GameDay AWS : testez la résilience de vos applications Cloud en conditions de production

Les journées tranquilles ne font pas les bons pompiers : c’est en situation de crise qu’on apprend le plus, et pour s’y préparer il faut des environnements de simulation. C’est de cette idée qu’est né le GameDay AWS, où durant une journée complète les équipes Ops doivent faire face à des situations critiques qu’ils sont susceptibles de rencontrer en production. Le premier GameDay en France a été organisé par D2SI : compte-rendu d’une journée sous pression.
Valoriser les apports de l’automatisation, tester leur connaissances des services AWS, optimiser l’infrastructure, partager les best practices issues de l’expérience…les attentes des six participants du GameDay AWS de ce jour sont variées. L’objectif de cette journée est d’apprendre par une mise en situation pratique, et pour ce faire les équipes de Veolia ont préparé une infrastructure AWS de test. Trois équipes sont constituées : deux équipes de deux, composées d’un développeur et d’un opérationnel, et une équipe d’observateurs. Les observateurs peuvent aussi prendre le rôle d’un utilisateur du système, voire d’un élément perturbateur !

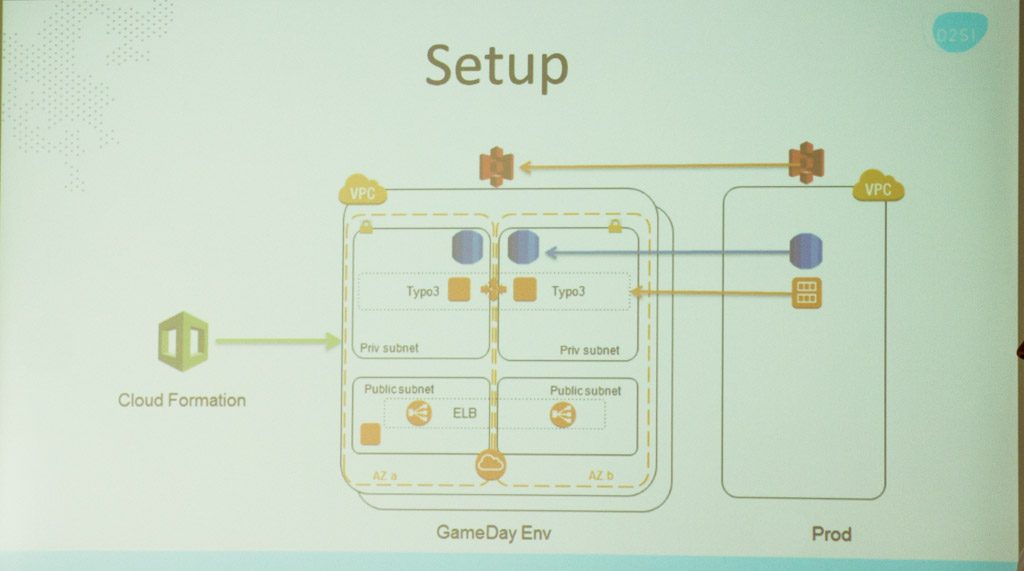
Démonstration de CloudFormation par Laurent Bernaille
10.09
La journée commence par un rapide cours sur CloudFormation. L’outil était peu connu des équipes, or les outils d’automatisation sont la clé des infrastructures résilientes.
Chaque équipe commence par déployer sa propre stack à partir de CloudFormation. Des instructions sont fournies pour la création d’une infrastructure Intranet. Les participants se connectent sur la console AWS et lancent leur stack. A terme, ils disposent de trois stacks complètes pour faire des tests.
10.42
Les stacks sont prêtes et l’application fonctionne normalement. Jusque-là, tout va bien, la production simulée est sous contrôle, et tous les indicateurs sont au vert. Le GameDay AWS peut commencer !
10.50
Le premier scénario a été lancé. Trois erreurs sont signalées par le monitoring. Rien ne fonctionne plus, que se passe-t-il ? Où sont passées les instances?
