
Itinéraire de consultant : découvrez les coulisses d’un projet Big Data

Quel est le quotidien de nos consultants en mission ? Quels sont les challenges techniques qu’ils doivent relever et quelles solutions sont apportées ? Derrière une mise en production réussie, un déploiement ou un Proof of Concept, il y a des consultants, une équipe, des technologies et beaucoup d’expertise et d’intelligence collective ! Cette série d’articles vise à vous dévoiler l’envers du décor, à travers le témoignage de nos consultants.

Kewei
Développeur Java, Python et C++, Kewei se passionne pour la data, depuis la création des pipelines de données jusqu’au déploiements des algorithmes de machine learning . Pour son premier projet au sein de la cellule Big Data, Kewei a eu l’opportunité d’expérimenter de nouvelles technologies dans l’écosystème Scala dans l’objectif de développer un micro service REST.
Peux-tu décrire le projet Big Data sur lequel tu travailles ?
Il s’agit d’un projet de Data Engineering, dont l’objectif est de développer un micro service REST pour injecter des données de monitoring (statuts CPU, mémoire, tous types de métriques) en provenance de 2000 machines. Nous sommes quatre à intervenir sur ce projet, dont deux consultants de la cellule Data Engineering D2SI. Le projet vient tout juste de passer en production.
Quel est ton travail sur ce projet ?
Je suis développeur Big Data, et je travaille essentiellement avec Scala, qui est un langage de programmation fonctionnelle. Nous avons choisi Scala pour ses performances, et parce que c’est un langage réactif, et pour pouvoir utiliser le toolkit Akka, qu’il est préférable d’utiliser en Scala. Akka est très fréquemment utilisé dans le développement d’applications et microservices nécessitant une haute performance.
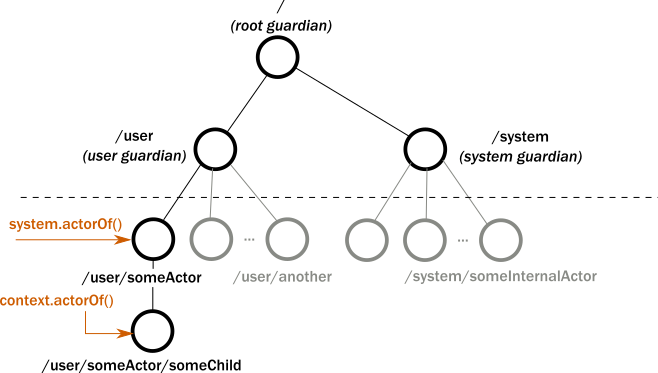
Akka actors system
Comment fonctionne le micro service ?
Après validation et certaines modifications (le format d’origine des données est conservé), tous les messages sont envoyés à Kafka, un message broker. L’avantage de Kafka est de pouvoir stocker les messages en attendant qu’ils soient consommés par une application, ou par plusieurs applications simultanément sans que cela interfère. Kafka présente aussi l’avantage d’être scalable.
Qu’as-tu appris durant ce projet ?
Quand je suis arrivé dans la cellule Big Data je n’avais pu mettre en pratique aucun des outils que j’utilise couramment aujourd’hui. J’ai commencé par passer deux certifications Scala sur la plateforme coursera qui propose des cours en ligne réalisés par le créateur du langage Scala. Ces deux formations m’ont pris environ deux mois, ça m’a permis de découvrir les bases, mais ce n’est pas suffisant pour coder avec l’objectif d’avoir une qualité de production. Les cours en ligne sont très théoriques et axés sur la syntaxe du langage, ne permettent pas de véritablement comprendre les mécanismes du framework. .J’ai commencé par changer des composants, faire des tests unitaires, ajouter de petites fonctionnalités… puis les cas d’usage rencontrés durant ce projet m’ont permis de développer de réelles compétences.
Comment et pourquoi Akka a été choisi ?
Le choix d’Akka est issu d’une réflexion au sein de l’équipe Big Data. Nous avons mené un double développement pour comparer Akka et Nifi. Il en en ressorti que certains fonctionnalités de Nifi n’étaient pas très stables, Akka offrait plus de contrôle et de fiabilité. Et puis la combinaison avec Scala assurait un service de haute performance. Enfin, Akka étant open source, les ressources, articles et tutoriels sont nombreux et cela a aussi influencé notre choix.

Quels sont les prochains challenges ?
Actuellement je découvre Gatling, un outil de test permettant de faire de façon automatique les tests fonctionnels et les tests de charge. Gatling est aussi développé en Scala, et envoie de nombreuses requêtes au serveur. Comme Scala et Akka, Gatling est issu de la programmation réactive. Traditionnellement, s’il y a dix requêtes, on utilise dix threads… et c’est très coûteux en mémoire, donc sur les gros volumes traités par les équipes de data engineers, ça devient vite un problème. On ne peut pas avoir 5000 threads sur un même process. D’où l’avantage de la programmation réactive, qui ne gère pas une requête par thread, mais qui les gère comme des messages, regroupés et gérés par un acteur. Cela permet d’utiliser beaucoup moins de threads pour gérer autant de requêtes. Aujourd’hui la programmation réactive est de plus en plus utilisée par les serveurs web.
Qu’est ce qui te plaît dans la cellule Data Engineering ?
L’ouverture d’esprit est très importante pour moi, j’apprécie d’être dans un environnement où on peut régulièrement tester de nouvelles technologies, notamment open source, et apprendre à les mettre en pratique. Par exemple aujourd’hui nous réfléchissons à la possibilité d’utiliser Flink, une technologie de stream processing, pour consommer les services de Kafka. Ces choix sont fait au niveau de l’équipe, nous en discutons ensemble et nous choisissons ce qui a le plus de sens pour le projet. Pour le dire autrement, il n’y a pas de manager qui nous impose d’utiliser une vieille technologie ! Par contre, quand nous avons commencé ce projet en particulier, il n’y avait pas vraiment de culture devops : pas de code review systématique, pas de test unitaires ou fonctionnels dans le projet, pas de chaîne CI. Mais nous avons pu convaincre le management de la nécessité d’avoir un devops dans l’équipe pour gérer la chaîne CI. Maintenant, nous travaillons avec Jenkins, Gitlab, Confluence, Jira.

Nos projets vous intéressent ? Discutons-en !
Envoyez un petit mot à Olivia : olivia.blanchon@revolve.team
Chez D2SI, nous avons toujours exploré les nouvelles technos et méthodologies d’automatisation. Rejoignez nous et soyez au coeur de cet éco-système avec D2SI !
Commentaires :
A lire également sur le sujet :






