
AWS Lambda et les architectures serverless, une révolution pour les applications ?

Parmi les nouvelles tendances apportées par le Cloud, les architectures Serverless (ou sans serveur) sont le buzz du moment. Les promesses du Serverless sont en effet séduisantes : changer la façon dont on conçoit et maintient les applications, se concentrer sur le code plutôt que sur les serveurs, baser le développement sur la logique business, et non sur les contraintes de déploiement ou de scalabilité. Pour faire le point sur les architectures Serverless et AWS Lambda, nous avons donc interrogé Julien Simon, Principal Technical Evangelist chez Amazon Web Services.
Peux-tu présenter ce qu’est Serverless et son éco-système ?
Le terme “serverless” est très en vogue actuellement et la définition des architectures serverless mérite d’être discutée. Ce sont des architectures et des applications où l’utilisateur n’a plus à gérer à la moindre infrastructure. Par rapport aux services managés comme Amazon RDS ou Amazon EMR, où l’infrastructure est créée automatiquement pour le client, nous allons encore un cran plus loin. Lors de la création d’un cluster Hadoop pour un client, nous gérons l’infrastructure et le déploiement d’Hadoop, mais l’infrastructure sous-jacente reste visible, et les problématiques de scaling sont encore du ressort de l’utilisateur. Idem avec RDS. Avec Lambda, nous proposons un service de calcul où l’infrastructure est abstraite et où l’utilisateur ne fait qu’utiliser le service. Dans le même esprit qu’Amazon S3 et Amazon DynamoDB, AWS Lambda apporte une brique supplémentaire : celle du déploiement de code avec une infrastructure abstraite. En complément, les services comme Amazon S3, DynamoDB ou Kinesis fournissent automatiquement l’infrastructure nécessaire, gèrent la haute disponibilité et le scaling, et offrent une importante sécurité pour que l’utilisateur puisse se consacrer exclusivement à la conception de son application. Serverless ne signifie pas pour autant qu’il n’y a pas de serveurs : cela veut dire qu’ils sont invisibles pour l’utilisateur. Pour résumer, les architectures serverless sont des architectures qui permettent au client de bâtir simplement des plateformes en utilisant exclusivement des services managés.

Julien Simon lors du TIAD en 2016
Quels sont les cas d’usage ?
Il y a deux grands cas d’usages pour ces applications. Commençons par les applications qui visent à automatiser la plateforme (dans une logique DevOps). AWS Lambda étant intégré à la plupart des services AWS, on programme de manière événementielle. Par exemple : quand un fichier est déposé sur un bucket S3, je déclenche une fonction qui va le décompresser et l’insérer dans DynamoDB. Quand il y a une écriture dans cette table Dynamo DB, je déclenche une autre Lambda qui va lire certains éléments et les pousser dans Amazon Redshift. En réaction à des événements (écriture d’un objet dans S3, écriture d’une ligne dans DynamoDB, démarrage d’une instance EC2, etc.), on construit donc des workflows automatisés sur la base de fonctions Lambdas, généralement assez courtes, qui vont servir de liens entre les différents services AWS. C’est une façon très efficace d’automatiser son infrastructure et ses traitements, et cela répond à de nombreux cas d’usage. Plutôt que de créer une application monolithique traditionnelle, on écrit quelques fonctions Lambda qu’on insère au bon endroit de l’infrastructure et qui font le travail.
Deuxième grand cas d’usage : la construction d’applications complètes, qui sont la plupart du temps des applications Web microservices. Les utilisateurs développent leurs microservices en utilisant AWS Lambda et les exposent via une API avec API Gateway. Ces API sont le point d’entrée du microservice qui déclenche la fonction Lambda. Celle-ci effectue le traitement et interagit avec les backends, DynamoDB, S3 ou d’autres services. Quand on n’a pas d’infrastructure à gérer, construire un backend est bien plus simple.
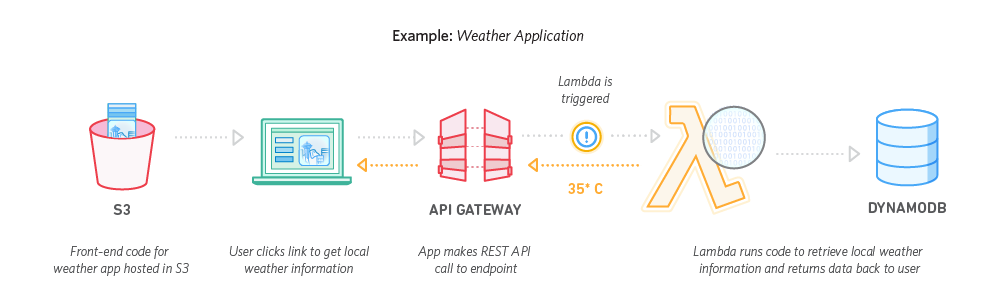
Exemple d’une application météo
Est-ce qu’il existe déjà des infrastructures 100% Serverless ?
