
Kafka, le système de message distribué à haut débit (2/3)

Comme nous l’avons vu dans un article précédent, Kafka est un message broker permettant de répondre à la problématique des traitements de flux de données en temps réel. Aujourd’hui, nous allons voir en détail ce qui fait la force de Kafka et ce qui le différencie des autres messages brokers.
Un système partitionné mais durable
Kafka est un système de « publish-subscribe-messaging » destiné à être rapide, durable et distribué. Il est différent de ses prédécesseurs en cela qu’il ne stocke pas ces messages en RAM mais plutôt sur le disque dur. Cependant, toutes les écritures vont essentiellement s’inscrire dans le cache disque de l’OS (en RAM). Est-ce que cela cause des problèmes de performance ? Pas vraiment, c’est surtout une question de configuration, mais c’est un point que nous n’aborderons pas ici (pour plus d’informations, consultez ce lien).
Ce système lui permet de stocker une grande quantité d’information tout en restant durable. En effet, Kafka ne supprime pas ces messages, mais les conserve. Ainsi, tout nouveau producer (voir article précédent) peut récupérer soit tous les messages à partir du début ou seulement les futurs messages à venir.
Enfin, le fait de pouvoir stocker les données sur un disque dur est une mesure de sécurité de la conservation des données intéressante. C’est plutôt utile si vous souhaitez redémarrer Kafka ou le serveur rapidement en cas de problème. A noter cependant, une politique de rétention des messages peut être mise en place pour retirer les messages considérés comme anciens (par exemple, supprimer tous les messages dépassant les 24h de conservation).
Les partitions
Chaque topic se voit associé une à plusieurs partitions qui sont définies et répliquées lors de la création de celui-ci. Chaque partition contient une séquence de message, avec un ID séquentiel, ordonné et immuable commençant du plus ancien au plus récent. Le bénéfice est double : côté lecture et côté écriture.
Côté lecture : comme chaque message est identifié par un ID séquentiel, le consumer a juste besoin de l’ID du message. Plus précisément du côté consumer, l’ID d’un message courant est appelé offset. L’offset est contrôlé par le consumer, lui laissant une grande flexibilité sur sa navigation des messages. Ainsi, commencer au message le plus ancien comme au plus récent n’est pas un problème.
Sachant que l’accès à un message se fait directement via ce système d’offset, la lecture est extrêmement rapide. Enfin, lors de l’envoi d’un message, aucune copie n’est faite.
Côté écriture : l’écriture est assez rapide, puisque l’essentiel des messages est inscrit dans le cache disque de l’OS (en RAM). De plus, chaque partition permet de pouvoir effectuer une écriture en parallèle sur l’ensemble. Enfin, globalement, les performances sont accrues grâce aux partitions : chaque partition peut faire l’objet d’un broker. Ces performances peuvent s’appliquer en écriture comme en lecture.
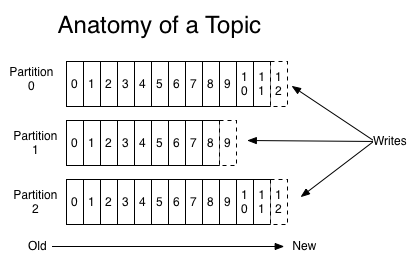
Système d’écriture au sein d’un topic comportant 3 partitions
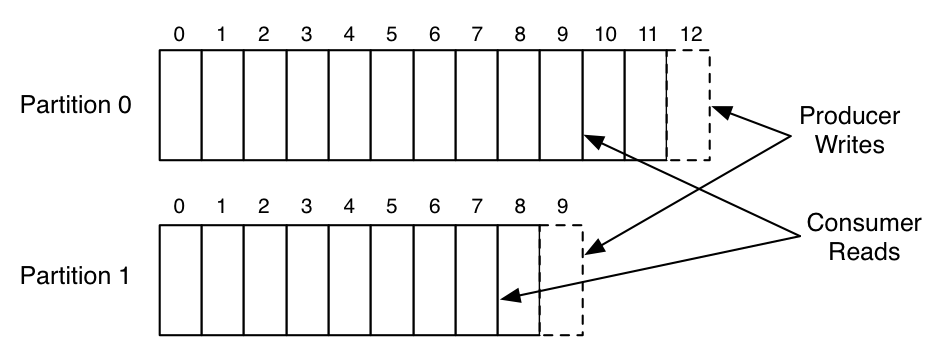
Ecriture et lecture d’un topic en parallèle sur 2 partitions
Un système distribué et scalable
Comme nous l’avons vue, Kafka est une solution offrant rapidité, flexibilité et surtout la garantie de l’intégrité de nos données. Mais cette solution a le don d’être scalable et donc d’accroître ses performances quand celle-ci dispose d’un plus grand nombre de brokers.
