Start-up : comment monitorer une infrastructure Docker

Dans un article précédent, nous avons vu comment Docker et Docker Swarm peuvent simplifier la création d’une infrastructure scalable et adaptée aux nouveaux usages. Nous allons maintenant voir comment monitorer et comment gérer les logs sur ce nouveau type d’infrastructure, dans le contexte d’une startup., et comment répondre aux nouvelles contraintes posées par ce type d’infrastructure.
Comment monitorer une infrastructure conteneurisée ?
Le monitoring fait partie des services indispensables d’une infrastructure. Il permet de détecter les incidents, mais aussi de les anticiper pour éviter tout arrêt de service. Véritable couteau suisse, le monitoring permet aussi de débugguer une application, collecter des métriques, en tirer des graphiques, faire du reporting et du capacity planning. On l’utilise aussi bien en production que sur tous les environnements de DEV / UAT / etc…
Que cherchons nous à monitorer ?
Le premier réflexe en termes de monitoring, c’est de monitorer la machine et le système : par exemple collecter des métriques sur le CPU, la RAM, le Swap, les IOs disque et réseau, l’espace disque.
Ensuite, on va monitorer les middlewares et bases de données. En général ces solutions fournissent soit des APIs, soit des outils en ligne de commande pour récupérer différentes métriques internes qui nous permettent de déterminer la santé de l’application.
Pour les applications, cela dépend :
- Si c’est un web service ou une application web, on va monitorer son URL, son temps de réponse. Dans certains cas, le web service fournit une URL spécifique pour récupérer l’auto-diagnostic de l’application, voire des métriques.
- Si c’est une application non HTTP, on va monitorer les process, utiliser des scripts de diagnostic.
- Parfois, on monitore tout ce qui se passe dans les logs.
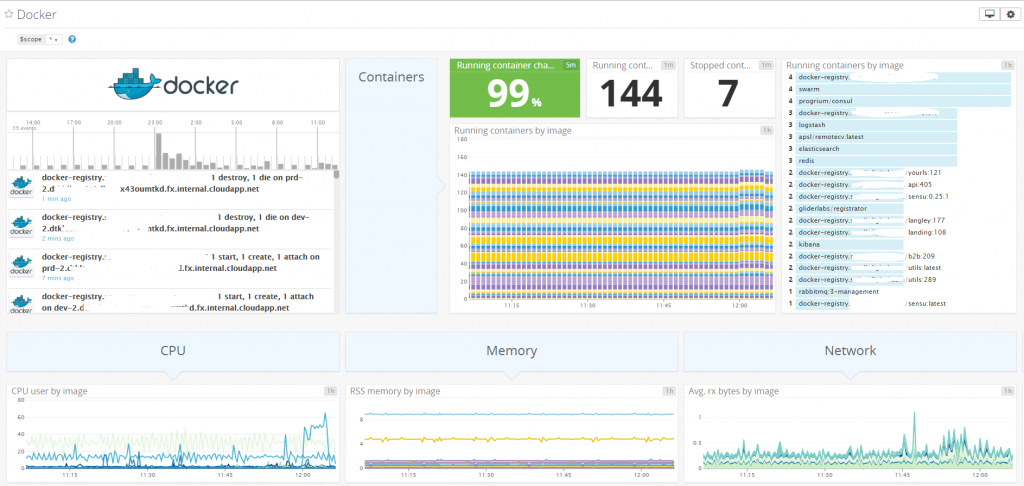
Enfin, on va avoir des applications qui exécutent des jobs. Ces applications génèrent des événements comme par exemple un message de succès ou d’échec d’une exécution d’un job de sauvegarde. Ces événements sont très importants, il faut les collecter dans le service de monitoring. Cela peut se faire en pull via de la lecture de logs, ou en push vers l’API de monitoring.
Tout cela peut permettre de savoir si une application fonctionne ou non. En revanche cela ne donne pas un état de santé d’un cluster par exemple.
Il existe aussi des solutions de monitoring applicatif (New Relic par exemple) capables d’enregistrer chaque transaction et ses performances, depuis l’application vers sa base de données par exemple. Nous n’aborderons pas ce sujet ici.
Comment faisions-nous jusqu’à maintenant ?
Jusqu’à maintenant, on installait des agents (Nagios, Zabbix, Centreon, Patrol, etc…) sur chaque serveur physique ou virtuel, voire sur les équipements réseau. On monitorait aisément les ressources hardware et les applications hébergées.

Et maintenant, avec la conteneurisation ?