AWS Lambda a été annoncé à re:Invent en 2014 et aujourd’hui nous avons déjà des exemples de clients dont l’architecture est 100% serverless. Cloud Guru par exemple, est une start-up qui délivre des formations IT en ligne. Leur plateforme s’appuie sur une combinaison de services SaaS (Stripe, Auth0) et de technologies Serverless avec des microservices Lambda, ce qui permet d’avoir un coût d’infrastructure strictement proportionnel à leur trafic. AWS Lambda est en effet facturé à l’appel, contrairement à Amazon EC2 qui est facturé à l’heure d’instance. Si une fonction Lambda n’est pas appelée, il n’y pas de facturation. De ce fait, Cloud Guru peut proposer des tarifs très compétitifs, et cela participe au succès qu’ils connaissent actuellement.
Quel est le taux d’adoption ? Est-ce rapide ?
Nous avons de nombreux indicateurs qui confirment que l’adoption est massive et rapide. Pour commencer, Serverless est un sujet très discuté dans les conférences et les meetups : c’est le sujet le plus régulièrement demandé. Même chose sur les webinars, Serverless arrive en tête des sondages. Je pense que nous avons dépassé la phase de curiosité initiale : les utilisateurs ont bien compris l’intérêt de Serverless et son impact sur les coûts. Aujourd’hui, tout le monde veut apprendre à le déployer. Du côté des cas d’usage d’automatisation, ça va très vite aussi. Pas une semaine ne se passe sans un nouvel article sur comment intégrer Lambda avec Slack ou un autre service. Serverless devient une brique centrale de l’automatisation des infrastructures.
Est-ce que la rapidité de mise en oeuvre en Serverless contribue aussi à son succès ?
Si on démarre un nouveau projet, oui, je pense que Serverless permet d’aller plus vite en évitant d’avoir à gérer l’infrastructure, le capacity planning, le dimensionnement. On a juste à concevoir ses services, gérer les API et coder les Lambdas. Pour moi c’est une nouvelle façon de concevoir les applications, de se concentrer vraiment sur le cas d’usage, et ce que fait chaque Lambda. Il faut s’appuyer au maximum sur les services managés : Amazon Kinesis pour les files de messages, DynamoDB pour le NoSQL, S3 pour le stockage… C’est une infrastructure Lego qui permet de piocher les services dont on a besoin, de les combiner avec des fonctions Lambda pour créer une application complexe en quelques dizaines de lignes de code. Une fois qu’on a compris ce fonctionnement, coder uniquement ce dont on a besoin pour faire le lien entre les services, il y a une accélération très forte des développements.
Serverless est aussi utilisé pour des traitements Big Data… c’est un cas d’usage plutôt surprenant ?
Il y a en effet eu un article sur un développement de MapReduce en Serverless (Prep 100GB in 70 seconds for Redhsift-Serverless MapReduce), c’est très astucieux ! L’auteur fait une comparaison entre un traitement traditionnel sur Hadoop et sur Serverless, et comme la scalabilité d’AWS Lambda est gérée par le service lui-même, cela permet de paralléliser les traitements sans gérer l’infrastructure. S’il y a 500 ou 1000 invocations, Lambda créera autant de fonctions en parallèle. Pour ce type de traitement, ça a du sens : on couple Lambda avec Kinesis pour l’envoi de messages, avec Kinesis Analytics pour faire du SQL en temps réel sans avoir à déployer des grosses machines. Bien sûr, ça ne remplace pas Spark pour autant ! Mais dans certains cas, pourquoi s’en passer si c’est la meilleure façon de faire ?
Qu’en est-il des cas d’usage IoT ?
Lors de re:Invent 2016 nous avons fait trois grandes annonces qui démontrent l’envie de nos clients d’exporter Lambda en dehors de son environnement traditionnel. Lambda@Edge qui permet d’exécuter des fonctions Lambda sur les points de présence de notre CDN, l’intérêt étant de pouvoir au plus près des utilisateurs agir sur les requêtes entrantes et sortantes. Snowball Edge, permet d’exécuter des fonctions Lambda sur des AWS Snowball (équipement pour faire des transferts de données massifs entre le client et le Cloud AWS). C’est un petit morceau du Cloud AWS dans les datacenters des clients : du stockage accessible avec l’API S3 et de l’exécution de code avec AWS Lambda. Cela devrait créer des cas d’usage intéressants. Enfin nous avons annoncé Greengrass, qui permet à des devices IoT (128 Mo de RAM et 1Ghz de fréquence) d’exécuter localement du code Lambda, y compris sans connectivité réseau. Nous en reparlerons plus en détail prochainement, mais c’est un gros progrès pour l’IoT où la connectivité réseau est le problème numéro 1. En amenant Lambda au device, on lui permet de faire des traitements locaux beaucoup plus lourds. Bien sûr le device se synchronisera avec le Cloud dès que la connectivité sera revenue.
