Monitoring as Code : comment intégrer le monitoring au cycle de vie des applications ?

Le serveur est-il down ? Le CPU à 100% ? La RAM pleine ? Encore très récemment, le monitoring était essentiellement orienté vers l’infrastructure, et conçu par l’infrastructure. Pourtant, les applications aussi ont besoin d’être monitorées, et qui est le mieux placé pour savoir quelles règles de monitoring mettre en place, si ce n’est les développeurs eux-mêmes ?
L’idée de mettre en place un vrai monitoring applicatif est très récente. Jusque là, le monitoring était relativement peu déployé sur les applications, le plus souvent statique, et mis en place par des équipes d’infrastructure, sans discussion avec le développement.
Le monitoring, source de faux incidents ?
Forcément, de mauvaises surprises accompagnaient chaque déploiement…comment expliquer au métier que l’application a crashé et qu’on n’a pas eu d’alerte ? La décision est alors prise de monitorer l’application, mais à la livraison suivante, tous les indicateurs de monitoring sont au rouge. Que s’est-il passé ? Certains process ont changé dans l’application, et les règles de monitoring ne sont plus adaptées : cela a généré des incidents, des astreintes, faussé les KPI…tout cela parce que le monitoring n’était pas adapté à la dernière release. C’est ce décalage entre le cycle de vie de l’application et celui du monitoring qui crée des situations contre-productives. Tant que le monitoring reste géré pas des équipes hors du cycle applicatif, il ne génère pas de valeur ajoutée, et pire, il génère de faux incidents.
Intégrer le monitoring au cycle applicatif
Développement, commit sur un gestionnaire de sources, intégration continue, déploiement sur un environnement de développement, UAT, préproduction puis production…: avant d’arriver en production, l’application passe par différents environnements. Alors, pourquoi ne pas déployer également le monitoring sur ces environnements ? Si le monitoring n’est pas testé, s’il n’est déployé qu’au moment de la production, alors il est déjà trop tard. Il faut pouvoir versionner le monitoring avec le code source de l’application. La nouvelle version du code est commitée avec la nouvelle version de configuration de monitoring. L’intégration continue teste alors l’application, déploie la configuration de monitoring en test, et fait des tests unitaires sur chacune des règles.
On vérifie par exemple que si on fait tomber un process, l’alerte monitoring est bien déclenchée, ou inversement qu’il n’y a pas d’alerte tant que le process n’est pas tombé. On peut également tester un plugin de monitoring maison de la même manière que l’on testerait du code.
Ensuite, on déploie la configuration de monitoring adaptée sur chacun des environnements (développement, préproduction, production…) : la configuration de monitoring est “variabilisée” en fonction de l’environnement. Et à chaque étape, tous ces déploiements sont testés de façon à être certain qu’à chaque version d’application, correspond la même version de monitoring. Au moment de passer en production, on utilise un seul outil pour orchestrer le déploiement de l’application et du monitoring. En cas de souci, il est toujours possible de rollbacker l’application et le monitoring, de façon à ne jamais avoir d’écart.
HP Operations Manager
Inclure les développeurs
Pour mettre en place un vrai monitoring applicatif, il faut aussi impliquer les développeurs : sensibiliser les développeurs à la question du monitoring leur permettra de mieux concevoir leurs applications dans l’optique du monitoring. Par ailleurs, qui est mieux placé qu’un développeur pour savoir comment son application doit être monitorée ?
Dans le meilleur des mondes, le monitoring doit être conçu par les développeurs et les Ops : leur expertise est complémentaire. Ainsi on pourra parvenir à un monitoring efficace, utile à l’application…mais aussi au métier. Combien de deals, combien de clics génère l’application ? Les développeurs peuvent ainsi avoir une vision métier de leur application, et donc identifier les indicateurs les plus pertinents. A terme, c’est un monitoring transversal qu’il faut viser : infrastructure, application… et métier.

DataDog HQ
Quels outils pour monitorer ?
L’écosystème de solution de monitoring est relativement vaste. Nous avons pu expérimenter ces concepts sur les solutions suivantes :
- DatadogHQ : une solution très complète de Monitoring as a Service. Il s’intègre à des nombreux autres outils de l’écosystème du monitoring. Grâce à sa gestion de la configuration et son API, il est très facile de faire du Monitoring as Code (MaC) avec des outils de gestion de configuration tels que Ansible ou Puppet, et des outils de déploiement continu.
- HP OM : Cette suite très complète à installer “on premise” permet de créer des templates de monitoring, de les instancier manuellement ou automatiquement via l’auto discovery. Ces templates peuvent être gérés dans des fichiers, ce qui permet d’intégrer leur gestion dans les outils de gestion de configuration et de déploiement applicatifs.
- Nagios : On ne présente plus cette solution historique et libre. Sa gestion de configuration en mode fichier en fait un candidat parfait également.
- Sensu : Un petit nouveau, écrit en Ruby qui a pour ambition de moderniser Nagios grâce à une architecture plus moderne à base de Redis et RabbitMQ, une API, et des agents qui peuvent même utiliser des checks écrits pour Nagios.
