5 conseils pour réussir votre transformation DevOps

Savez-vous faire du DevOps à la mode, à la mode ? La mode n’est pas toujours à la nouveauté ! Si le terme DevOps a vu le jour dans les années 2000, ce n’est que courant 2014 que le mouvement a réellement pris de l’ampleur. Aujourd’hui, de plus en plus d’initiatives se créent autour du sujet (meetup et conférences) et bon nombre d’entreprises se lancent dans cette transformation à la fois technologique et organisationnelle. Le DevOps est partout et vient jusqu’à s’immiscer dans les intitulés de poste.
Si comme Woody, l’adoption de la culture DevOps au sein de votre organisation vous interroge et peut-être même vous effraye, vous trouverez dans cet article, je l’espère, quelques réponses sur les bonnes comme les mauvaises pratiques et la réalité du terrain.

L’année dernière, j’ai intégré une équipe composée de Devs (organisés suivant la méthode Agile) et d’Ops, avec pour objectif le lancement d’une nouvelle plateforme web chez un grand industriel français. J’ai alors découvert les enjeux du DevOps et je me suis confrontée aux difficultés de sa mise en place. De cette expérience, j’ai retenu 5 points essentiels à la réussite d’un tel projet.
1 – Pas de DevOps sans automatisation
Le DevOps a été pensé pour réduire le “time-to-market”, c’est-à-dire diminuer le temps de livraison des applications et des services informatiques, et donc d’accroître sa compétitivité sur le marché.
Pour s’inscrire dans cette dynamique, notre équipe avait pour but de réaliser au moins une mise en production par jour. En d’autres termes, nous devions être capable de dérouler chaque jour le cycle de vie complet d’une application : planification, code, test, release, déploiement, opération et supervision. C’est bien sûr ici qu’entrent en jeu l’automatisation et la chasse aux actions manuelles chronophages, rébarbatives et qui sont autant de sources d’erreur et de retards dans les déploiements.
Pour relever ce challenge, nous avons fait les choix techniques suivants :
- Hébergement de la plateforme web dans le Cloud AWS, afin de bénéficier de la scalabilité et tout particulièrement de l’automatisation de la plateforme grâce aux nombreuses APIs. On parle d’infrastructure programmable ou d’Infrastructure as Code.
- Architecture Blue-Green afin de déployer en production sans downtime et d’opérer un roll-back en quelques secondes si nécessaire.
- Architecture applicative distribuée en micro-services pour faciliter les déploiements. En effet, chaque micro-service étant une application à part entière possédant son propre code source et sa propre infrastructure (serveurs et base de donnée), peut être déployé indépendamment des autres.
- 3 environnements :
- L’UAT pour la validation fonctionnelle par les product owners. Il s’agit d’une seule machine virtuelle faisant tourner toutes les briques de l’application dans des containers Docker.
- La pre-prod pour la validation technique, c’est-à-dire s’assurer que le code va correctement tourner sur une infrastructure telle qu’elle sera en production. Cette fois, chaque composant tourne sur ses propres machines virtuelles et non plus dans des containers.
- La production, environnement iso à la pre-prod à l’exception d’un composant additionnel : Cloudfront, service de Content Delivery Network pour améliorer la performance du site et l’expérience utilisateur.
- Automatisation des tests et des déploiements du code dans les différents environnements par les outils suivants:
- Terraform qui propose une couche d’abstraction supplémentaire aux APIs du cloud. Il permet de gérer tous types de ressources AWS (machines virtuelles, bases de données, alertes de monitoring, comptes utilisateur, etc…) via de simples fichiers de configuration.
- Packer qui permet la création d’images de machine AWS. Pour limiter les phénomènes de dérive dans le temps, nous travaillons sur des images immuables, c’est à dire que nous générons des images de machines qui ne sont plus modifiées (pas de patch OS par exemple) et qui sont les mêmes en preprod et en prod.
- Docker qui offre une rapidité de déploiement en un temps record (création d’image et déploiement en seulement 2 à 3 minutes).
- Travis qui fait tourner les tests unitaires à chaque nouveau commit et qui déclenche les scripts de déploiement.
- Github pour le versioning du code aussi bien applicatif que lié à l’infrastructure.