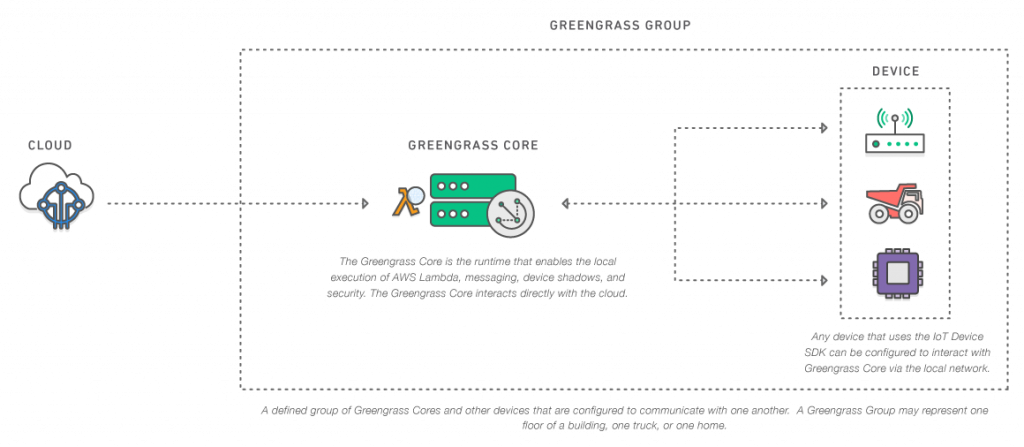
AWS Greengrass
Quels conseils donner pour se lancer dans un projet Serverless avec AWS Lambda ?
Premier point : l’utilisation d’AWS Lambda pour ce projet doit paraître évidente. Si on veut refactorer une ancienne application C#… ce n’est peut-être pas le meilleur projet pour commencer. Il est préférable de commencer par un nouveau projet, ou par quelque chose de simple, et où l’aspect services, pour ne pas dire microservices, va être évident : le découpage de l’application en API et en fonctions Lambda doit tomber sous le sens. Mon second conseil est d’utiliser au maximum les services managés, et de bien comprendre comment insérer AWS Lambda entre les services eux-mêmes. Il ne s’agit pas seulement d’avoir des API qui appellent des fonctions Lambda. La partie visible de l’application est codée avec Lambda, et il y aura certainement une partie interne qui va permettre d’automatiser: on peut en quelques lignes de code réaliser des traitements compliqués qui impliquent différents services AWS. Enfin, je conseille d’essayer différents frameworks de développement. Le marché Open source propose plusieurs frameworks sur GitHub, qui permettent de travailler de manière vraiment simple : Serverless Framework (le plus connu), Gordon (qui supporte d’autres langages comme GoLang ou Scala), APEX, Zappa qui permet de faire des microservices en Python, Chalice un projet AWS encore en beta…
Quand le projet est prêt à être déployé en production de façon automatisée, je vous conseille d’utiliser notre Serverless Application Model (SAM), une solution assez élégante basée sur CloudFormation pour déployer des applications Serverless de manière globale : fonctions Lambda, APIs, tables DynamoDB…

Zappa
Quels sont les points difficiles ou disruptifs ans un projet serverless ?
Il faut penser événementiel. C’est sans doute la plus grosse différence par rapport aux développements traditionnels. L’application est vue comme un ensemble de traitements qui réagissent à différents événements. A quels événements l’application doit-elle réagir ? C’est la question qu’il faut se poser. Que fait mon application ? Si elle fait du traitement d’image, l’événement déclencheur peut être l’arrivée d’une image dans Amazon S3. Que se passe-t-il ensuite ? On enchaîne comme ça les événements pour faire le traitement. A part ça, il n’y a pas de difficulté majeure. Comme d’habitude, la sécurité doit être un point de vigilance. De ce point de vue, chaque fonction est indépendante et a son propre rôle IAM, ce qui est une bonne chose. On va pouvoir restreindre au maximum les permissions de chaque traitement, plutôt que d’avoir une application qui dispose des droits d’écriture sur Amazon S3, Kinesis… là, les permissions sont assignées pour chaque fonction. Si une fonction doit juste écrire dans Amazon S3, elle n’aura que cette permission. Du point du vue du contrôle de sécurité, AWS Lambda a aussi un avantage par rapport aux architectures traditionnelles puisque l’on peut serrer les verrous sur chaque fonction en écrivant des rôles IAM.
Quel est l’impact de Serverless sur les équipes Ops? Est-ce que cela pose des difficultés d’un point de vue technique ou humain ?
Il est certain que Serverless peut bousculer les habitudes d’une équipe Ops habituée à manipuler des serveurs et des VMs. Cela demande de s’adapter pour travailler différemment, mais il reste des sujets sur lesquels travailler, comme l’intégration et le déploiement continus sur lesquels on peut travailler avec CodePipeline. Pour des équipes Ops, l’intérêt est de ne plus avoir à gérer les instances, pour se concentrer sur l’automatisation, la sécurité, le monitoring, bref sur la qualité de service au sens large. Personnellement, je préfère travailler sur ce genre de sujet plutôt que de packager des applications ou de distribuer des clés SSH sur des serveurs… Et puis pour l’entreprise, ne vaut-il mieux pas mettre l’accent sur la sécurité, la qualité du service et le monitoring ?
Prochain rendez-vous Serverless : Serverlessconf Paris les 14 et 15 février 2018 :

Commentaires :
A lire également sur le sujet :




