
Data Unlimited : Open Data sur Google Cloud Platform
Visualisation par Etienne Côme
200 millions de trajets en 7 ans, plus de 274 000 abonnés, 1 Vélib’ loué chaque seconde… depuis 2007, les franciliens ont réalisé l’équivalent de 5 aller-retours Terre-Mars en Vélib’ ! Imaginez alors le volume de données généré quotidiennement par les usagers du Velib’…
Initié afin de découvrir la plateforme Cloud de Google dans un cadre concret, le projet Data Unlimited avait également pour objectif de challenger la plateforme avec de forts volumes de données issues de l’Open Data. Nous avons opté pour les données Open Data des Vélib’ de Paris (JCDecaux), que nous avons pu manipuler selon les axes suivants :
- Affichage en temps réel des informations
- Historisation et statistiques issues des informations récoltées
À la découverte de Google Cloud Platform
JCDecaux fournit l’état de « N » stations de par le monde, chacune pouvant accueillir « M » vélos en moyenne (Paris compte 1260 stations et environ 17 000 Vélib’) : traiter un tel volume de données en temps réel représentait un véritable challenge en termes de puissance de calcul et de stockage.
Afin de répondre à ces contraintes, trois services managés ont été utilisés principalement :
- Google App Engine pour afficher le site et gérer les tâches asynchrones