Le schéma ci-dessous décrit notre workflow global de déploiement :
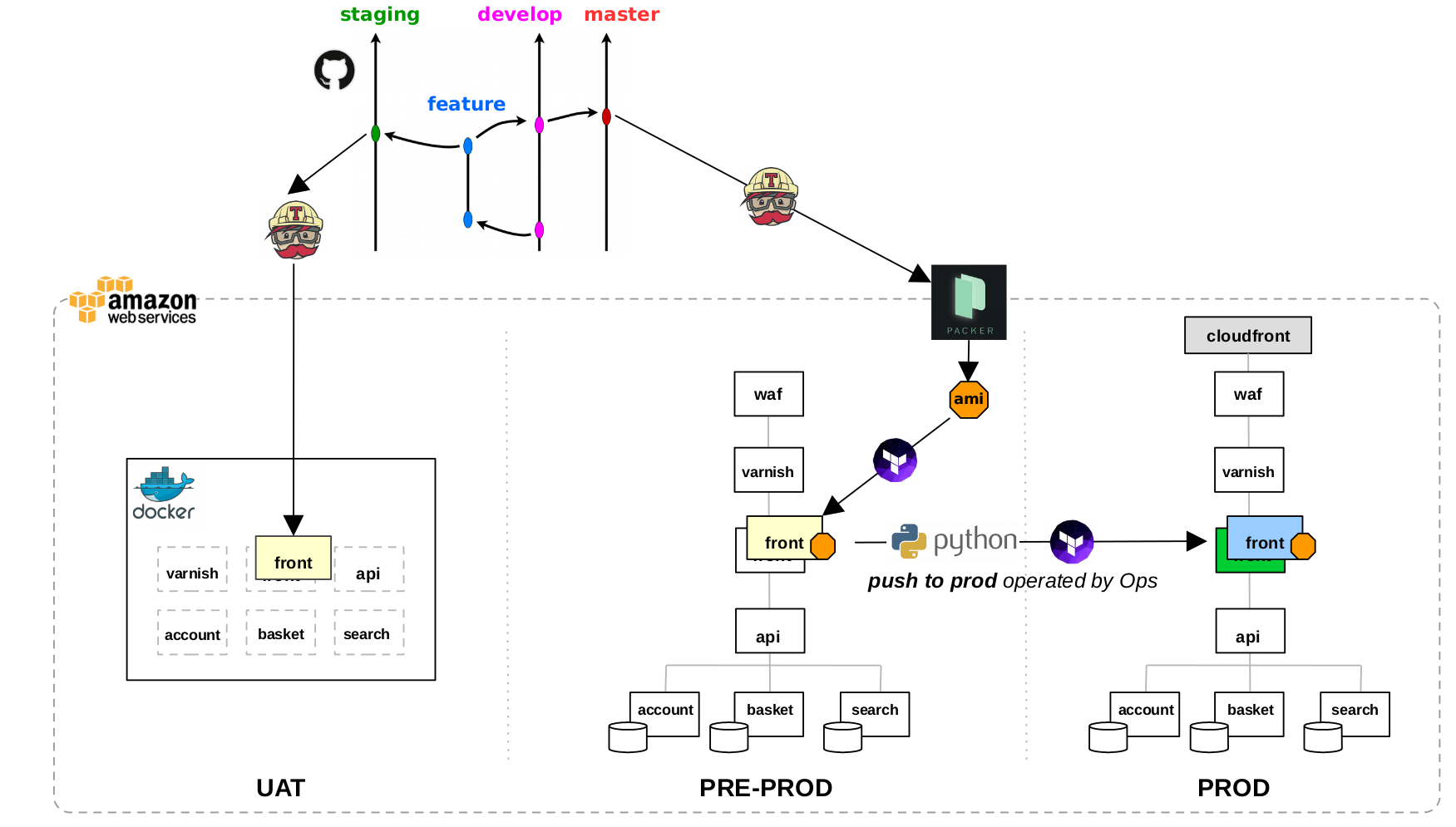
Travis automatise le déploiement en UAT et en pre-prod. Quant au déploiement en production, il est réalisé par les Ops via un script Python qui demande validation à chaque étape critique du déploiement (création des machines via Terraform, mise à jour de l’API Manager, migration des schémas de base de données, vidage du cache, bascule DNS vers la nouvelle stack blue ou green). Ainsi, les Ops gardent le contrôle sur le déploiement en production en cas de problème.
2 – Attention, les outils ne sont pas la solution miracle
Si, sans nul doute, l’automatisation passe par l’outillage, les outils ne sont toutefois pas la solution miracle. Un outil mal maîtrisé ou encore mal implémenté, pourra mettre vos objectifs en péril. Nous en avons fait les frais !
