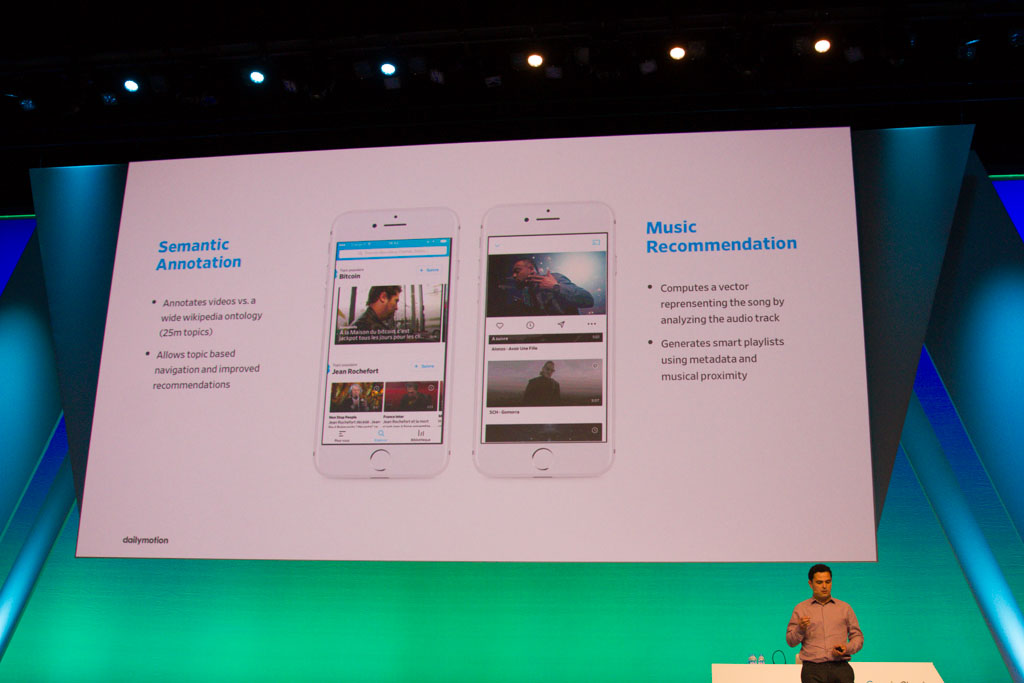
C’est d’ailleurs Dailymotion, concurrent français de YouTube, qui est le premier client à venir témoigner durant cette keynote. 3 milliards de vidéos vues par mois, 300 millions de visiteurs uniques, 150 millions de vidéos dans le catalogue… Thomas Achache, responsable Data chez Dailymotion, a présenté la migration vers un pipeline en temps réel basé sur Pub/Sub, DataFlow et Big Query, réalisée en seulement deux semaines. Le nouveau pipeline, beaucoup plus réactif, permet par exemple de détecter 10 fois plus de fraudes à la publicité. Dailymotion s’appuie également sur le machine learning pour analyser sémantiquement le contenu des vidéos ou proposer des recommandations musicales et générer des smart playlists en fonction des metadata et de la proximité musicale.
Autre success story à la française pour Google, La Redoute : François Nguyen, Chief Data Officer, a présenté le cheminement vers la data d’une entreprise de 180 ans qui a eu plusieurs vies. La Redoute a eu un premier site Internet en 1996, mais cela n’a pas fait de la société de VPC une « internet company » pour autant. Aujourd’hui, La Redoute réalise plus de 90% de son chiffre d’affaires en ligne, et revendique 9,7 millions de visiteurs uniques mensuels (à mettre en perspective avec Amazon qui en compte 18 millions). Pour passer d’un usage descriptif de la donnée (comprendre ce qui s’est passé) à un usage prédictif, puis prescriptif (optimiser la décision), La Redoute a choisi de s’appuyer sur une plateforme Cloud, et a fait le choix d’un partenaire « data driven ». L’architecture mise en place par La Redoute s’appuie sur Big Query, Cloud Storage, Dataproc, Speech API, Vision API, Pub/Sub et Dataflow. Parmi les premiers chantiers, un wikipédia de la data, et l’ajout d’une fonction de recherche vocale.
