Applications Serverless : Comment monitorer les fonctions AWS Lambda?

Que se passe-t-il quand on fait tourner du Serverless sur de larges infrastructures et avec de forts enjeux ? Dans cet article nous aborderons la question du monitoring des fonctions Lambda : comment vérifier qu’une plateforme Serverless fonctionne correctement ?
Si la question du monitoring ne se pose pas dans un Proof of Concept, lors du passage en production d’un projet utilisant AWS Lamba, il est important de comprendre comment les fonctions se comportent. Aujourd’hui, il n’y a pas vraiment d’équivalent à New Relic ou Datadog. AWS recommande officiellement d’utiliser Cloudwatch, mais est-ce vraiment adapté à la complexité d’une application qui utilise de nombreuses fonctions ? Ci-dessous, vous pouvez voir un graphique retraçant le nombre d’invocations/mn et leur durée moyenne. Avec seulement une quinzaine de fonctions, le graphique n’est pas simple à interpréter. Imaginez alors sur des applications plus complexes, avec un plus grand nombre de fonctions.
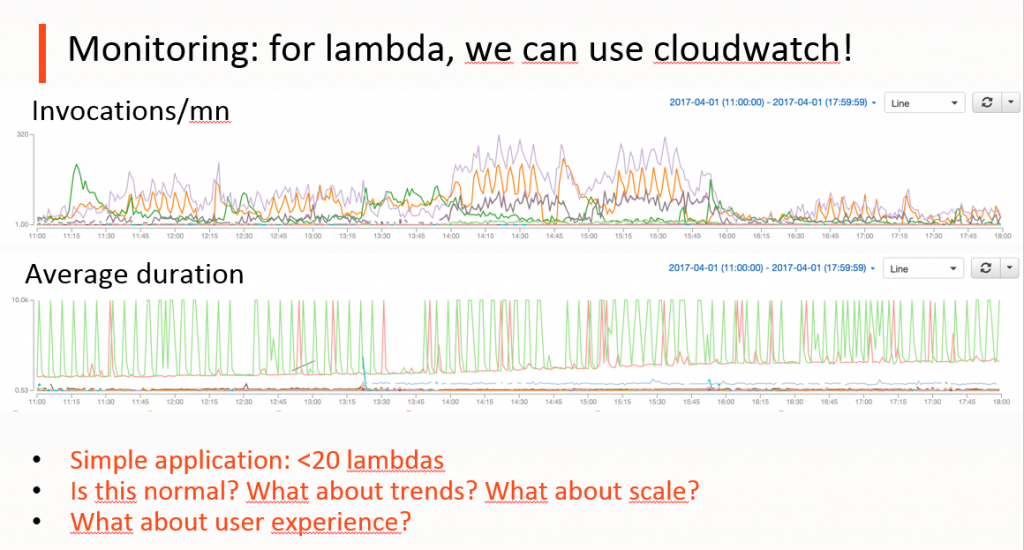
La seconde partie du graphique concerne la durée d’exécution des Lambdas : c’est un point à surveiller, car il y a des enjeux de performance et de coûts (les Lambdas sont facturées au temps d’exécution). On a donc tout intérêt à ce qu’elles s’exécutent rapidement.
Monitoring de la durée d’exécution des Lambdas
Ici on peut donc constater que la plupart des Lambdas s’exécutent vite, entre 200 et 300 ms, alors que d’autres durent 10 secondes. Est-ce normal ? Une autre Lambda semble évoluer par pics, de plus en plus longs. Dans le cas de cette application, ces comportements ont une explication : les traitements sont complexes, il est donc normal qu’ils prennent du temps. Quand à la lambda dont la durée augmente avec le temps (en rouge), elle a plus d’éléments à processer au fil du temps, et donc le comportement est normal. Néanmoins cet exemple pose la problématique du monitoring : comment monitorer des applications complexes avec un grand nombre de fonctions ? Ici nous ne disposons que d’une vue granulaire, qui ne permet pas de comprendre comment l’application se comporte globalement. Par exemple, qu’en est il de la perception globale des utilisateurs dont les requêtes peuvent nécessiter l’exécution de plusieurs Lambdas ?
Monitoring des erreurs Lambdas
Autre point à monitorer, les erreurs. Quelles sont les erreurs remontées par Cloudwatch ? Ce qui rend compliqué le monitoring des erreurs Lambda est qu’en plus des erreurs applicatives, il faut faire face à de nouveaux types d’erreur. Des erreurs liées à l’exécution, comme par exemple une Lambda mal dimensionnée, ou dont la durée d’exécution dépasse 5mn… Il faut également prendre en compte le fait que par défaut, une Lambda en erreur sera relancée deux fois, et donc, dans le lot d’erreurs remontées, toutes ne sont pas des erreurs uniques.
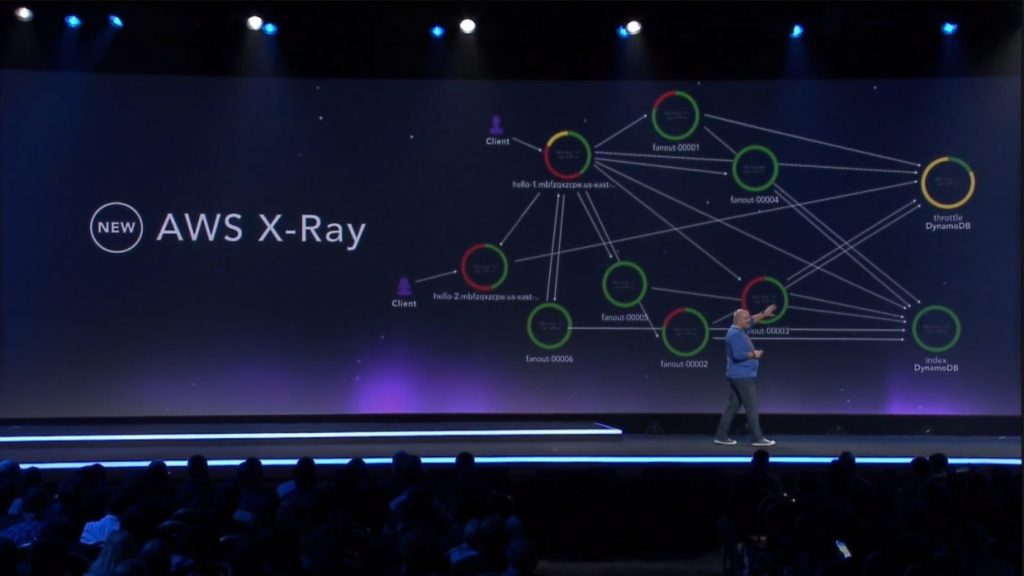
AWS X-Ray est disponible en version preview depuis Avril 2017
Dans l’exemple ci-dessus, quelle est l’origine des erreurs ? Si on trouve bien un log group par fonction Lambda, les très nombreux log streams peuvent s’avérer fastidieux à naviguer. Cloudwatch est donc efficace pour capturer les logs, mais il faut lui ajouter une autre solution pour les analyser; on recommandera également de prendre le temps de configurer Cloudwatch pour mieux exploiter ces données. Enfin pour la question des problèmes de performance, il n’existe aujourd’hui pas d’outil de type APM tout prêt. AWS X-Ray pourra répondre à ce besoin de tracing, mais cette fonction n’existe qu’en version preview, depuis le 19 avril dernier. L’éco-système autour de Serverless et Lambda est encore vraiment très jeune.
Les applications basées sur les événements posent de nouveaux challenges. Prenons l’exemple d’une fonction réagissant à une réception de fichier dans S3, et lançant un traitement qui aboutit à une nouvelle écriture dans S3. Si la réécriture se fait au même endroit, alors la fonction se déclenche à nouveau ! C’est typiquement le genre de problème dont on s’aperçoit en vérifiant la facture de ses Lambdas. Autre cas d’usage fréquemment rencontré, la consommation de flux en provenance d’un moteur de streaming comme Kinesis. Si la Lambda crashe, le message est représenté, et la Lambda est relancée, ainsi de suite à l’infini… Pour éviter d’avoir une Lambda bloquée sur le processing d’un événement, il faut donc logger l’erreur dans l’application sans générer d’erreur.

