Ooso, une librairie Java pour les traitements MapReduce en Serverless

Basés sur des algorithmes parallélisables et scalables, les traitements Big Data sont implémentés avec des outils qui tournent sur des systèmes distribués. Les technologies comme Hadoop ou Spark sont les standards pour ce type de traitements. Certes, ces frameworks sont matures, performants et soutenus par une communauté immense, mais la mise en place de l’infrastructure que ces outils nécessitent est complexe et n’est pas toujours possible. L’idée derrière la librairie Java Ooso est de profiter de la grande parallélisation et de la scalabilité du Serverless pour faire ces traitements Big Data, et ceci sans avoir à gérer de serveur. Mais comment ?
Objectifs de Ooso
L’objectif principal d’Ooso est de proposer une manière simple de faire des traitements MapReduce en se basant sur les services AWS Lambda et Amazon S3 pour traiter de grands volumes de données dans des durées et coûts raisonnables. De plus, la librairie doit prendre en charge la logique de distribution des jobs. Le but est que l’utilisateur ne se concentre que sur la partie métier du code comme on le ferait avec Hadoop ou Spark.
Types de traitement
Ooso permet de répondre à trois problématiques classiques du Big Data :
- Requêtes Ad Hoc : ces requêtes permettent d’interroger ses données, comme on le ferait avec SQL sur une base de données. Un exemple simple serait de calculer le nombre de transactions par catégorie de produits à partir d’un log de transactions d’un supermarché.
- Nettoyage des données : le nettoyage des données est l’opération de détection et de correction (ou suppression) d’erreurs présentes sur les données.
- Enrichissement des données: l’enrichissement des données est le processus d’ajout d’informations à nos données actuelles. Souvent, les nouvelles informations proviennent de sources externes (fichiers, bases de données, etc..).

Fonctionnement et architecture de la librairie Ooso
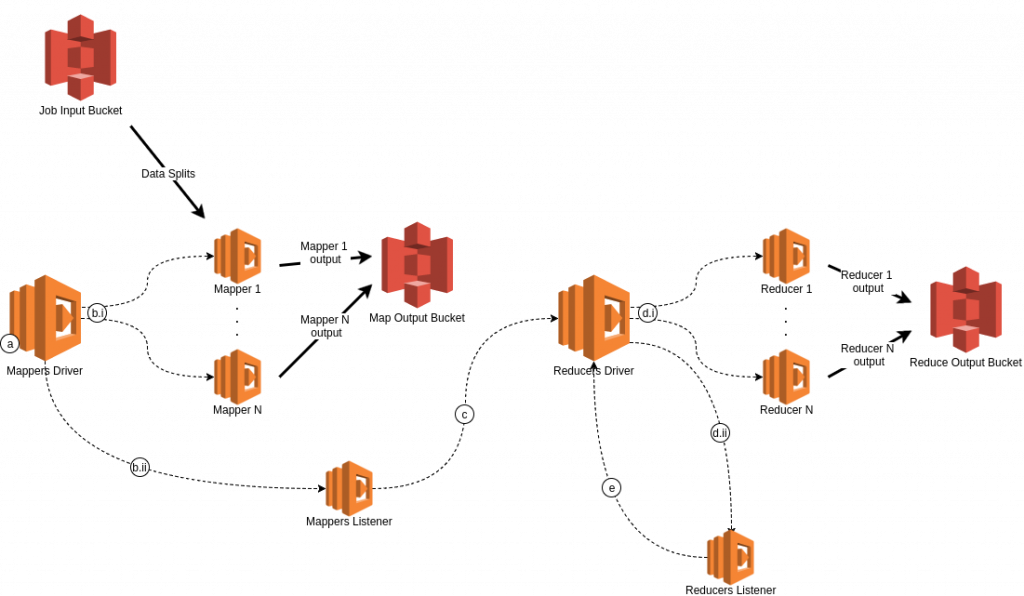
L’architecture de Ooso se compose principalement de fonctions Lambda qui se coordonnent automatiquement entre elles pour mener un job MapReduce de bout en bout.
Chaque phase (Map ou Reduce) se compose d’un Driver, un Listener et des Workers (Mappers et Reducers) :
- Les drivers ont pour but d’assigner des fichiers aux workers, et lancer les listeners.
