Solutions Big Data : comment valoriser vos données ?

D’après une étude du magazine Fortune, du début de l’histoire de l’informatique jusqu’en 2003, nous avons généré 5 exabites de données (soit 5 milliards de GB). Sur la seule année 2011, nous avons généré un volume équivalent de données. En 2013, on estime qu’environ 5 exabites sont créées toutes les dix minutes. Cette explosion du volume de données a ouvert la voie à un nouveau métier de l’IT, le Big Data.

Guillaume Aymé
Pour évoquer ce sujet et ses implications pour l’entreprise et ses métiers, nous recevons aujourd’hui Guillaume Aymé, Pre-sales Manager chez Splunk. Splunk est une solution Big Data permettant d’analyser tout type de données…jusqu’à 300 tera/jour !
Les équipes de Splunk animeront ce mercredi 28 janvier chez D2SI une soirée Splunk Kickstarter, un premier module de formation pratique sous forme de hands-on.
Qu’est-ce que le Big Data et quel est son apport pour l’entreprise ?
Aujourd’hui le Big Data fait référence à l’explosion du volume de données et aux moyens donnés à l’entreprise pour les traiter. Mais l’exploitation et le traitement des données machine (machine data) existe depuis près de 10 ans : nous avons commencé à faire du Big Data avant que le terme existe. Traiter et centraliser ces données génère énormément de valeur pour les équipes informatiques : elles donnent de la visibilité, aident à la résolution des problèmes (troubleshooting), permettent de comprendre les services rendus aux clients ou aux équipes métier.
Quelle est la maturité du marché sur le sujet ?
Pour beaucoup de clients le Big Data est encore relativement récent. Ils sont à la recherche d’un éco-système permettant de lancer un projet Big Data, mais sans forcément savoir ce qu’ils vont en retirer. Le problème du Big data est qu’il demande beaucoup de ressources en développement : toutes les entreprises n’ont pas la puissance de développement d’un Facebook ou Google pour développer une solution en interne ou en agrégeant différents outils opensource. Qu’en est-il pour les entreprises dont le coeur de métier n’est pas l’IT et qui ne disposent pas de ces ressources ?
En quoi Splunk répond à cette problématique ?
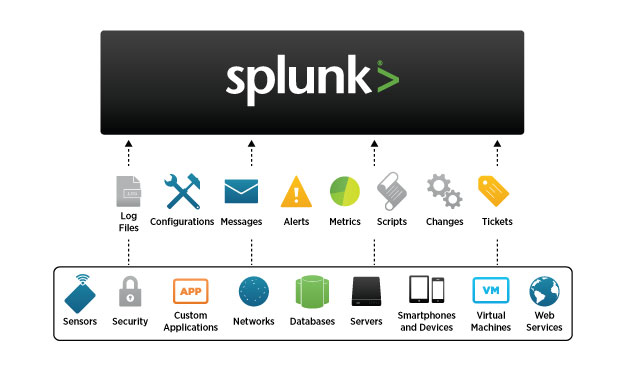
Splunk est une solution “Big Data for all” : un seul outil pour agréger toutes les données machines sans nécessiter de fortes compétences techniques. Se lancer dans le développement (long) d’une plateforme, c’est prendre le risque qu’elle ne réponde pas à l’évolution des besoins et aux questions qu’on se pose dans 6 mois. L’accélération des cycles fait que tout évolue très vite : il faut pouvoir traiter la donnée dès maintenant pour savoir rapidement si elle est pertinente. Splunk permet de répondre à ce besoin de façon immédiate.
L’apport de la donnée est-il évident ?
