
Kafka, le système de message distribué à haut débit (3/3)

Message Broker permettant de répondre à la problématique de traitement de flux volumineux de données en temps réel, Apache Kafka est utilisé par des sociétés comme LinkedIn, Twitter, Spotify et Netflix. Ce système de publish-suscribe-messaging est rapide, durable et distribué. Après avoir traité de ses principes généraux et de ses avantages concurrentiels, nous abordons aujourd’hui la partie pratique, avec l’installation d’un broker et l’interaction avec un cluster.
Installation et mise en place basique avec un broker
Dans ce tutoriel d’utilisation d’un cluster Apache Kafka, nous commencerons par installer un broker. Pour ce faire, nous utiliserons la dernière version stable sortie, la version 0.8.2.2. En fonction de vos préférences de téléchargement, nous allons sélectionner la version recommandée utilisant Scala 2.0. Pré-requis : avoir Java JRE installé.
apt-get install default-jre
Téléchargement de la version 8.2.1 utilisant la version 2.10 de Scala via le protocole HTTP :
wget http://apache.crihan.fr/dist/kafka/0.8.2.1/kafka_2.11-0.8.2.1.tgz
tar –xvzf kafka_2.11-0.8.2.1.tgz
rm kafka_2.11-0.8.2.1.tgz
cd kafka_2.11-0.8.2.1
Décrivons maintenant brièvement les différents sous-dossiers :
![]()
Bin : Contenant les scripts permettant le lancement d’un cluster Apache Kafka, l’interaction avec celui-ci et le test.
Config : Fichiers de configuration utilisés au lancement de certains scripts. Il faut voir ces fichiers comme des exemples sur lequel se baser, ou bien modifier.
Libs : L’ensemble de librairies utilisées. Nous n’aborderons pas cette partie.
Découvrons ensemble rapidement les propriétés de nos serveurs Kafka ainsi que de notre zookeeper préconfiguré dans les fichiers se situant dans le dossier config.
Zookeeper.properties

Le fichier de configuration est extrêmement simple. Deux options : l’une pour indiquer le port et l’autre pour le nombre maximum de connexions client.
Server.properties
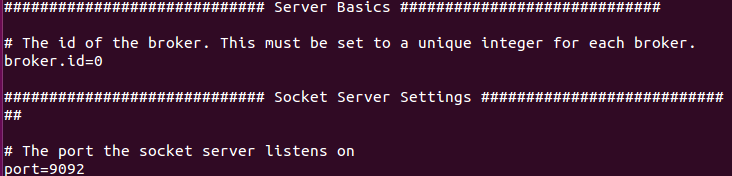
Ce fichier de configuration est bien plus long et dispose d’options avancées que nous ne verrons pas ici, mais que vous pouvez retrouver dans la documentation.
L’ID du broker ainsi que son port nous seront utiles pour la suite.
Note : Si votre zookeeper n’est pas en localhost, n’oubliez pas de modifier le fichier de configuration du broker.
Mise en place du premier broker
Il est temps de se lancer et de mettre en place le premier broker. Pour ce faire, nous devons au préalable mettre en place notre zookeeper :
bin/zookeeper-server-start.sh config/zookeeper.properties
![]()
Puis notre broker avec la configuration précédente :
bin/kafka-server-start.sh config/server.properties
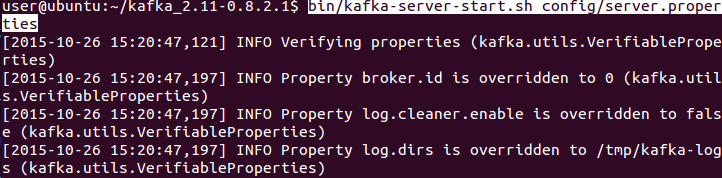
Nous pouvons voir que notre zookeeper à identifié la connexion entrante du broker :

Pour récapituler, nous avons donc :
- 1 Zookeeper :
- Port : 2181
- 1 Broker Apache Kafka :
- Port : 9092
- ID : 0
- Directory logs : /tmp/kafka-logs
Ici nous travaillerons uniquement sur la même machine, soit localhost. Il faudra donc ajuster vos configurations si vous effectuez l’opération sur plusieurs brokers en réseau.
Interaction avec le Broker
Maintenant que nous avons mis en place notre premier broker, nous allons pouvoir interagir avec. Pour des raisons de simplicité et de test, nous allons utiliser les scripts situés dans le dossier Bin pour :
- La création d’un topic
- La publication d’un message via un producer
- La récupération d’un message via un consumer
Commençons donc par créer notre topic, qui sera nommé D2SI, et qui aura comme facteur de réplication 1 (lui-même en interne) et une partition :
bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic D2SI
Note : Nous avons indiqué ici « localhost :2181 » pour le zookeeper car celui-ci est en localhost et que le port, dans le fichier properties, est 2181.
Listons ensemble la liste des topics pour voir si celui-ci a bien été créer :
bin/kafka-topics.sh –list –zookeeper localhost:2181