10.53
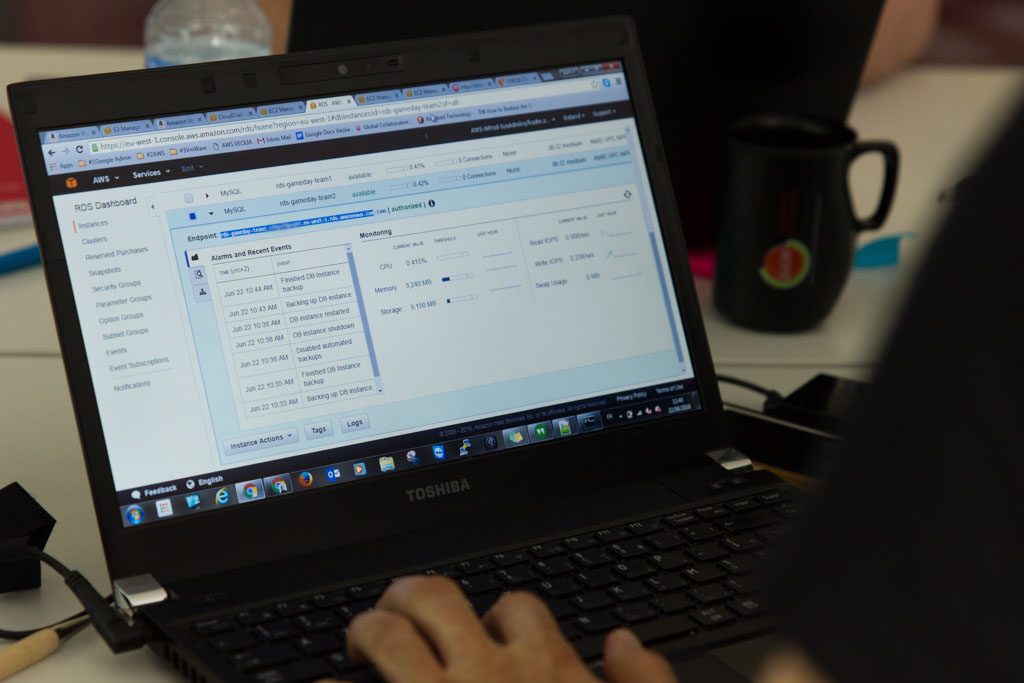
Les instances sont redémarrées. Les équipes cherchent à comprendre ce qui s’est passé. Visiblement, les machines ont été arrêtées quelques minutes plus tôt. Laurent Bernaille, Jean-Charles Fesantieu et Nicolas Monchy, qui organisent la journée, donnent l’explication : ils ont simulé une panne d’hyperviseur.
10.56
On passe au debriefing. La discussion commence sur l’utilisation de CloudFormation et de la création de stacks, pour trouver des axes d’amélioration en termes de sécurité (SSL, HTTPS), avant de passer à l’explication du premier scénario. Premier symptôme constaté : la page ne s’affiche plus. Différentes options ont alors été vérifiées : est-ce que le port communique ? Si oui, les instances sont-elles OK ? On constate que la première des deux instances était tombée quelques minutes avant qu’on ait une alerte : le loadbalancing avait pris le relais, mais personne n’avait eu l’information de la panne tant que la seconde instance n’était pas tombée. Conclusion de ce premier scénario : il faut mettre en place des alertes au niveau de l’auto-scaling group AWS pour être notifié si une des instances tombe.
11.15
Pendant que le second scénario se prépare, Laurent Bernaille conseille les équipes sur le réglage des notifications de l’autoscaling et des paramètres du loadbalancer, avant de leur demander de vérifier la disponibilité du site… qui ne répond plus ! Les équipes reprennent leurs investigations. D’après Elastic Load Balancing, aucune instance sur les deux n’est en service. Et pourtant, elles semblent fonctionner… Seconde vérification, peut-on se connecter à ELB ? Les équipes continuent à chercher jusqu’à ce que l’explication soit donnée : le security group associé à l’ELB n’autorisait pas le trafic en sortie. Résultat, les paquets sont droppés, et la requête finit en timeout. Ce problème de communication entre ELB et les machines se rencontre assez fréquemment en production, et de fait le fonctionnement de l’ELB mérite d’être expliqué en détail.