L’un des principes du big data est qu’on ne sait pas par avance ce que la donnée va apporter. La seule façon de le savoir est de commencer à traiter ces données et de voir comment elles peuvent répondre à des problématiques métier. S’il faut pour cela développer une plateforme, investir beaucoup d’argent avant de savoir si la donnée qui sera traitée va apporter de la valeur…on perd du temps et de l’argent. L’objectif est d’avoir une plateforme très rapidement, sans investir en amont, pour avoir des réponses rapidement : Splunk est un point d’entrée rapide dans le big data, qu’il est ensuite possible d’enrichir en fonction de ses besoins.
Concrètement, comment ça se passe ?
Au départ, il s’agit de centraliser la donnée, la traiter pour rapidement enquêter : c’est un format brut, mais qui apporte déjà beaucoup de valeur. Ensuite, on peut corréler les données en temps réel, les visualiser…et petit à petit évoluer vers un modèle plus mature. Par exemple, on commence sur l’IT et la corrélation des logs système (vmware, citrix, firewall, cisco, réseau, stockage, etc…)…pour répondre ainsi aux premiers besoins de l’entreprise.
Mais aujourd’hui les données proviennent de n’importe où, et pas seulement de l’entreprise : capteurs dans les centres commerciaux, les ascenseurs, les avions…cela représente une myriade de data à aller chercher. C’est pour ça que nous travaillons de plus en plus avec les métiers, en plus de l’IT. Prenons l’exemple d’un client dans la grande distribution : nous avons à disposition son mail, son numéro de téléphone…et parfois sa localisation en direct. Toutes ces données sont extérieures à l’entreprise : or, ce numéro de téléphone correspond à une carte de fidélité du supermarché… A partir de là, de nombreuses analyses sont possibles. Beaucoup de clients ne savent pas quoi faire de prime abord d’une telle masse de données.
Qu’est ce que l’intelligence opérationnelle ?
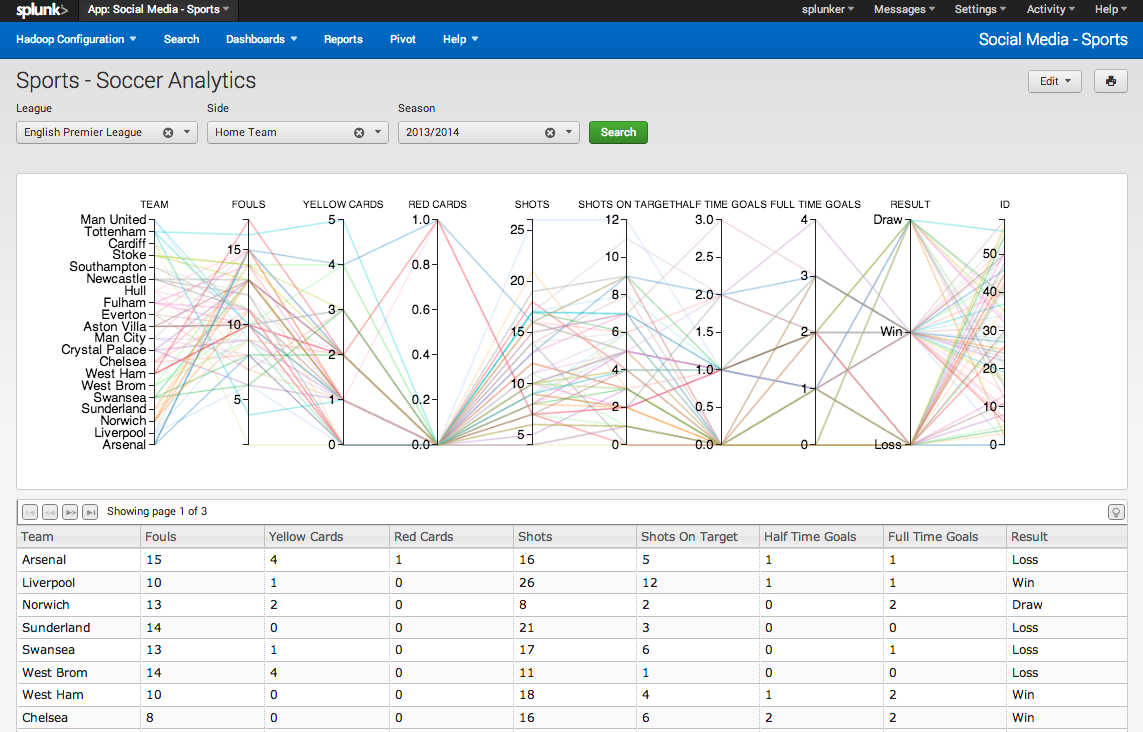