Au lancement du projet, l’équipe de développeurs était composée de 3 développeurs pour un Product Owner. Le workflow git se voulait donc simple :
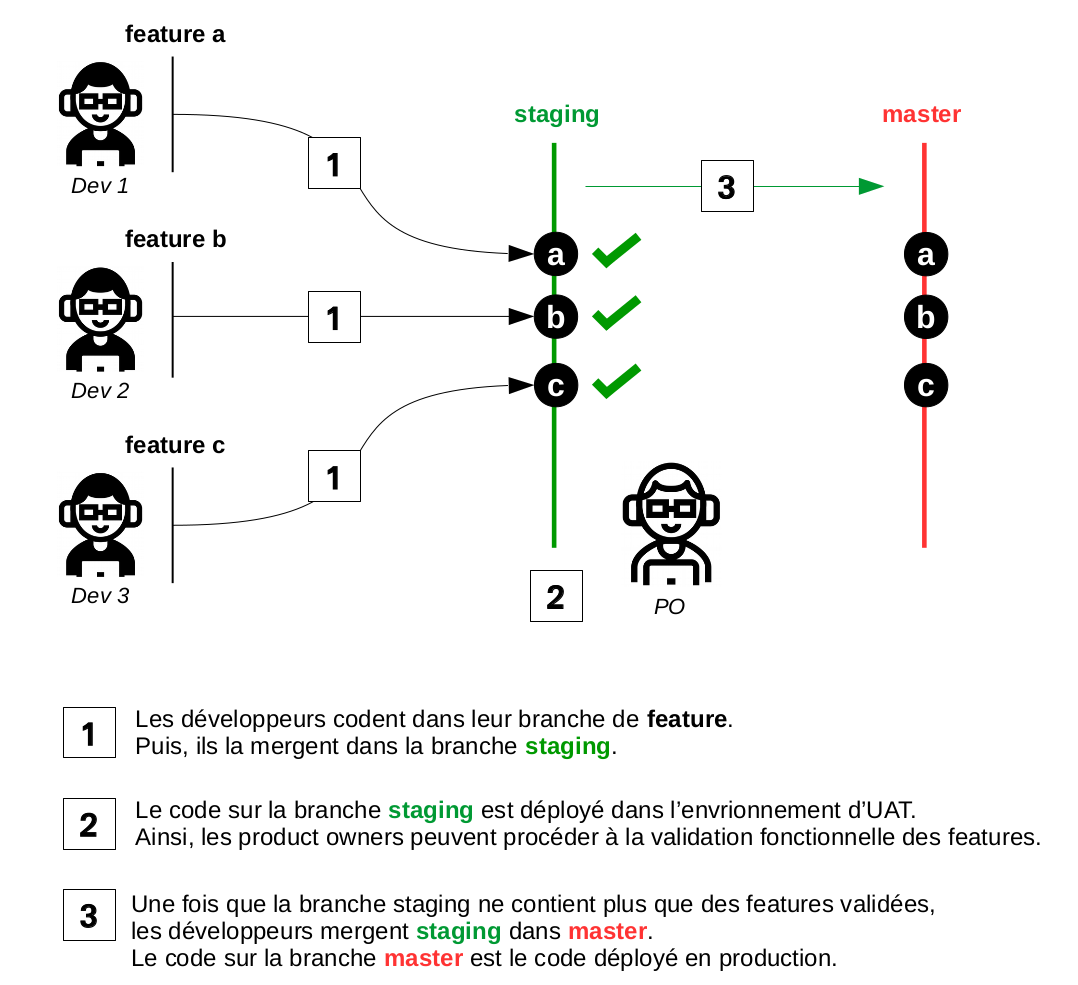
Cependant, au fil des mois, l’équipe a triplé de volume : 10 développeurs organisés en 3 sous-équipes avec chacune un product owner travaillant dans des pays différents. Entre décalage horaire et dépendance entre les équipes, il a rapidement été très compliqué d’obtenir un branche staging “ready for prod”, c’est-à-dire ne contenant que des features validées par les product owners. Ce workflow git inadapté a lourdement entravé nos mises en production quotidiennes.