Pour les applications conteneurisées sur un cluster Swarm (par exemple) on va avoir de nouvelles contraintes :
- On ne sait pas à l’avance sur quel hôte Docker Engine va être déployé le conteneur
- On ne connaît pas à l’avance son IP, et elle est par défaut dynamique
- Le noms DNS des conteneurs ne sont pas visibles depuis l’hôte. Le mécanisme est interne à Docker
- S’il est dans un réseau Docker privé (Bridge, Link, Overlay), l’application ne sera pas accessible par l’agent de l’hôte
- Le conteneur peut être re-schedulé sur un autre Docker Engine en cas d’incident sur l’hôte
- On souhaite avoir les métriques système de chaque hôte, mais aussi de chaque Docker
- On ne va pas mettre un agent de monitoring dans chaque conteneur.
En résumé, on ne va pas pouvoir avoir de configuration de monitoring statique pour chaque serveur, et l’agent ne va pas forcément pouvoir accéder à l’application via le réseau.
Mais alors, comment fait-on ?
Pour monitorer notre nouvelle architecture, nous allons par exemple :
- Déployer un agent sur l’hôte pour les métriques OS, hardware et les métriques Docker sur chaque conteneur via l’API de Docker Engine
- Déployer un conteneur agent de monitoring par réseau Docker privé, ou service Docker. Ce conteneur se chargera de monitorer l’application via le réseau privé et pourra utiliser les noms DNS Docker de chaque conteneur (base de donnée, web service, cache, etc…).

On constate donc que les métriques liées à une application (métriques du/des conteneurs de l’application et métrique de l’application même) vont être remontées par plusieurs agents. Il faut donc avoir une solution qui facilite la corrélation et l’agrégation de ces métriques.
Les anciennes solutions open source ou propriétaires ne savent répondre à ce besoin. Il faut donc se tourner vers les nouvelles solutions telles que DatadogHQ, Sematext, NewRelic, SysDig Cloud, Prometheus, Sensu.
Dans le cadre du Kit Startup, nous avons choisi DatadogHQ pour les raisons suivantes :
- Version gratuite pour monitorer 5 serveurs
- Collecte des métriques OS et Docker Engine
- Collecte des Events Docker
- Version Docker de l’agent
- Très bonne intégration avec l’écosystème DevOps (Slack, PagerDuty, CI/CD)
- Nombreux produits du marché supportés
- Dashboards pré-configurés
- Facile à installer
- Agrégation et corrélation des métriques grâce aux tags
- Bonne gestion des alertes
- API de configuration et module Ansible pour l’API
Nous lui avons trouvé un petit défaut, c’est la gestion de configuration. En effet, la configuration des paramètres des checks de monitoring se fait dans un seul fichier par type de check. Par exemple, si on a plusieurs web services HTTP à monitorer, on doit tous les configurer dans un seul fichier. C’est assez pénible à industrialiser correctement afin de gérer l’ajout, la suppression, la modification d’un check parmis les autres dans le même fichier. Sensu répond très bien à cette problématique car on peut faire un fichier par check, ce qui est beaucoup plus simple à gérer avec un outil de gestion de configuration.
Gestion des logs
Toute application se doit de générer des logs. Les logs contiennent toutes les informations indispensables sur l’exécution d’une application. On retrouvera par exemple les erreurs d’exécution, les warnings, des informations sur ce que fait l’application, qui l’utilise, les tentatives ratées d’authentification. Ces informations sont précieuses pour les développeurs, comme les Ops, le support, mais aussi pour la sécurité.
Le fait d’avoir une architecture dynamique change la façon dont on gère les logs. Encore une fois, chaque conteneur peut être instancié n’importe où sur le cluster Docker Swarm. On ne peux donc pas déterminer à l’avance où collecter les logs applicatifs. De plus, l’application va probablement être instanciée plusieurs fois sur le cluster afin de supporter la charge et faire de la haute disponibilité.
On se rend rapidement compte qu’il va être difficile d’aller consulter chaque fichier de log de chaque conteneur, un par un pour trouver une trace d’erreur ou analyser le trafic.
Heureusement il existe de nombreuses solutions pour collecter et rendre exploitables vos logs :
- Logguer classiquement dans des fichiers texte stockés dans des volumes Docker.
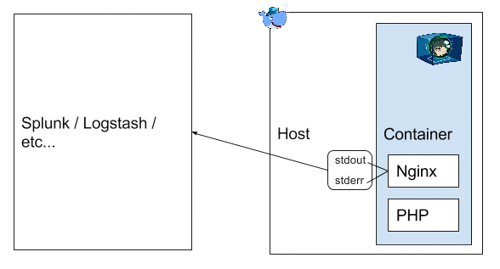
- Logguer directement sur les sorties standard du conteneur. Elles sont lues par Docker Engine et consignées dans un fichier Json. Nous déconseillons cette solution en production car il n’y a pas de rotation et compression des logs, ni de limite de taille. De plus, si on a plusieurs instances du conteneur, il faut consulter les logs de chaque conteneur. Nous réservons cette solution pour les développements et les tests.