Parfait ! Notre topic D2SI à bien été créé. Passons maintenant à la création de quelques messages qui pourront alimenter notre topic via le script producer fourni.
bin/kafka-console-producer.sh –broker-list localhost:9092 –topic D2SI

Tapez les messages que vous souhaitez durant ce test.
Maintenant que nos messages sont inscrits dans le topic D2SI, nous allons récupérer ces messages simplement en indiquant qu’on souhaite récupérer tous les messages du début :
bin/kafka-console-consumer.sh –zookeeper localhost:2181 –topic D2SI –from-beginning

La première étape est terminée. Vous pouvez taper de nouveaux messages avec votre producer et voir le résultat en temps réel du côté de votre consumer.
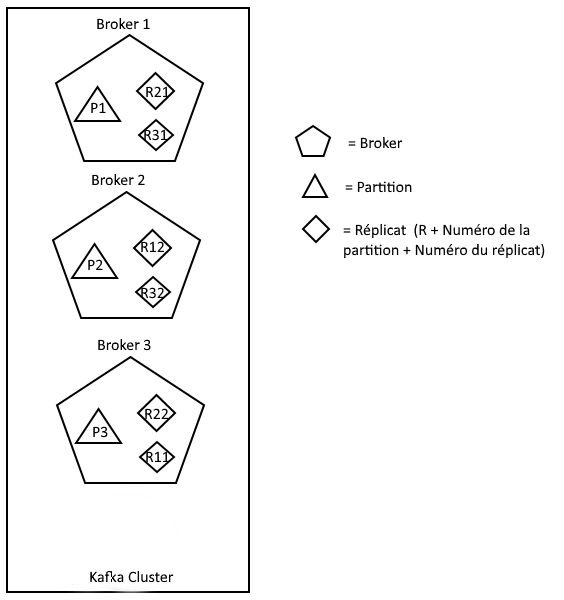
Mise en place d’un cluster
Nous allons passer à l’étape supérieure et mettre en place un cluster Apache Kafka. Nous nous baserons sur l’infrastructure du cluster vu dans l’article précédent, représenté ci-dessous :
Pour ce faire, nous allons nous baser sur le fichier de properties du serveur apache Kafka utilisé précédemment :
cp config/server.properties config/server-2.properties
cp config/server.properties config/server-3.properties
Nous allons donc remplacer, dans les fichiers de configuration, les parties suivantes pour éviter tout conflit:
- ID : Doit être unique car celui-ci identifie le broker dans le cluster
- Port : Doit être unique pour éviter les conflits de port
- Dir : Nous allons indiquer un nouveau chemin pour éviter les conflits d’écriture.
Voici un exemple de configuration pour le fichier config/server-2.properties


Lançons donc ces deux nouveaux serveurs en background :
bin/kafka-server-start.sh config/server-2.properties &
bin/kafka-server-start.sh config/server-3.properties &
![]()
Interaction avec le cluster
Construisons un nouveau topic qui s’appellera D2SI-replicated. Comme vous l’aurez compris, nous allons créer un topic avec 3 partitions et un facteur de réplication à 3 :
bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 3 –partitions 3 –topic D2SI-replicated
Vérifions maintenant si le topic à bien été créé :
bin/kafka-topics.sh –describe –zookeeper localhost:2181 –topic D2SI-replicated

Notre topic a bien été créé cependant, comme nous pouvons le voir, la configuration est légèrement différente de notre schéma. Dans un premier temps, essayons de comprendre ensemble la configuration.
Nous pouvons voir que notre Topic D2SI-replicated contient 3 partitions avec chacune son propre ID (0, 1 et 2). Chaque partition se voit associer un leader représenté par l’ID du broker. De l’autre côté nous avons la liste des réplicas, sans prendre en compte le fait qu’ils soient leader ou actif. Enfin, « Isr » signifiant « In synchronisation » montrant les réplicas actuellement actifs et communicant avec le leader.
Comme nous pouvons le voir, notre configuration ne varie pas réellement de ce qui était prévu. La liste des réplicas peut prendre en compte le leader et le Isr en va de même. Nous obtenons donc le même résultat attendu.
Il est intéressant de noter que la liste Replicas représente la liste des successeurs en cas de panne du leader. Prenons la partition 0 avec comme leader le broker ID 1 : si le leader tombe alors le broker ID 2 qui reprendra le lead. Nous étudierons un exemple de panne par la suite.
Passons à l’interaction avec notre cluster apache Kafka. Dans la même logique que dans la partie précédente, nous allons utiliser les scripts fournit de producer et consumer :
bin/kafka-console-producer.sh –broker-list localhost:9092 –topic D2SI-replicated

Ici notre producer envoie deux messages : « Penguin is » et « Back ! ». Vérifions l’échange en consultant, via notre consumer, les messages :
bin/kafka-console-consumer.sh –zookeeper localhost:2181 –from-beginning –topic D2SI-replicated
![]()
Comme nous pouvons le voir l’échange s’est bien déroulé ! Voilà qui conclut cette session d’installation et d’interaction avec un cluster. Dans un prochain article, nous passerons à une mise en application pratique avec Logstash.
Commentaires :
A lire également sur le sujet :