Topics, partitions, réplicas et distribution
Au sein de notre cluster rempli de brokers, nous avons un coordinateur : Le zookeeper. Le rôle de celui-ci est de pouvoir gérer globalement la coordination des brokers mais aussi le partage d’information. Pour prendre un exemple, les consumers se servent du zookeeper pour naviguer, au travers des messages, avec leurs offsets. Le zookeper étant une solution indépendante de Kafka, elle ne sera pas traitée ici en détail (voir ici).
Comme nous l’avons vue précédemment, un cluster peut contenir plusieurs brokers et un zookeeper. Chaque partition/réplica appartient à un seul broker.
Le fait de pouvoir avoir plusieurs partitions permet un gain de performance et rapidité (écriture et lecture en parallèle). Cependant, le nombre de partition est limité par le nombre maximum de consumers.
Concernant le réplica, celui-ci est une « partition de sauvegarde ».
Prenons un exemple : Nous avons 1 cluster Kafka avec 3 brokers. De l’autre côté, 1 topic avec 3 partitions et un facteur de réplication de 3. Ici, le zookeeper n’est pas pris en compte cependant, il fait bien partie du cluster.
Sachant que nous avons 3 partitions avec un facteur de réplication de 3, le nombre de réplica est de 2*3 = 6 (2 partitions de réplicas plus une partition principale) . Ainsi, les brokers vont se partager de façon uniforme ces réplicas entre eux, et de façon à être « fault tolerance » (pas de réplicas équivalent dans le même broker). Ici nous avons une « fault tolerance » de 2 : deux brokers peuvent tomber.
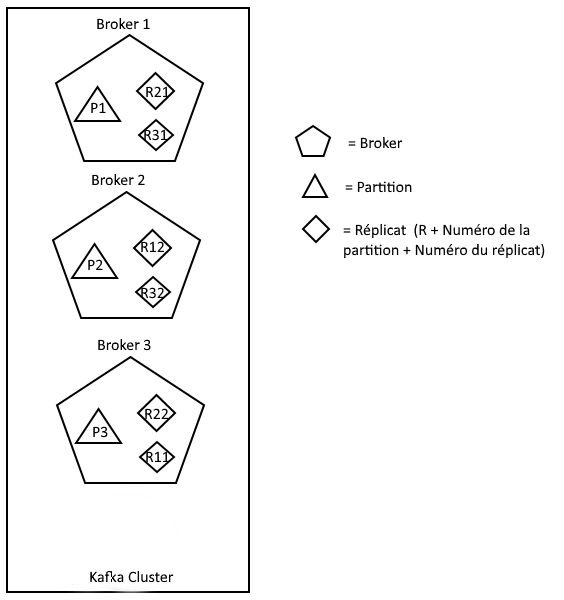
Comme nous pouvons le voir, le broker 1 possède la partition numéro 1 qui est répliquée dans le broker 2 (R12) et le broker 3 (R11). La même logique s’applique pour les brokers qui suivent. Ainsi, si le broker 1 est en panne, la partition numéro 1 est indisponible mais les réplicas sur le broker 2 (R12) et 3 (R11) sont encore disponible et donc le topic encore accessible.
Pour ce qui est des consumers, il est intéressant de pouvoir avoir plusieurs partitions. En effet, il est possible de former un groupe de consumers et ainsi permettre d’accroître la fault tolérance ainsi que la scalabilité. Cela permet d’obtenir des consumers liés à certaines partitions de façon équitable.