- Google Cloud Storage pour stocker les données
- Big Query pour les besoins d’analyse des données historisées
Coder une application avec Google App Engine
Le site hébergé sur Google App Engine a été développé en Python (utilisant le framework webapp2 et les templates Jinja).
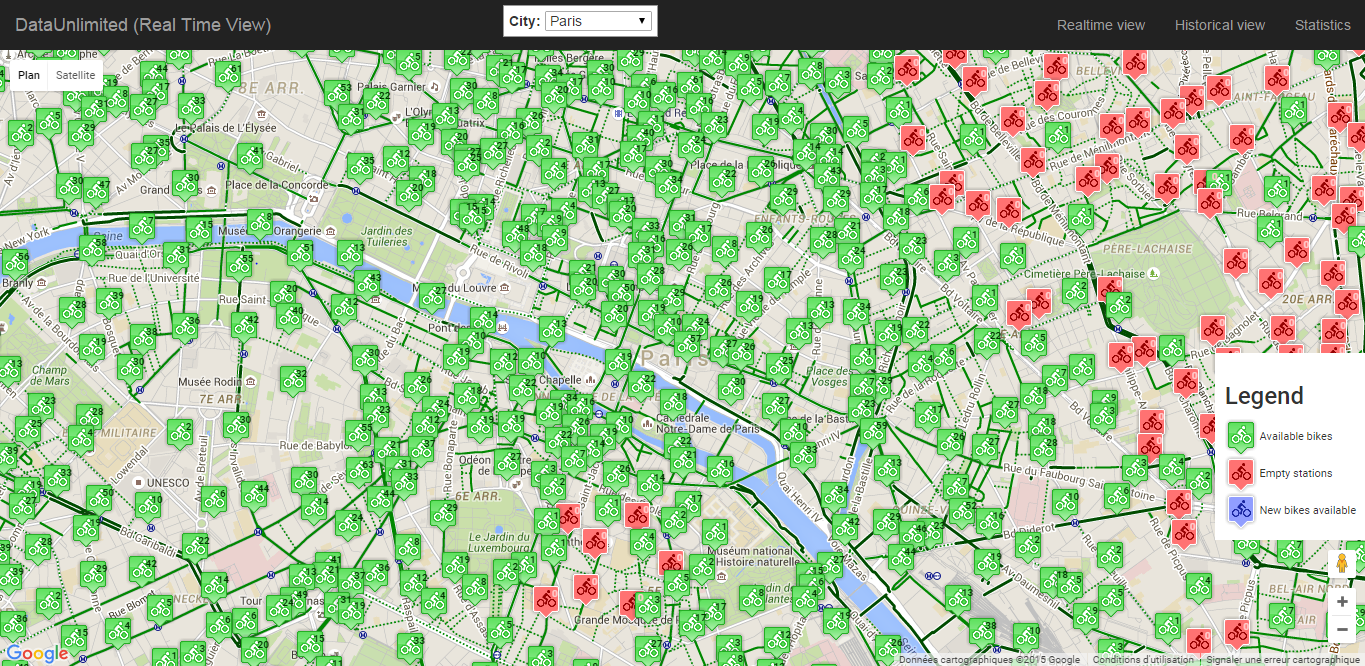
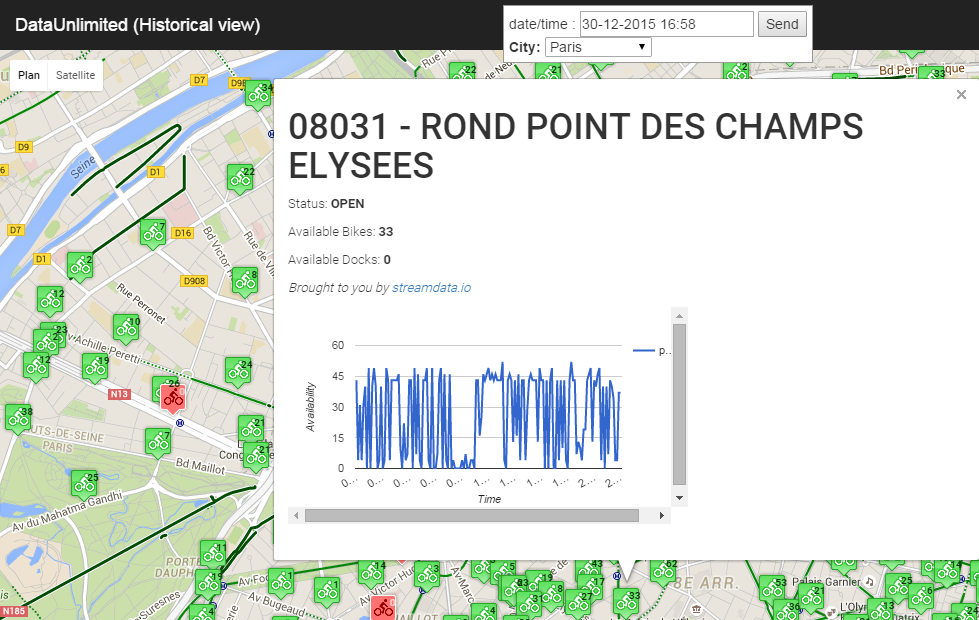
Données Vélib’ en temps réel
App Engine assure la disponibilité du site tout en s’adaptant à la charge, permettant ainsi de limiter les coûts en fonction du besoin. Le nombre d’instances servant les pages Web du site est en effet provisionné automatiquement en fonction de la charge et de la configuration appliquée. Ce service managé est accompagné de fonctionnalités fort appréciables comme la gestion des versions, l’accès aux logs ou encore les indicateurs de performance.
Premier obstacle rencontré : le navigateur Web avait trop de données à traiter, en particulier pour Paris où le nombre élevé de stations Vélib’ se traduisait par des chargements de page pouvant prendre jusqu’à plusieurs secondes. Nous avons donc décidé d’utiliser StreamData comme intermédiaire. Cette API a en effet pour but de fournir uniquement les mises à jour entre deux appels : le gain est donc considérable en termes de volumes de données, tant au niveau du transit que du traitement.