De plus, cette méthode fonctionne aisément dans des conteneurs mono process, mais pas quand on fait tourner 2 applications dans le même conteneur. Par exemple, un container qui contient Nginx et PHP en même temps.
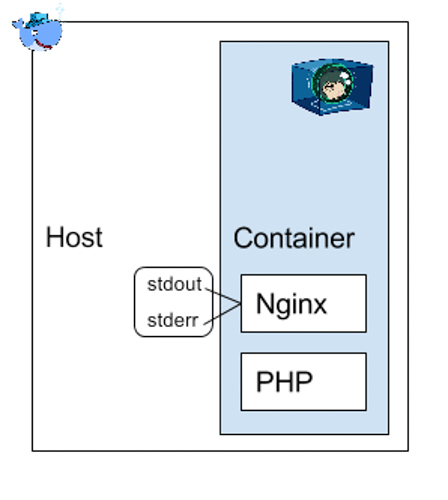
- Utiliser un plugin Docker de logging pour envoyer les logs vers Splunk, Elasticsearch ou Graylog. Attention, la problématique précédente sur le multi-process dans le même conteneur reste la même.
- Soit adapter l’application pour envoyer les logs directement par le réseau (HTTP par exemple) à un des outils de gestion de logs cités ci-dessus, sans passer par Docker.
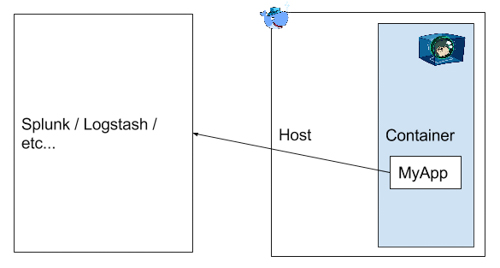
Le choix se fera en fonction des capacités de logging de l’application. On pourra évidement mélanger les 4 méthodes ci-dessus.
L’avantage des deux dernières solutions, c’est que l’on va pouvoir collecter les logs de nos conteneurs.
En revanche, il est fortement déconseillé d’écrire les logs dans un fichier, dans le conteneur sans passer par un volume Docker.
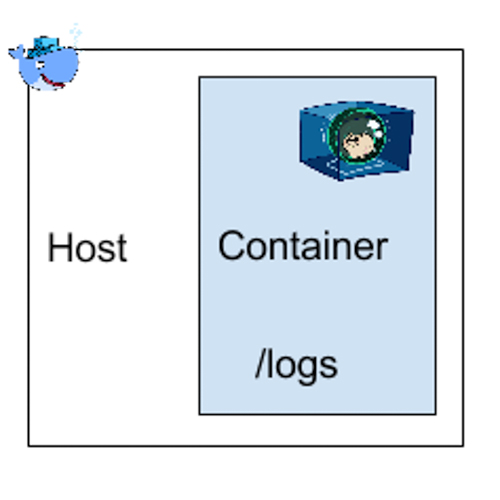
En effet, on risque d’avoir des problèmes de performances sur les I/Os disque, mais surtout les logs ne seront pas directement exploitables depuis l’extérieur du conteneur. Il est plus que recommandé de ne pas stocker les données variables d’une application dans le conteneur. Les volumes Docker sont là pour répondre à ce besoin.
Dans le Kit Startup, nous utiliserons par exemple le PaaS Logs d’OVH pour que le démon Docker Engine envoie par défaut les logs sur le service ElasticSearch / Kibana / Graylog d’OVH.
Pour aller plus loin, nous vous conseillons de vous référer à ces exemples de configuration pour récupérer les logs de différents outils.
Conclusion
Nous venons de voir différentes pistes adaptées aux startups afin de monitorer et gérer correctement les logs. Nous avons vu que la conteneurisation, la distribution des applications sur les clusters, les réseaux virtuels Docker, imposent de radicalement changer notre approche, voire les outils, afin d’être capable à tout moment d’anticiper ou détecter des incidents, mais aussi de les diagnostiquer de manière efficace. Dans notre prochain article, nous étudierons différentes stratégies de sauvegarde, et nous donnerons des conseils pour gérer la restauration des données ou de l’infrastructure complète.
Commentaires :
A lire également sur le sujet :