Gérer la latence du réseau
Autre challenge à gérer avec les Lambdas : la latence. Une Lambda peut être très rapide dans son exécution, mais quand un traitement est un ensemble de Lambdas séquencées, on introduit plus de latence à cause du réseau. Il faut prendre également en compte que le temps de facturation minimum d’une Lambda est de 100 ms, et que donc dimensionner des Lambdas en dessous de cette limite n’est pas intéressant. Enfin, il faut noter que la première exécution d’une Lambda est toujours plus longue. Il est donc important de surveiller le temps d’exécution des Lambdas et de mesurer les temps cumulés qui reflètent la perception globale de l’application.
Pour conclure, il faut retenir que l’éco-système autour des architectures Serverless est encore en cours de construction. Les outils sont rares, et ceux qui existent n’ont pas encore la maturité des solutions utilisées dans les architectures traditionnelles. Dans le cas d’AWS Lambda, la principale solution de monitoring est celle qui est intégrée à AWS, et elle est encore relativement limitée. Aujourd’hui, les outils de monitoring de référence ne sont pas encore prêts pour les architectures Serverless, mais cela ne saurait tarder. AWS propose aussi de nouvelles solutions avec X-Ray qui semble très prometteur. De nouveaux outils devraient apparaitre dans les prochains moins pour répondre à cette problématique, il faut donc rester en veille active pour les identifier et les évaluer. En attendant, il faut savoir que pour porter un projet Serverless en production aujourd’hui, il est encore nécessaire d’instrumenter « manuellement » ses applications.
Prochain rendez-vous Serverless : Serverlessconf Paris les 14 et 15 février 2018 :

Commentaires :
A lire également sur le sujet :