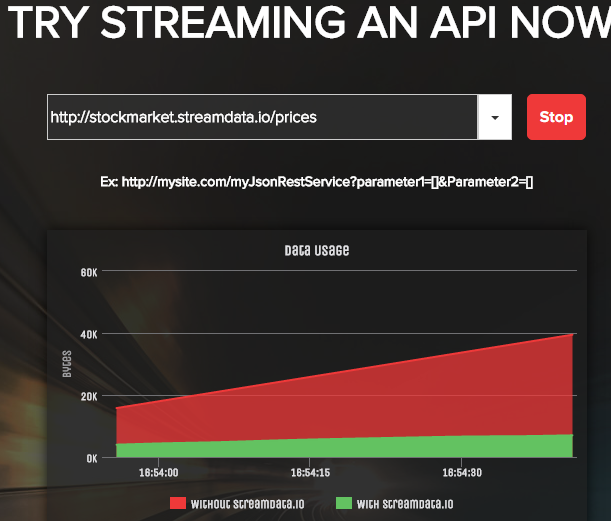
Exemple de volume de données avec et sans Streamdata.io
Google Cloud Storage et BigQuery pour répondre aux enjeux Big Data
Le cas des données en temps réel ayant été traité, le second sujet à adresser concernait l’analyse de l’utilisation des stations Vélib’ à partir d’un historique. Ce point a soulevé une nouvelle problématique : quid du stockage et de l’analyse de ces données ? Pour stocker quotidiennement plusieurs Gigas de données, utiliser un environnement avec une base de données offrant la puissance de calcul et l’espace de stockage adéquats n’était pas envisageable.
Quitte à avoir un pied sur la plateforme Cloud de Google, pourquoi ne pas continuer l’exploration de cet écosystème ? Nous avons donc opté pour Google Cloud Storage qui permet de stocker les « données brutes » récupérées depuis JCDecaux et BigQuery qui assure la partie analyse de très gros volumes de données.
Pour résumer l’architecture :
Une tâche planifiée (configurée dans App Engine) lance un script Python qui télécharge les données dans l’API de JCDecaux. Cette partie est la plus gourmande de l’application en termes de stockage et de mémoire. Ce script est exécuté toutes les minutes : il récupère les données, les traite (formatage des données, zip), les stocke dans Google Cloud Storage et lance finalement le job d’insertion dans BigQuery.
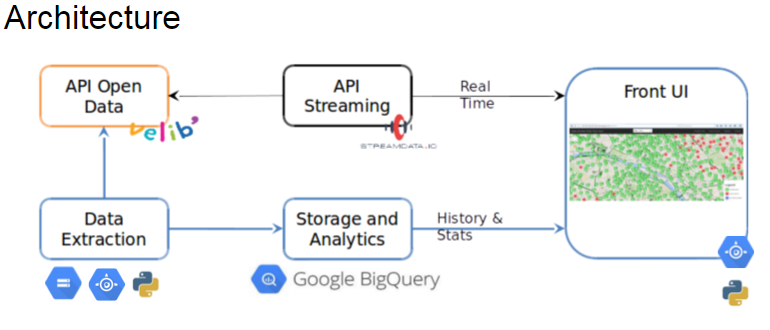
Un des premiers axes d’amélioration a consisté à réduire la consommation stockage et mémoire nécessaires au fonctionnement de cette tâche. Le calibrage optimal de l’instance en fonction de la charge de travail apporté (type d’instance, option de performance, etc.) a permis de répondre à cette problématique, ainsi qu’une optimisation du code et une refonte dans l’extraction des données.
BigQuery pour l’analyse des données
BigQuery est une solution très puissante pour l’analyse d’un grand volume de données, car il est basé sur un stockage colonne tout en permettant d’utiliser des requêtes complexes. Nous avions cependant des problématiques de temps de réponse, certaines requêtes pouvant avoir un temps d’exécution de plus de 10 secondes, mais aussi à cause du volume renvoyé au navigateur qui ralentissait l’affichage des pages.
Sachant que BigQuery lit toutes les lignes d’une colonne lors d’une requête, nous avions déjà opté pour une table par jour. L’étape suivante a donc été d’optimiser les requêtes au niveau du volume pour utiliser le strict nécessaire (une opération plutôt simple dans la mesure où BigQuery a une syntaxe très similaire à celle de SQL) et d’optimiser le lancement d’une même requête à plusieurs reprises. Ce travail a aussi pour but de limiter les coûts car BigQuery est facturé en fonction du volume analysé à chaque requête (plusieurs Go par jour dans notre cas). Ce travail nous a permis de bénéficier de MemCache sans aucune modification de code dans l’application web car MemCache est pris en charge nativement dans App Engine. La même logique a été appliquée dans la partie statistique de l’application.