Face à ces nouvelles contraintes, l’évolution de notre workflow git a été nécessaire :
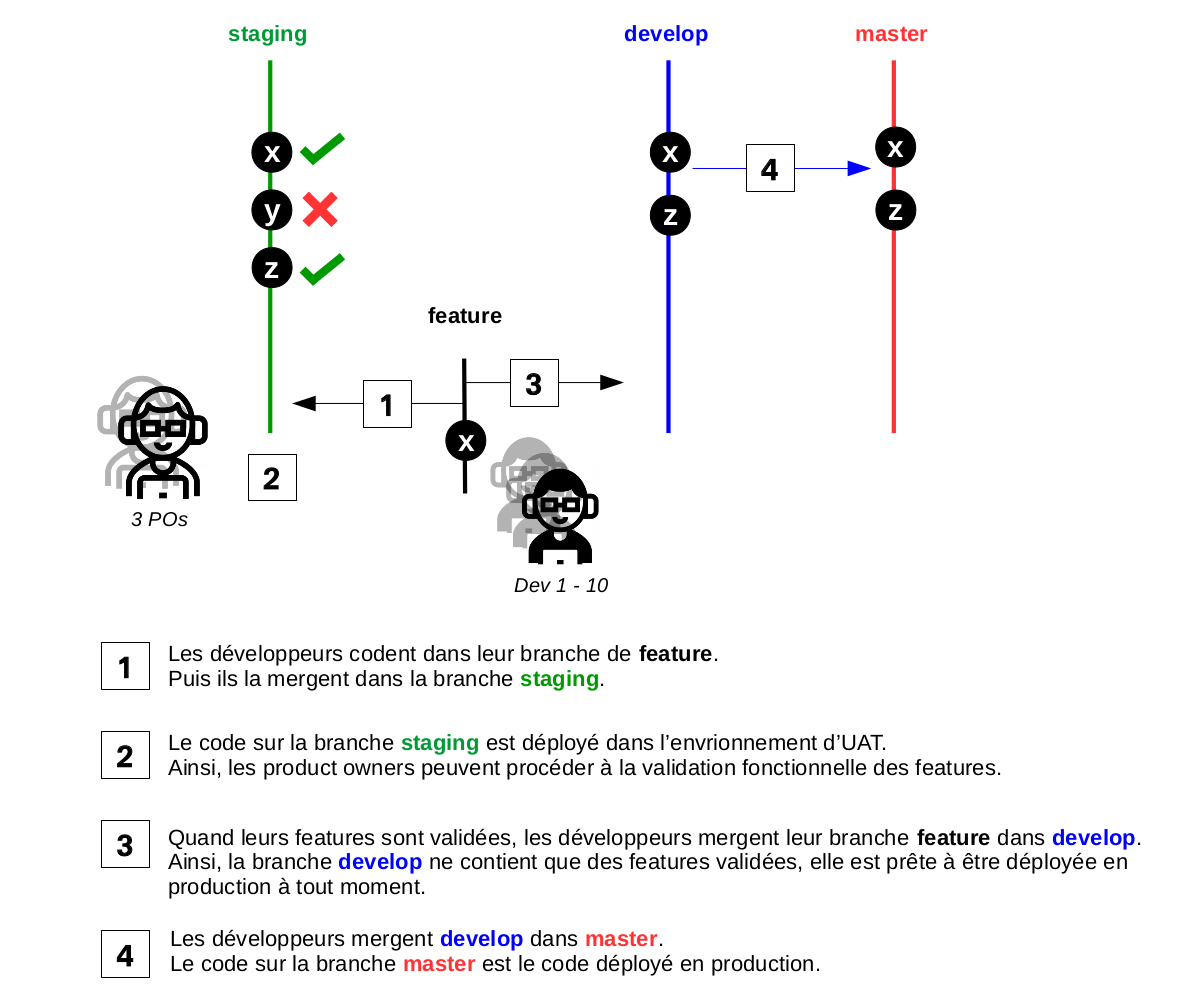
Les outils doivent répondre à des contraintes et à des besoins précis, propres à votre organisation.
3 – Devs comme Ops, maîtrisez l’infrastructure
L’architecture Cloud vient casser le modèle des infrastructures traditionnelles on-premise. La contrainte majeure du Cloud est le taux de disponibilité des machines: 99%. Cela semble peut-être anodin au premier abord. Cependant, comprenez bien que pour une application tournant sur 20 machines avec une disponibilité de 99%, sa disponibilité globale sera seulement de 80% (0.99^20).
Cette nouvelle contrainte oblige donc à repenser les infrastructures pour assurer la haute disponibilité des services. Si des mécanismes comme l’auto-scaling permettent de reconstruire automatiquement les machines indisponibles, il est également nécessaire que le code soit capable de subir cette perte de machine sans engendrer une dégradation voire une interruption du service (par exemple, pas de perte de session utilisateur lors d’un crash de machine). Dans ce nouveau modèle, la résilience des applications est portée à la fois par l’infrastructure et le code applicatif. Ainsi, plus que jamais, il est essentiel que Devs et Ops collaborent étroitement.