- Les workers (Mappers ou Reducers) sont responsables de chercher les fichiers à traiter et mettre leurs résultats sur une bucket intermédiaire
- Les listeners vérifient périodiquement la fin de la phase en cours (Map ou Reduce)
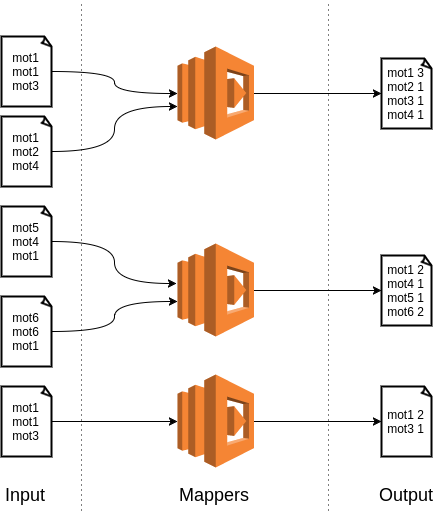
Si, par exemple, le but du job est de calculer le nombre d’occurrences de mots d’un dataset, on peut représenter la phase map par le diagramme suivant :
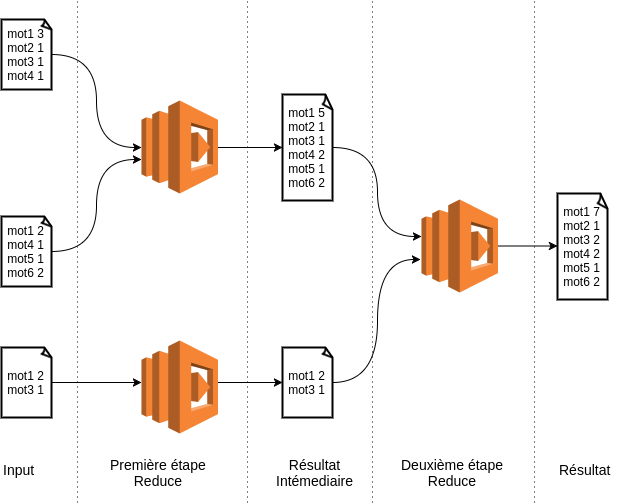
La phase Reduce est plus ou moins similaire à la phase Map, sauf que cette fois-ci on aura besoin d’une vague de reducers avant d’obtenir le résultat final, voir exemple ci-dessous :
Quid des performances et des coûts ?
Les tests ont été faits en utilisant un dataset qui contient l’historique des trajets de taxis à la ville de New York. Le dataset contient ~200 GB de données formatées en CSV. Deux tests ont été faits:
- Requête Ad Hoc : Le but de cette requête est de répondre à la question suivante: quels sont les trajets qui ont les même caractéristiques (Nombre de passagers, distance du trajet et année du trajet) ? C’est une requête qui nécessite des groupements et des agrégations de données, elle a donc besoin d’une bonne capacité de calcul.
- Transformation des données : plus spécifiquement, l’objectif de ce workload est d’enrichir les données actuelles avec des informations complémentaires qui proviennent d’une source externe.
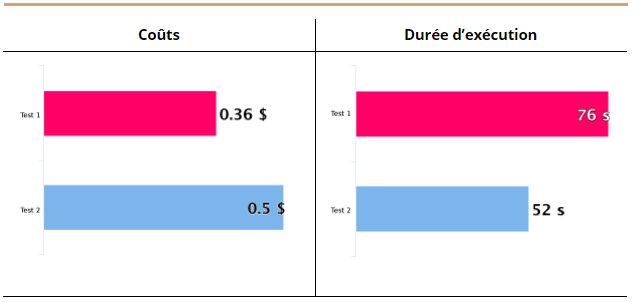
Le bilan des tests en termes de durée d’exécution et de coûts est représenté par les diagrammes ci-dessous. Il est à noter que le calcul des coûts est approximatif, et est basé sur le nombre d’invocations des Lambda et leur durée moyenne ainsi que le nombre de requêtes S3. Le calcul des coûts Lambda et S3 a été respectivement fait à l’aide des deux sites: serverlesscalc.com et calculator.s3.amazonaws.com.
Cas d’usages et limitations
Même si Ooso fonctionne bien pour ces différents workloads Big Data, il est plutôt recommandé pour des transformations de données que pour des requêtes Ad Hoc.
Il existe plusieurs outils pour requêter des données stockées sur HDFS ou S3 directement en SQL. Citons par exemple Apache Hive ou bien les outils basés sur Dremel tels que Apache Presto ou Apache Drill. Il s’avère plus facile et pratique de requêter ses données en SQL car c’est un langage déclaratif et surtout nous sommes nombreux à avoir l’habitude de l’utiliser.
En revanche Ooso nous semble pertinent pour des traitements de transformation de données dans certains cas :
- Aucun cluster Hadoop n’est à votre disposition. Une solution serait d’utiliser des services managés (AWS EMR ou Google Cloud Dataproc) pour créer un cluster éphémère, mais cela sera plus lent : le temps de création du cluster est de l’ordre de 10 minutes pour EMR, et 90 secondes pour Dataproc.
- Vous avez un cluster qui ne dispose pas de suffisamment de ressources pour un traitement donné. Vous pouvez donc utiliser Ooso au lieu de scaler votre cluster.
Enfin, votre exploration de Ooso continue sur le dépôt GitHub de la librairie à cette adresse. Nous vous invitons vivement à tester Ooso, ajouter des issues si vous rencontrez des problèmes ou bien même contribuer au développement de la librairie. Pour découvrir plus en détail ce projet, nous vous proposons un article plus approfondi : Ooso Serverless Mapreduce.
Commentaires :
A lire également sur le sujet :