Exemple avec DatadogHQ et Ansible
Dans cet exemple nous allons déployer une petite application Web et superviser l’URL avec DatadogHQ. Vous trouverez les sources sur notre dépôt Github.
Voici le squelette de notre application Web :
[captnbp@d2si:~/meetup-monitoring]$ ls -all
total 16
drwxr-xr-x 5 bpourre users 4096 29.04.2016 18:25 roles/
-rw-r--r-- 1 bpourre users 50 29.04.2016 18:25 Dockerfile
-rw-r--r-- 1 bpourre users 95 29.04.2016 18:25 index.html
-rw-r--r-- 1 bpourre users 802 29.04.2016 18:25 meetup-monitoring.yml
Nous retrouvons :
- Le fichier source index.html de l’application
- Le Dockerfile pour la builder
- Le playbook Ansible meetup-monitoring.yml
- Et les rôles Ansible pour le déploiement du Docker, des règles de monitoring et des tests d’intégration.
Notez que le playbook Ansible est versionné avec le code de l’application.
Voici le contenu du playbook :
- hosts: "{{ host }}"
roles:
- { role: deploy-app, tag: deploy-app, state: started }
- { role: integration-tests, tag: integration-tests }
- { role: Datadog.datadog, tag: deploy-checks, sudo: yes }
- { role: deploy-monitors, tag: deploy-monitors, state: present }
- { role: deploy-monitors, tag: mute-monitors, state: mute }
- { role: deploy-app, tag: undeploy-app, state: absent }
- { role: deploy-monitors, tag: undeploy-monitors, state: absent }
vars:
test_url: "http://{{ host }}:{{ port }}/index.html"
datadog_config:
tags: "env:meetup"
log_level: INFO
datadog_checks:
http_check:
init_config:
instances:
- name: My first test
url: "http://{{ host }}:{{ port }}/index.html"
timeout: 2
Nous retrouvons ici l’appel aux différents rôles que nous allons utiliser pour déployer l’application et son monitoring pour les tests d’intégration. Nous retrouvons également la définition variabilisée du Check DatadogHQ dans les variables.
Ce playbook sera exécuté par Jenkins :
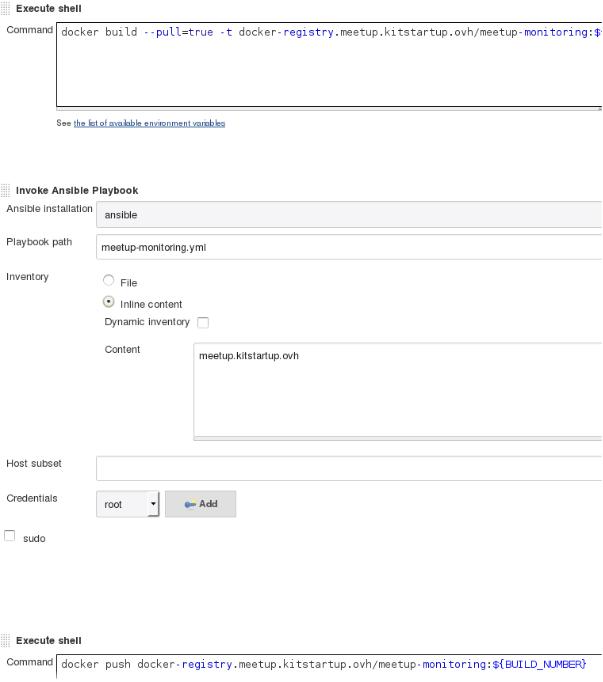
A chaque commit de code dans le dépot de l’application, Jenkins va builder l’image Docker, puis lancer notre playbook. Le playbook va dans l’ordre :
- Déployer l’image Docker précédemment créée :
- name: "Deploy meetup app {{ state }}"
docker:
name: meetup-app
#pull: always
image: "docker-registry.meetup.kitstartup.ovh/meetup-monitoring:{{ build_number }}"
state: "{{ state }}"
ports:
- "{{ port }}:80"
- pause: seconds=30
- Lancer les tests d’intégration. Dans cet exemple, c’est un simple curl sur l’url
- Si tout se passe bien, on déploie le check DatadogHQ
- Puis le “monitor” afin de créer une règle d’alerting
# Create a metric monitor
#- name: "{{ state }} URL Monitor"
- pause: seconds=15
- datadog_monitor:
type: "service check"
name: "Test monitor URL"
state: "{{ state }}"
query: '"http.can_connect".over("env:meetup").last(3).count_by_status()'
message: "Test ! @benoit.pourre@revolve.team"
api_key: "{{ datadog_api_key }}"
app_key: "{{ datadog_app_key }}"
- pause: seconds=15
Si tout s’est bien passé :
- On coupe la règle d’alerting
- On supprime l’application déployée pour le test
- On supprime la règle d’alerting (“monitor”)
Commentaires :
A lire également sur le sujet :