
Kafka, le système de message distribué à haut débit (1/3)

L’évolution rapide du trafic sur Internet (élargissement, complexité, vitesse, etc.) a multiplié les problématiques concernant le trafic de données, et notamment le traitement des flux de données en temps réel, comme les messages, logs, ou vidéos. Comment traiter en temps réel des entrées de près de 13 millions de messages par seconde ? Kafka est un broker qui permet de répondre à cette problématique.
Dans ce premier article d’une série qui en comptera trois, nous allons voir ce qu’est Kafka et comment ce système fonctionne. Projet open source sous licence Apache 2.0, Kafka a initialement été développé par LinkedIn, en Scala, en 2011. Le projet est actuellement en version 0.8.2.1 depuis mai 2015. Kafka est un système de « publish-subscribe messaging » distribué, partitionné et répliqué avec un design unique plutôt orienté sur les logs. Ses principaux champs d’action peuvent englober aussi bien les agrégations de logs, le traitement en temps réel et le monitoring.
Kafka a su convaincre de grandes entreprises grâce à ses fonctionnalités, mais surtout ses performances. Parmi ceux qui ont adopté Kafka, citons :
- LinkedIn (auteur de la technologie) utilise Kafka pour gérer ses flux d’activité et de suivi d’indicateurs opérationnels. Quelques chiffres : 1100 brokers Kafka, 650 tera de messages/jour.
- Twitter : Kafka est utilisé comme composant de leurs infrastructures Storm de temps réel.
- Spotify : utilisé comme une partie de leur système d’envois de logs.
- Netflix, Pinterest, Uber, Mozilla, Cisco…(liste complète des entreprises utilisant Kafka)
Le principe des systèmes de publish-suscribe-messaging
Avant d’approfondir Kafka, revenons sur le principe d’un système de publish-subscribe messaging pour mieux comprendre les fondamentaux liés à Kafka.
Ce type de système a pour but de conserver les messages de façon temporaire (comme pour un système de Queuing) permettant de garantir, lors de forts pics de charge, l’intégrité du message. Dans certains systèmes, lors de brusques pics d’activité, il arrive que des messages soient perdus : le processus de traitement de l’information ne suit pas ce flux d’activité, accumule de nombreux messages en mémoire, et force le processus a libérer cette mémoire à l’approche d’un seuil critique.
Ainsi, dans notre contexte, ce système se place entre le processus qui récupère l’information et le processus qui traite l’information (processus plus lent).
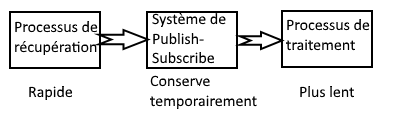
Ainsi, lors d’une montée en charge, les données seront conservées le temps que les processus puisse traiter toutes les données.
Terminologie des systèmes de publish-suscribe-messaging
Pour bien comprendre comment fonctionne Kafka, nous devons aborder quelques notions de terminologie liées aux systèmes de publish-suscribe-messaging.
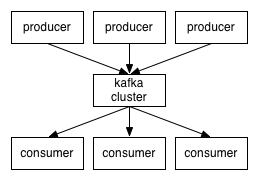
- Au centre le Broker : tout simplement un serveur Kafka (nœud). Un ensemble de Broker Kafka est appelé un Cluster Kafka.
- Les Producers représentent les processus de saisie de l’information sur les sources (Logs, IRC, Twitter, …) et se chargent de les mettre dans le cluster Kafka.
- Les Consumers : les processus qui récupèrent l’information contenue dans le cluster Kafka.
- Les Topics : Chaque message est associé à un Topic. On peut voir ce système comme les forums, où chaque Topic (sujet) contient un ou plusieurs messages.
Voilà pour le contexte global de Kafka et des systèmes de publish-suscribe-messaging. Dans un prochain article, nous aborderons le sujet de façon beaucoup plus détaillée : le fonctionnement de Kafka, ses points forts, et ses axes d’amélioration.
A consulter également sur le sujet :
Comparaison des systèmes de « message queue »
Commentaires :
A lire également sur le sujet :