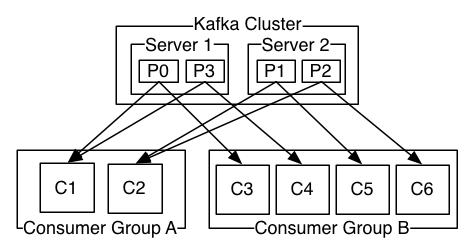
Cluster et scalabilité
De l’autre côté, nous avons notre cluster Kafka. Avant de pouvoir décortiquer les propriétés du cluster, il faut savoir que chaque broker est identifié par un ID unique devant être un nombre et pouvant être modifié dans les fichiers de configuration. La particularité de ce cluster est d’être scalable rapidement et facilement. En effet, ajouter un broker est simple et rapide dans un cluster. Cependant, dans la version actuelle, il est assez rigide d’associer un nouveau broker à un topic déjà existant. La nouvelle répartition uniforme des partitions sur les différents brokers (ancien comme nouveau) doit s’effectuer manuellement malgré l’aide de quelques scripts. Ainsi, le nombre de brokers comme de partitions peut augmenter considérablement le temps de réorganisation suite à l’intégration d’un nouveau broker.
Bien évidemment, Kafka étant en cours de développement, les futures versions permettront certainement de régler ce problème. En dehors de cette contrepartie, la répartition uniforme des partitions entre les brokers permet une meilleure répartition de la charge de travail et des données. De plus, ajouter de nouveaux topics ou reconfigurer les topics reste assez simple sans compter sur l’aide d’applications de management de test et de configuration.
Revenons un peu plus en détail sur les brokers, partitions et réplicas au sein du cluster. Comme nous l’avons vu précédemment, une partition peut avoir un facteur de réplication (fortement recommandé) pour la fault tolérance. Chaque Broker se voit donc attribuer une partition avec comme rôle « leader ». Nous avons d’un côté le leader qui aura pour rôle de s’occuper des lectures et écriture au sein de la partition, et de l’autre côté, les « follower » qui s’occuperont de mettre à jour leurs réplicas en fonction des mises à jour envoyées par le leader. Il est important de noter qu’une compression est faite de bout en bout et que le protocole utilisé est léger.
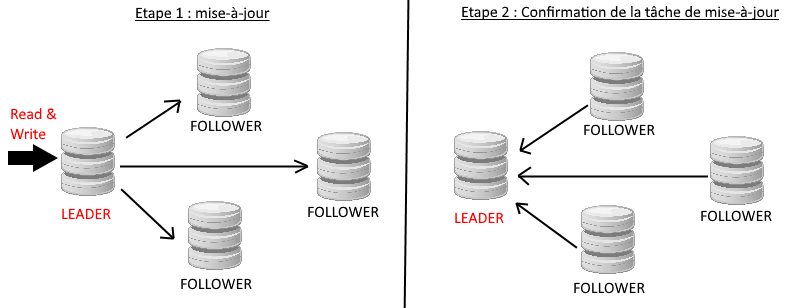
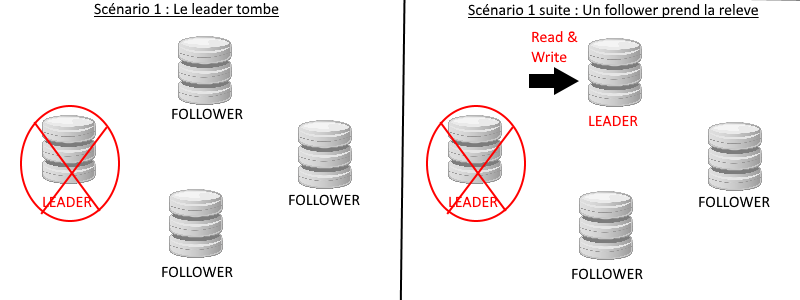
Prenons le scénario suivant : notre leader est dans l’incapacité de fonctionner. Que se passe-t-il ?
Le leader est détecté comme corrompu ou inopérant, un vote est lancé sur le cluster pour déterminer qui sera le nouveau leader, un follower prend le rôle de leader et se verra attribuer le droits d’écriture et lecture ainsi que la distribution des mise-à-jour de la partition. Ceci illustre bien l’importance des réplicas.
Sécurité
Du point de vue de la sécurité, le cluster Kafka ne comporte actuellement pas de fonction spécifique à la sécurité. Cependant, le sujet est en cours de discussion depuis 2014 : sécurité sur la couche transport, chiffrement des données, etc. Pour suivre l’évolution des fonctions de sécurité de Kafka, c’est par ici.
Benchmark
Quelles sont les autres solutions sur le marché ? Cet article propose une comparaison de différents produits : Amazon SQS, Mongo DB, RabbitMq, HornetQ et Kafka.
Dans un prochain article, nous passerons à la pratique : le déploiement et l’intégration d’un cluster Kafka.
Commentaires :
A lire également sur le sujet :