En outre, dans notre cas, l’implémentation du blue-green impose un certain nombre de règles à respecter et de concepts à appréhender. Par exemple, pour faire fonctionner le blue-green avec une base de données mutualisée, il faut éviter les changements disruptifs de schéma de table comme le renommage ou la suppresion de colonne afin de garder la compatibilité des deux versions du code avec la base de données. Il est primordial que les développeurs assimilent ces nouvelles contraintes qui ont un impact direct sur leur stratégie de développement.
C’est pourquoi, il incombe aux Ops la responsabilité d’accompagner et de sensibiliser les Devs à ces changements par l’organisation de workshop technique et la rédaction de documentation par exemple.
4 – Devs et Ops, enterrez la hache de guerre
Les tensions entre Devs et Ops proviennent du fait qu’ils œuvrent à des fins contradictoires: si les Devs encouragent les changements pour répondre aux exigences métier, les Ops garant de la stabilité de l’infrastructure y sont réfractaires, toute release étant perçue comme un risque.
Tout l’enjeu du DevOps est de gommer ces divergences pour créer une équipe avec des indicateurs de résultat et un objectif commun : rendre possible le déploiement continu tout en maintenant une application stable. Techniquement parlant, cela se traduit par l’automatisation des tests et des déploiements qui permettent de fréquentes mises en production tout en limitant les risques.
N’oublions cependant pas une composante essentielle : l’humain ! C’est sans nul doute ce qu’il y a de plus difficile à changer : nos habitudes et nos réflexes nous empêchent de collaborer efficacement. Pour pouvoir changer nos automatismes, il faut tout d’abord en prendre conscience. Voici par exemple deux points sur lesquels j’ai travaillé :
- Ne plus se rejeter la faute et se blâmer mutuellement pour rapidement réagir ensemble aux problèmes.
- Faire l’effort d’intégrer les contraintes des uns et des autres et d’agir en conséquence.
Pour illustrer le dernier point, j’ai un jour poussé un changement un peu trop précipitamment sur l’environnement d’UAT. Malheureusement, cela a entraîné un downtime d’une heure, au moment précis où les products owners avaient prévu la validation des features. Avec mon regard d’Ops, je ne me suis pas préoccupée des conséquences : “L’UAT, ce n’est pas la prod, c’est pas grave !” ai-je pensé. Cependant, cela a eu un impact direct pour la productivité de l’équipe puisque que j’ai mis les développeurs en retard dans leur sprint.
5 – L’organisation est tout aussi importante que la technique
Pour une collaboration réussie entre Devs et Ops, il est indispensable de repenser l’organisation de l’équipe. Voici quelques astuces qui ont considérablement amélioré nos conditions de travail au quotidien :
- Allouer 2 heures dédiées à la résolution de bugs en production par sprint et par équipe de développement. Les Ops n’auront plus à résoudre seuls les problèmes qui sont à 90% lié au code. Ils débuggeront côte à côte avec les Devs. L’esprit d’équipe renforcée et la confrontation des deux visions ne rendra que meilleure la réactivité face aux incidents. De plus, c’est un excellent exercice: les Ops comprendront davantage la façon dont est codée et construite l’application, puis les Devs appréhenderont mieux le fonctionnement de l’infrastructure.
- Travailler dans le même open space pour faciliter la communication. Durant deux semaines, nous avons dû (Dev et Ops) travailler à des étages différents. Cela n’a l’air de rien, mais un étage a suffi pour dégrader la qualité de nos échanges.
- Minimiser l’adhérence entre Dev et Ops par l’organisation de réunions hebdomadaires afin d’anticiper et de planifier les tâches liées à l’infrastructure. Ainsi, il pourra être décidé d’embarquer ou non un ticket dans le sprint selon la charge des Ops. Cela leur évitera de devoir traiter les demandes des Devs en urgence.
Enfin, le DevOps, à la fois challenge technique et humain, provoque la rupture avec l’ancien modèle de l’IT en silos. Soyez-en donc conscients, son adoption ne sera ni immédiate, ni réussie du premier coup. Mieux vaut d’ailleurs commencer sur un périmètre précis comme une application en particulier pour ensuite étendre la démarche. Pour réussir ce pari, placez-vous dans un mode d’amélioration continue et d’apprentissage. Osez l’échec pour mettre en place du DevOps à la mode de chez vous !
Ce retour d’expérience sera présenté lors du PHP Tour Nantes le 19 mai 2017 par Aurore Malherbes et Pauline Bourjot.
Commentaires :
A lire également sur le sujet :