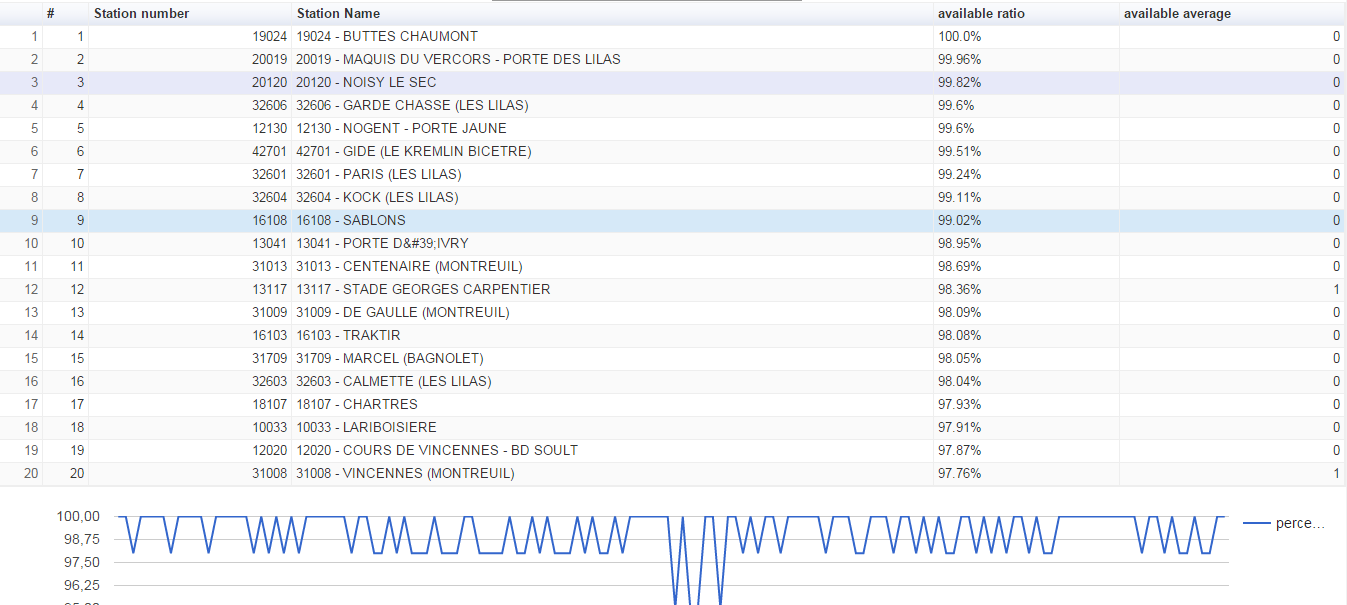
Voici un extrait des stations Vélib’ les plus utilisées le 29/12/15 à 17H00 avec le taux d’utilisation de la station SABLONS durant la journée :
Retour d’expérience
Dans le cadre de ce projet OpenData, l’utilisation du Cloud (ici, Google Cloud Platform) a permis un vrai gain de temps en termes de développement et de mise en place d’infrastructure. Toute la partie infrastructure, stockage et analyse de données étant fournie de façon managée, nous avons pu nous concentrer sur l’essentiel : la structuration de l’application et l’optimisation du développement. Cependant, si Google Cloud Platform semble une solution puissante, complète et simple d’utilisation, le chemin à parcourir pour faire le tour de ses services est encore long.
Article réalisé en collaboration avec Cyrielle Camanes
Vous souhaitez expérimenter sur Google Cloud Platform et manipuler les données Velib’ ? Rejoignez-nous lors de notre prochain Crash Course :

Commentaires :
A lire également sur le sujet :