11.30
Debriefing : les organisateurs commencent par passer en revue les différentes étapes de troubleshooting suivies par les participants avant d’aborder les best practices et les vérifications à effectuer sur le security group. Ce scénario, qui peut intervenir à la suite d’une erreur humaine, met en avant la nécessité de s’outiller pour améliorer le troubleshooting, avec les outils de monitoring interne ou les outils AWS (CloudTrail, AWS Config pour vérifier les changements de configuration avant/après l’incident). Autre point important, il faut savoir diagnostiquer les problèmes de communication qui sont une problématique courante (avec des outils comme nc, TCPdump).
Game Day AWS @TIAD Paris
13.40
Après une pause déjeuner bien méritée, le troisième scénario est lancé. Les choses se compliquent cette fois-ci, et les équipes ont du mal à trouver la panne. Une des instances a un comportement anormal…pourquoi ? Les machines sont fonctionnelles, mais l’une d’entre elles n’est pas en service du point de vue du load balancer.
13.50
Ici les équipes n’ont pu identifier la panne qu’une fois directement connectées en SSH aux machines en question : le serveur Apache ne fonctionnait plus. Dans cette phase de la simulation, c’est le service qui porte l’application qui a crashé. Sur ce type de panne, il est important d’identifier la cause avant de redémarrer la machine, sinon le crash peut se reproduire.
Quelles sont les bonnes pratiques à mettre en oeuvre dans ce scénario ? Le premier réflexe à avoir est d’accéder aux fichiers de logs, et de pouvoir faire des métriques sur la RAM et les disques pour vérifier s’ils sont pleins. Pour prévenir ce type de panne, on peut mettre en place des alertes, mais encore faut-il savoir quelles métriques surveiller… et trouver le bon niveau d’alertes. Au-delà d’un certain nombre de mails d’alertes par jour, le risque est grand de les ignorer. Avant de passer au scénario suivant, les équipes font quelques modifications au niveau de l’autoscaling group suite aux enseignements du debriefing. Précisons que par défaut, un Autoscaling Group considère qu’une instance va bien si elle est fonctionnelle du point de vue de l’hyperviseur (qu’elle rende le service du point de vue de l’ELB ou non). Une autre option serait de considérer qu’une instance qui ne rend pas le service vu de l’ELB doit être considérée comme non fonctionnelle par l’Autoscaling Group.

Bilan des alertes en temps réel
14.25
Le scénario suivant laisse les équipes perplexes : le monitoring est au vert, ELB et autoscaling sont OK, et pourtant… une modification a été apportée dans le code de la page Index, générant une erreur sur la page d’accueil. C’est une autre cause de panne fréquente : le code est fonctionnel, mais il suffit qu’un fichier ne soit pas au bon endroit ou ne soit pas nommé comme il faut pour créer une erreur.
Dans ce cas précis, la configuration du Healthcheck était faite en TCP par manque de connaissance de l’application. On avait donc un bug applicatif qui empêchait d’afficher quoi que ce soit, mais l’ELB arrivait bien à établir des connexions TCP avec le serveur Apache. La bonne pratique recommandée est ici de faire un Healthcheck qui établit une connexion HTTP et valide qu’une page de test est bien fonctionnelle. Cependant, il faut être vigilant sur la fréquence des Healthcheck en fonction de la charge en compute de chaque page.
If something is hard, repetition makes it easy
Si pour tous les participants, l’apport de l’automatisation et des services AWS est incontestable, la journée met en évidence la complexité de la gestion d’une production sur le cloud. Que les scénarios de panne soient liés à AWS (comme le scénario S3 Bucket Policy) ou à d’autres sujets (une table de la base de données qui tombe, scénario testé en fin d’après-midi), leur résolution demande le plus souvent l’expertise combinée des Ops et des Dev. D’autres scénarios ont été testés durant cette journée, et les équipes présentes ont beaucoup appris sur les services AWS, l’outillage associé et sur leur application. Cela leur a permis d’améliorer l’architecture de l’application, en mettant à jour CloudFormation, et de repartir avec de nombreuses idées pour mieux déployer et gérer leurs applications.

Debriefing : type de panne, axes d’amélioration…
Commentaires :
A lire également sur le sujet :