Outils et insights du Big Data
Durant la track qui suivait la keynote, William Vambenepe, Group Product Manager, est revenu plus en détail sur les outils proposés par Google pour traiter la data. Pour illustrer comment la convergence du Big Data et du Cloud oblige à repenser la stratégie de données, William Vambenepe a pris l’exemple de Google Streetview. Il y a 10, Streetview n’était qu’une fonctionnalité de Google maps, aujourd’hui le service inclut beaucoup plus de données que la photo. De fait nous devons réévaluer la valeur de la donnée, en considérant 4 types de données :
- Les données utilisées
- Les données collectées sans être analysées
- Les données non collectées car jugées non utilisables
- Les données issues de tiers : clients, partenaires, données publiques…

Jusque là, un projet Big Data était un projet IT impliquant de nombreuses problématiques d’infrastructure, et le Cloud permet justement de se concentrer sur la valeur métier et s’affranchir des contraintes d’infrastructure. A l’instar des cas clients présentés lors de la keynote, l’accent est ici mis sur le modèle complètement Serverless des services proposés par Google autour de la donnée. Dans ce modèle, les contraintes matérielles et les responsabilités sont portées par Google, facilitant ainsi l’utilisation et permettant un paiement à l’usage, comme AWS Lambda. Pub/Sub n’a par exemple pas réinventé la roue du publish/suscribe, mais propose un modèle s’adaptant dynamiquement à la charge: il suffit de créer un topic, d’ajouter les permissions de post et souscription. S’il n’y a pas de messages, ça ne coûte rien, si demain il y a un million de messages par seconde, le système s’adapte. Dataflow s’appuie également sur ce modèle, et permet aux entreprises d’évoluer progressivement de l’approche batch, actuellement dominante sur le marché, vers le traitement en stream. William Vambenepe a également présenté Cloud DataPrep, outil graphique permettant de composer des pipelines de préparation de données et d’explorer visuellement la donnée. Bien sûr la présentation ne serait pas complète sans présenter à nouveau Big Query, service de datawarehouse serverless assurant haute disponibilité, durabilité et scalabilité jusqu’à un petaoctet.
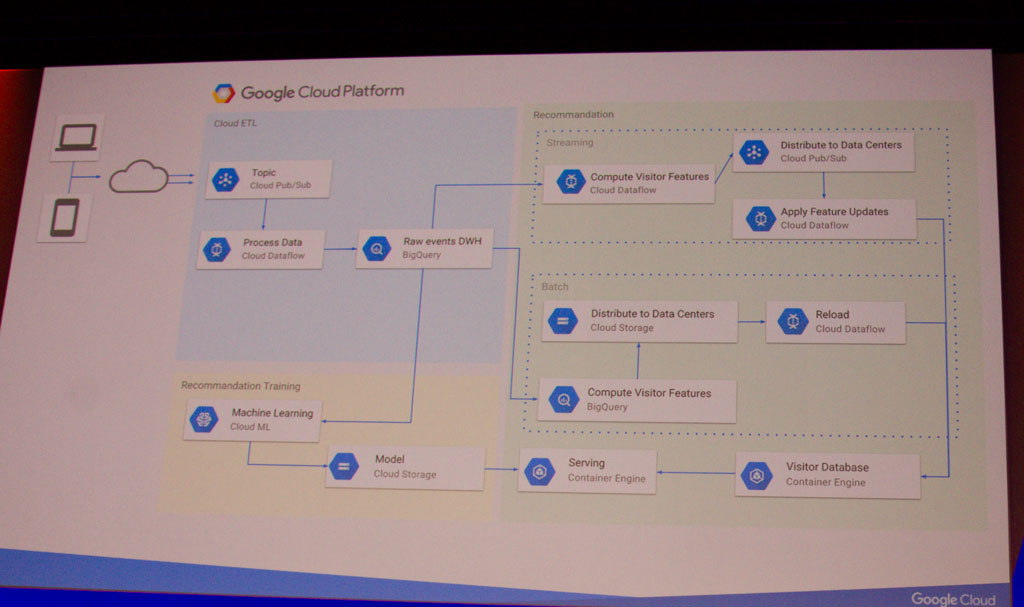
Pour terminer cette track, Philippe Girolami a présenté en détail la migration de Dailymotion. En 2016, Dailymotion utilisait une architecture batch basée sur Scala et Hadoop, où les logs étaient ingérés toutes les heures. La nouvelle architecture mise en place s’appuie sur les services suivants :
- Pub/Sub : connecteur entre systèmes
- Dataflow : job de processing stream et batch
- GCS : espace d’export global multi-régions
- BigQuery : source pour la reprise sur erreur
- GKE : héberge l’API interne de recommandation
- Cloud ML : construit les modèles de reconnaissance
- Stackdriver : monitoring

D2SI recrute des profils Cloud/DevOps ! Si vous souhaitez rejoindre l’aventure D2SI, envoyez-nous votre candidature à l’adresse : recrutement@revolve.team
Commentaires :
A lire également sur le sujet :