En Big Data, on parle des 3V : le volume, la vélocité et la variété des données. Ces 3V donnent une représentation de l’entreprise en temps réel : c’est une nouvelle génération de business intelligence. Traditionnellement, la business intelligence suppose d’exploiter des données qui ont été structurées, agrégées, mises dans un datawarehouse selon un schéma pré-établi. On a hypothétisé, pré-évalué les questions à se poser sur ces données. Splunk permet d’exploiter les données brutes pour répondre très rapidement à de nouvelles questions, en temps réel, par opposition à l’approche statique et pré-calculée de la business intelligence. C’est cela l’intelligence opérationnelle et c’est aussi ce qui permet un rapprochement entre les équipes informatiques et le métier, demandeur d’une analyse plus fine des données.
Le Big Data répond aussi aux nouveaux enjeux du DevOps ?
Comme les cycles sont de plus en plus courts, on développe et on livre en continu. Les développeurs ont besoin de savoir exactement comment les clients utilisent les services qu’ils viennent de développer. Après avoir livré un service en continous delivery, il faut savoir comment est utilisé ce service en temps réel.
Peux-tu nous présenter des cas d’usage de Splunk ?
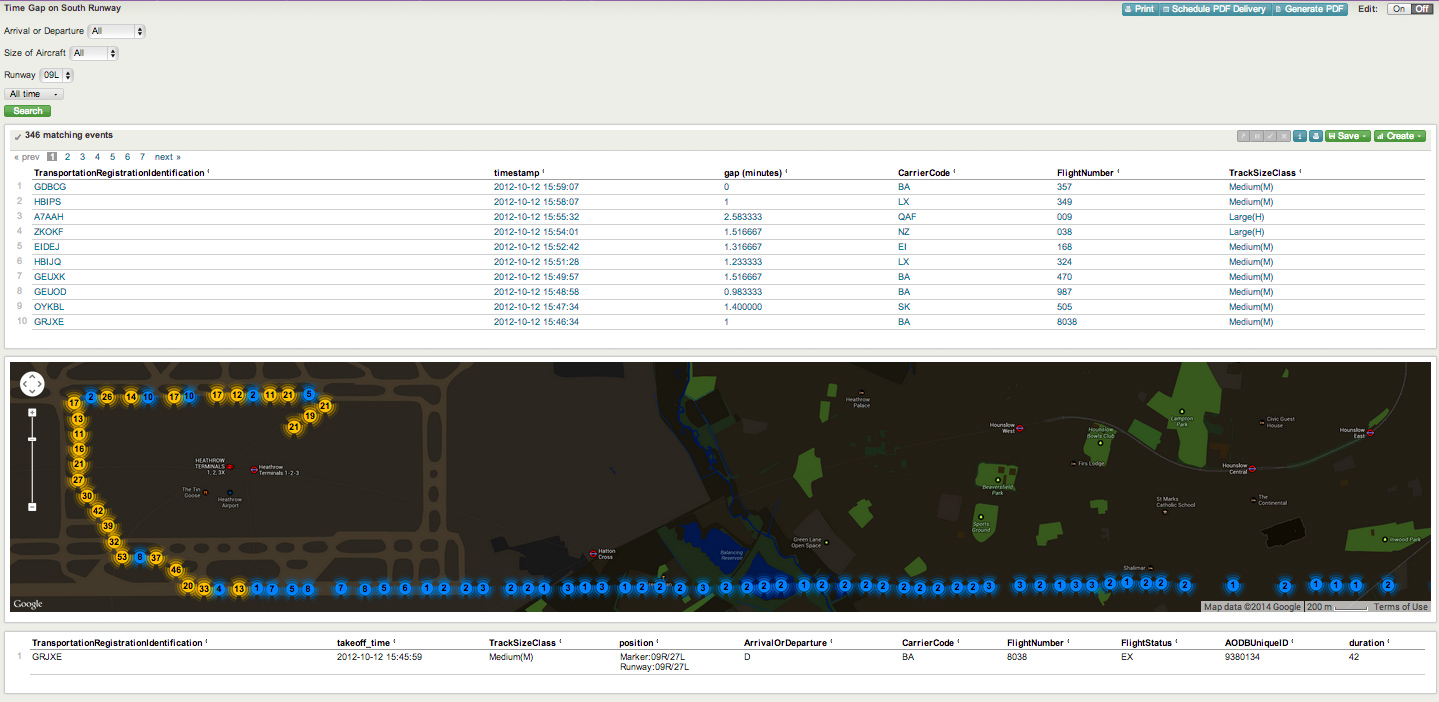
Prenons un aéroport international : l’application gérant la tour de contrôle loggue de nombreuses données machine. Ce type d’application est critique : quand il y a un souci, les équipes informatiques doivent pouvoir rentrer très rapidement dans les données machines et les logs pour identifier l’origine du problème. Parmi les nombreuses données que l’on retire l’application, nous avons aussi les coordonnées des avions. Pour les équipes opérationnelles de l’aéroport, ce sont des informations précieuses.
Géolocaliser chaque avion, pouvoir rejouer son parcours, calculer les écarts entre chaque avion permet d’optimiser les temps de passage sur la piste tout autant que d’assurer le respect des distances de sécurité. Il est aussi possible de déterminer si un type d’avion, une compagnie ou un pilote en particulier passe plus de temps sur la piste. Un seul mauvais comportement peut impacter tout le planning de la journée de l’aéroport, qui doit ensuite payer des pénalités aux compagnies lésées par le retard.
Quels sont les usages dans le e-commerce ?
Pour la distribution il est difficile de comprendre le comportement de ses clients : il est dynamique, il change très souvent. On parle d’omni-channel : le consommateur recherche un produit sur son laptop, cherche de l’information complémentaire plus tard sur son mobile, passe voir le produit en boutique avant de l’acheter sur place, ou le commander en ligne. Le Big Data permet d’exploiter toutes les informations issues de ces différents canaux : mobile, capteurs en boutique, tickets de caisse…Splunk est au coeur du système et permet de suivre le parcours d’activité des clients e-commerce en multi-channel. Nous travaillons par exemple avec un grand acteur de la grande distribution pour corréler leurs données magasins et leur solution e-commerce : on peut attribuer l’achat d’ une TV dans un hyper au fait que le client a vu la promotion sur le site e-commerce.
Quel est l’objectif de la formation qui aura lieu chez D2SI le 28 janvier ?
De plus en plus de sociétés déplacent leurs applications dans le cloud ; il ne s’agit pas uniquement de développement, mais aussi de production. D2SI est l’un des précurseurs sur les sujets de l’automatisation, du continuous delivery et du cloud. Nous avons beaucoup en commun : nos clients veulent aussi collecter les données de leurs applications dans le cloud. C’est une première étape pour former le mieux possible nos partenaires afin qu’ils soient autonomes sur la plateforme, et répondre aux problématiques de leurs clients avec Splunk. Nous partageons les valeurs de D2SI, et c’est une excellente occasion d’apporter la valeur ajoutée de Splunk aux clients de D2SI.
Prochaine formation Splunk à Paris le 29/10/2015

Commentaires :
A lire également sur le sujet :